 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShould I send this notification? Optimizing push notifications decision making by modeling the future
Feb 17, 2022Most recommender systems are myopic, that is they optimize based on the immediate response of the user. This may be misaligned with the true objective, such as creating long term user satisfaction. In this work we focus on mobile push notifications, where the long term effects of recommender system decisions can be particularly strong. For example, sending too many or irrelevant notifications may annoy a user and cause them to disable notifications. However, a myopic system will always choose to send a notification since negative effects occur in the future. This is typically mitigated using heuristics. However, heuristics can be hard to reason about or improve, require retuning each time the system is changed, and may be suboptimal. To counter these drawbacks, there is significant interest in recommender systems that optimize directly for long-term value (LTV). Here, we describe a method for maximising LTV by using model-based reinforcement learning (RL) to make decisions about whether to send push notifications. We model the effects of sending a notification on the user's future behavior. Much of the prior work applying RL to maximise LTV in recommender systems has focused on session-based optimization, while the time horizon for notification decision making in this work extends over several days. We test this approach in an A/B test on a major social network. We show that by optimizing decisions about push notifications we are able to send less notifications and obtain a higher open rate than the baseline system, while generating the same level of user engagement on the platform as the existing, heuristic-based, system.
Deep Bayesian Bandits: Exploring in Online Personalized Recommendations
Aug 03, 2020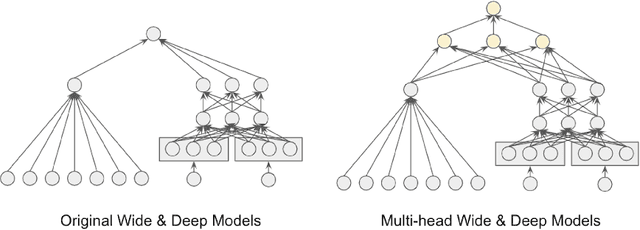
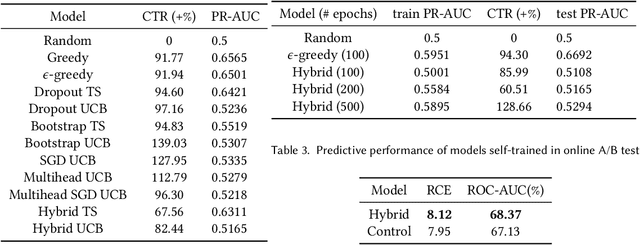
Recommender systems trained in a continuous learning fashion are plagued by the feedback loop problem, also known as algorithmic bias. This causes a newly trained model to act greedily and favor items that have already been engaged by users. This behavior is particularly harmful in personalised ads recommendations, as it can also cause new campaigns to remain unexplored. Exploration aims to address this limitation by providing new information about the environment, which encompasses user preference, and can lead to higher long-term reward. In this work, we formulate a display advertising recommender as a contextual bandit and implement exploration techniques that require sampling from the posterior distribution of click-through-rates in a computationally tractable manner. Traditional large-scale deep learning models do not provide uncertainty estimates by default. We approximate these uncertainty measurements of the predictions by employing a bootstrapped model with multiple heads and dropout units. We benchmark a number of different models in an offline simulation environment using a publicly available dataset of user-ads engagements. We test our proposed deep Bayesian bandits algorithm in the offline simulation and online AB setting with large-scale production traffic, where we demonstrate a positive gain of our exploration model.