 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Bayesian Bandits: Exploring in Online Personalized Recommendations
Aug 03, 2020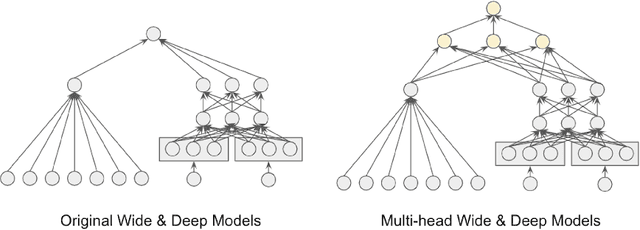
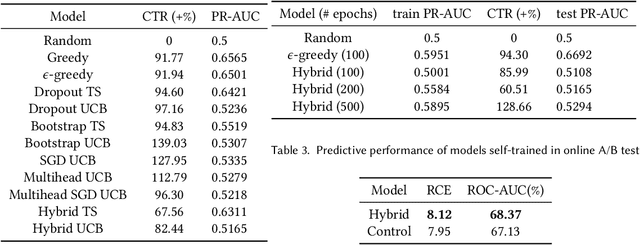
Recommender systems trained in a continuous learning fashion are plagued by the feedback loop problem, also known as algorithmic bias. This causes a newly trained model to act greedily and favor items that have already been engaged by users. This behavior is particularly harmful in personalised ads recommendations, as it can also cause new campaigns to remain unexplored. Exploration aims to address this limitation by providing new information about the environment, which encompasses user preference, and can lead to higher long-term reward. In this work, we formulate a display advertising recommender as a contextual bandit and implement exploration techniques that require sampling from the posterior distribution of click-through-rates in a computationally tractable manner. Traditional large-scale deep learning models do not provide uncertainty estimates by default. We approximate these uncertainty measurements of the predictions by employing a bootstrapped model with multiple heads and dropout units. We benchmark a number of different models in an offline simulation environment using a publicly available dataset of user-ads engagements. We test our proposed deep Bayesian bandits algorithm in the offline simulation and online AB setting with large-scale production traffic, where we demonstrate a positive gain of our exploration model.
Model Size Reduction Using Frequency Based Double Hashing for Recommender Systems
Jul 28, 2020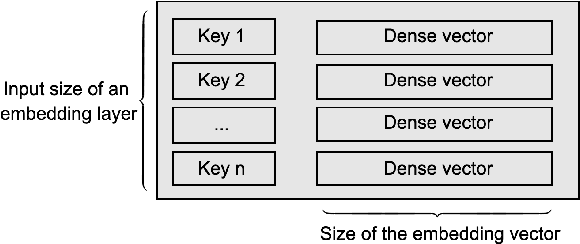
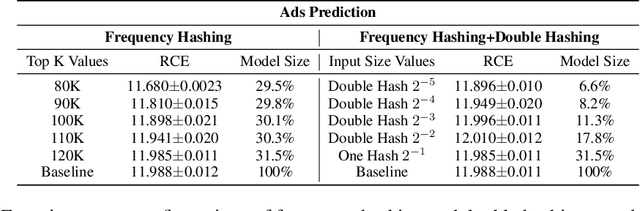
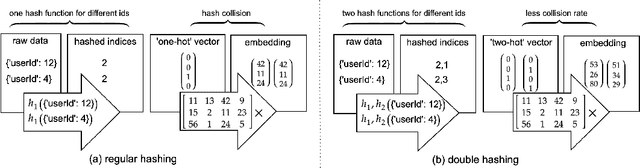
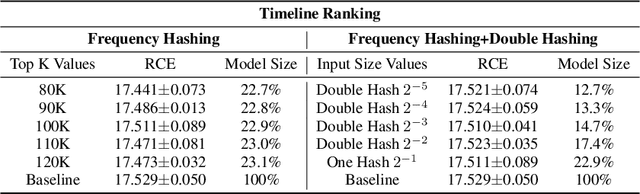
Deep Neural Networks (DNNs) with sparse input features have been widely used in recommender systems in industry. These models have large memory requirements and need a huge amount of training data. The large model size usually entails a cost, in the range of millions of dollars, for storage and communication with the inference services. In this paper, we propose a hybrid hashing method to combine frequency hashing and double hashing techniques for model size reduction, without compromising performance. We evaluate the proposed models on two product surfaces. In both cases, experiment results demonstrated that we can reduce the model size by around 90 % while keeping the performance on par with the original baselines.
