 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Size Reduction Using Frequency Based Double Hashing for Recommender Systems
Jul 28, 2020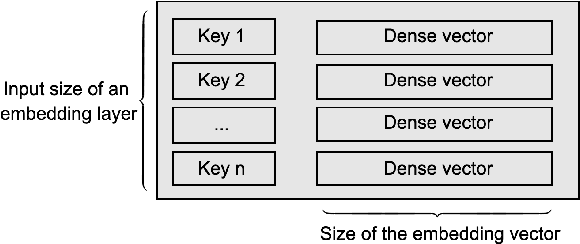
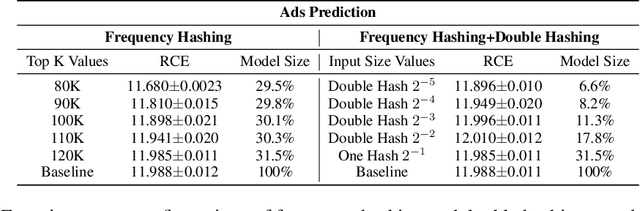
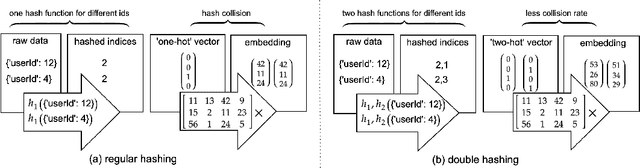
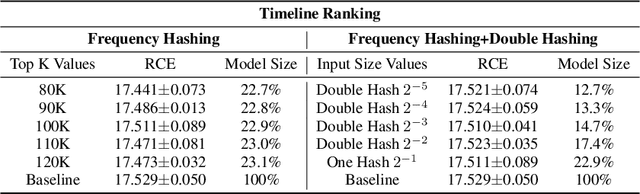
Deep Neural Networks (DNNs) with sparse input features have been widely used in recommender systems in industry. These models have large memory requirements and need a huge amount of training data. The large model size usually entails a cost, in the range of millions of dollars, for storage and communication with the inference services. In this paper, we propose a hybrid hashing method to combine frequency hashing and double hashing techniques for model size reduction, without compromising performance. We evaluate the proposed models on two product surfaces. In both cases, experiment results demonstrated that we can reduce the model size by around 90 % while keeping the performance on par with the original baselines.
Addressing Delayed Feedback for Continuous Training with Neural Networks in CTR prediction
Jul 15, 2019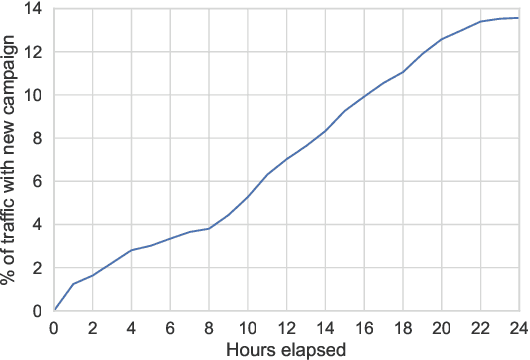
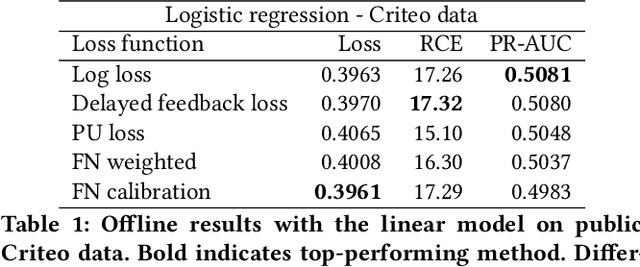
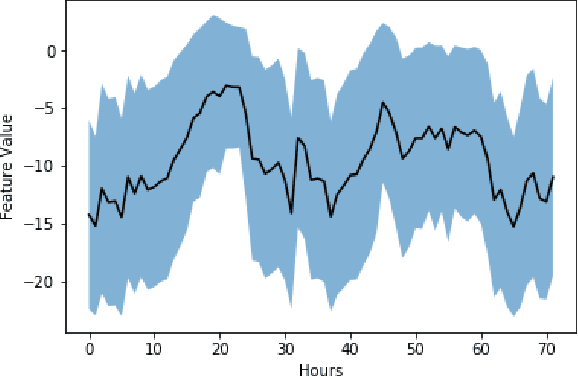
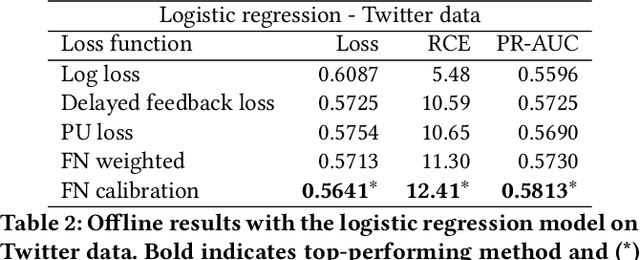
One of the challenges in display advertising is that the distribution of features and click through rate (CTR) can exhibit large shifts over time due to seasonality, changes to ad campaigns and other factors. The predominant strategy to keep up with these shifts is to train predictive models continuously, on fresh data, in order to prevent