Privacy-Preserving Recommender Systems Challenge on Twitter's Home Timeline
Apr 28, 2020
Recommender systems constitute the core engine of most social network platforms nowadays, aiming to maximize user satisfaction along with other key business objectives. Twitter is no exception. Despite the fact that Twitter data has been extensively used to understand socioeconomic and political phenomena and user behaviour, the implicit feedback provided by users on Tweets through their engagements on the Home Timeline has only been explored to a limited extent. At the same time, there is a lack of large-scale public social network datasets that would enable the scientific community to both benchmark and build more powerful and comprehensive models that tailor content to user interests. By releasing an original dataset of 160 million Tweets along with engagement information, Twitter aims to address exactly that. During this release, special attention is drawn on maintaining compliance with existing privacy laws. Apart from user privacy, this paper touches on the key challenges faced by researchers and professionals striving to predict user engagements. It further describes the key aspects of the RecSys 2020 Challenge that was organized by ACM RecSys in partnership with Twitter using this dataset.
PyTorch: An Imperative Style, High-Performance Deep Learning Library
Dec 03, 2019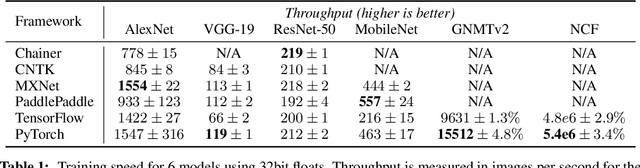

Deep learning frameworks have often focused on either usability or speed, but not both. PyTorch is a machine learning library that shows that these two goals are in fact compatible: it provides an imperative and Pythonic programming style that supports code as a model, makes debugging easy and is consistent with other popular scientific computing libraries, while remaining efficient and supporting hardware accelerators such as GPUs. In this paper, we detail the principles that drove the implementation of PyTorch and how they are reflected in its architecture. We emphasize that every aspect of PyTorch is a regular Python program under the full control of its user. We also explain how the careful and pragmatic implementation of the key components of its runtime enables them to work together to achieve compelling performance. We demonstrate the efficiency of individual subsystems, as well as the overall speed of PyTorch on several common benchmarks.
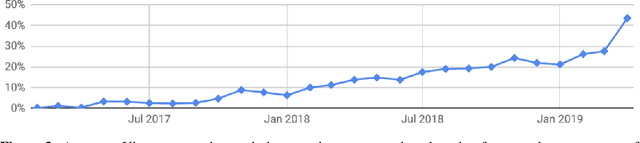
Addressing Delayed Feedback for Continuous Training with Neural Networks in CTR prediction
Jul 15, 2019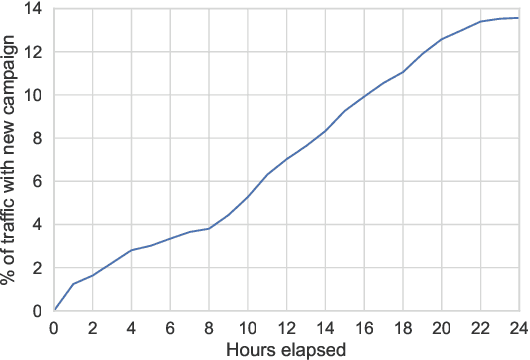
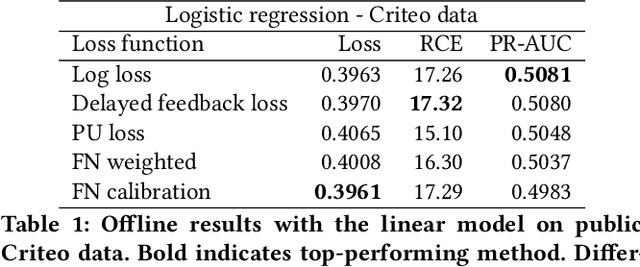
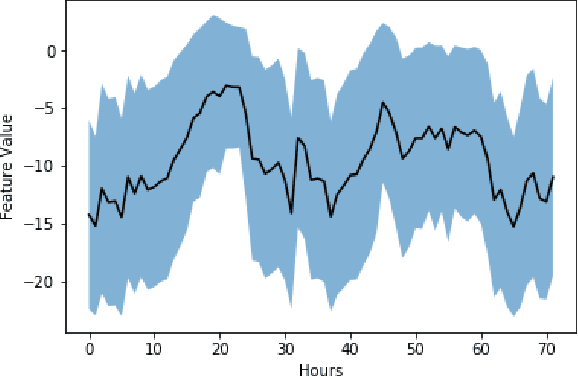
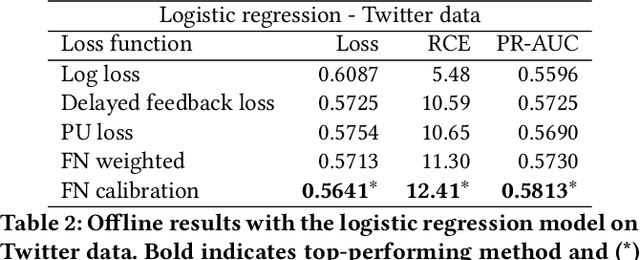
One of the challenges in display advertising is that the distribution of features and click through rate (CTR) can exhibit large shifts over time due to seasonality, changes to ad campaigns and other factors. The predominant strategy to keep up with these shifts is to train predictive models continuously, on fresh data, in order to prevent them from becoming stale. However, in many ad systems positive labels are only observed after a possibly long and random delay. These delayed labels pose a challenge to data freshness in continuous training: fresh data may not have complete label information at the time they are ingested by the training algorithm. Naive strategies which consider any data point a negative example until a positive label becomes available tend to underestimate CTR, resulting in inferior user experience and suboptimal performance for advertisers. The focus of this paper is to identify the best combination of loss functions and models that enable large-scale learning from a continuous stream of data in the presence of delayed labels. In this work, we compare 5 different loss functions, 3 of them applied to this problem for the first time. We benchmark their performance in offline settings on both public and proprietary datasets in conjunction with shallow and deep model architectures. We also discuss the engineering cost associated with implementing each loss function in a production environment. Finally, we carried out online experiments with the top performing methods, in order to validate their performance in a continuous training scheme. While training on 668 million in-house data points offline, our proposed methods outperform previous state-of-the-art by 3% relative cross entropy (RCE). During online experiments, we observed 55% gain in revenue per thousand requests (RPMq) against naive log loss.
Faster gaze prediction with dense networks and Fisher pruning
Jul 09, 2018
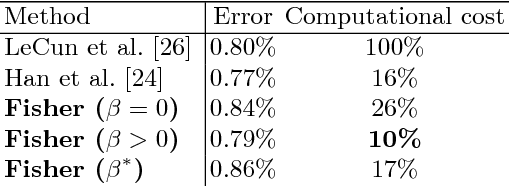

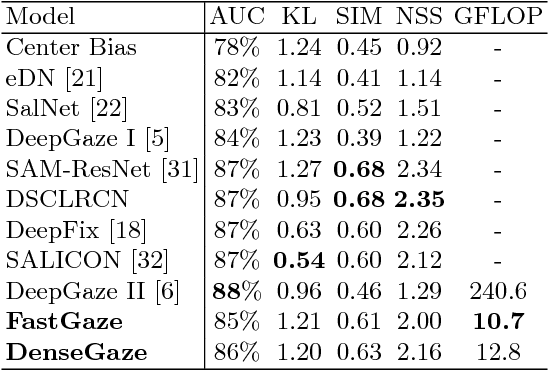
Predicting human fixations from images has recently seen large improvements by leveraging deep representations which were pretrained for object recognition. However, as we show in this paper, these networks are highly overparameterized for the task of fixation prediction. We first present a simple yet principled greedy pruning method which we call Fisher pruning. Through a combination of knowledge distillation and Fisher pruning, we obtain much more runtime-efficient architectures for saliency prediction, achieving a 10x speedup for the same AUC performance as a state of the art network on the CAT2000 dataset. Speeding up single-image gaze prediction is important for many real-world applications, but it is also a crucial step in the development of video saliency models, where the amount of data to be processed is substantially larger.
Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
May 25, 2017
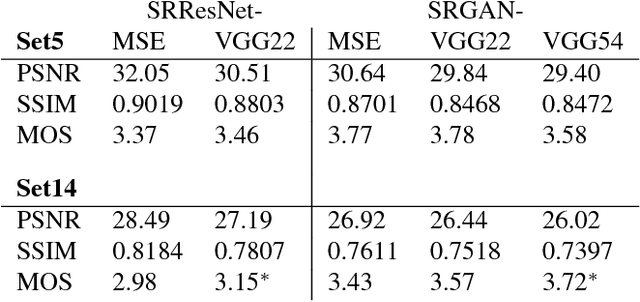

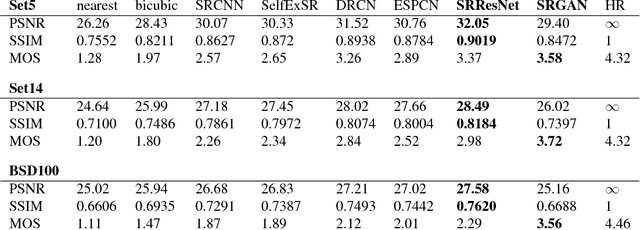
Despite the breakthroughs in accuracy and speed of single image super-resolution using faster and deeper convolutional neural networks, one central problem remains largely unsolved: how do we recover the finer texture details when we super-resolve at large upscaling factors? The behavior of optimization-based super-resolution methods is principally driven by the choice of the objective function. Recent work has largely focused on minimizing the mean squared reconstruction error. The resulting estimates have high peak signal-to-noise ratios, but they are often lacking high-frequency details and are perceptually unsatisfying in the sense that they fail to match the fidelity expected at the higher resolution. In this paper, we present SRGAN, a generative adversarial network (GAN) for image super-resolution (SR). To our knowledge, it is the first framework capable of inferring photo-realistic natural images for 4x upscaling factors. To achieve this, we propose a perceptual loss function which consists of an adversarial loss and a content loss. The adversarial loss pushes our solution to the natural image manifold using a discriminator network that is trained to differentiate between the super-resolved images and original photo-realistic images. In addition, we use a content loss motivated by perceptual similarity instead of similarity in pixel space. Our deep residual network is able to recover photo-realistic textures from heavily downsampled images on public benchmarks. An extensive mean-opinion-score (MOS) test shows hugely significant gains in perceptual quality using SRGAN. The MOS scores obtained with SRGAN are closer to those of the original high-resolution images than to those obtained with any state-of-the-art method.
Latent-Class Hough Forests for 6 DoF Object Pose Estimation
Feb 03, 2016
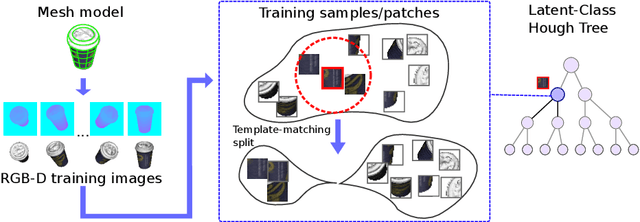
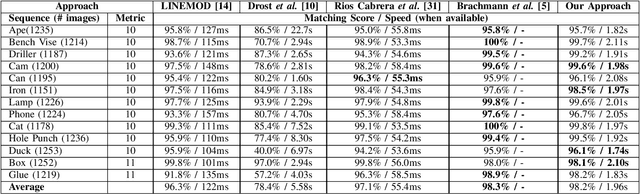
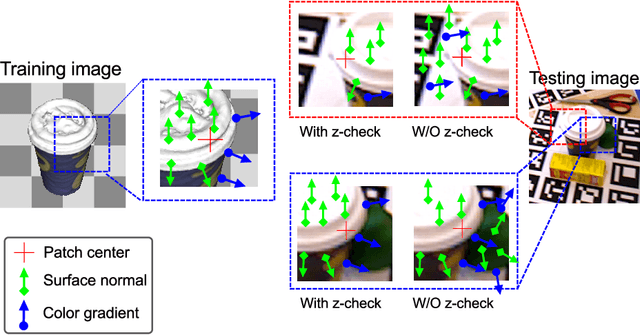
In this paper we present Latent-Class Hough Forests, a method for object detection and 6 DoF pose estimation in heavily cluttered and occluded scenarios. We adapt a state of the art template matching feature into a scale-invariant patch descriptor and integrate it into a regression forest using a novel template-based split function. We train with positive samples only and we treat class distributions at the leaf nodes as latent variables. During testing we infer by iteratively updating these distributions, providing accurate estimation of background clutter and foreground occlusions and, thus, better detection rate. Furthermore, as a by-product, our Latent-Class Hough Forests can provide accurate occlusion aware segmentation masks, even in the multi-instance scenario. In addition to an existing public dataset, which contains only single-instance sequences with large amounts of clutter, we have collected two, more challenging, datasets for multiple-instance detection containing heavy 2D and 3D clutter as well as foreground occlusions. We provide extensive experiments on the various parameters of the framework such as patch size, number of trees and number of iterations to infer class distributions at test time. We also evaluate the Latent-Class Hough Forests on all datasets where we outperform state of the art methods.