them from becoming stale. However, in many ad systems positive labels are only observed after a possibly long and random delay. These delayed labels pose a challenge to data freshness in continuous training: fresh data may not have complete label information at the time they are ingested by the training algorithm. Naive strategies which consider any data point a negative example until a positive label becomes available tend to underestimate CTR, resulting in inferior user experience and suboptimal performance for advertisers. The focus of this paper is to identify the best combination of loss functions and models that enable large-scale learning from a continuous stream of data in the presence of delayed labels. In this work, we compare 5 different loss functions, 3 of them applied to this problem for the first time. We benchmark their performance in offline settings on both public and proprietary datasets in conjunction with shallow and deep model architectures. We also discuss the engineering cost associated with implementing each loss function in a production environment. Finally, we carried out online experiments with the top performing methods, in order to validate their performance in a continuous training scheme. While training on 668 million in-house data points offline, our proposed methods outperform previous state-of-the-art by 3% relative cross entropy (RCE). During online experiments, we observed 55% gain in revenue per thousand requests (RPMq) against naive log loss.
Convergence Analysis of Gradient Descent Algorithms with Proportional Updates
Jan 09, 2018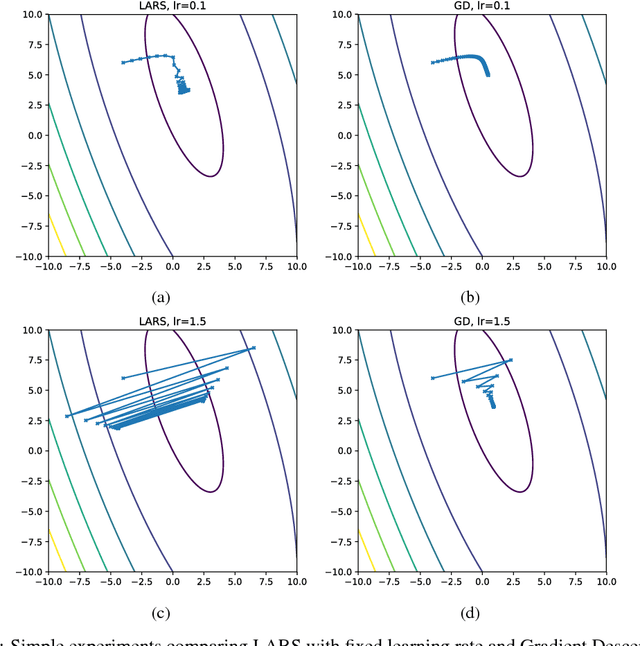
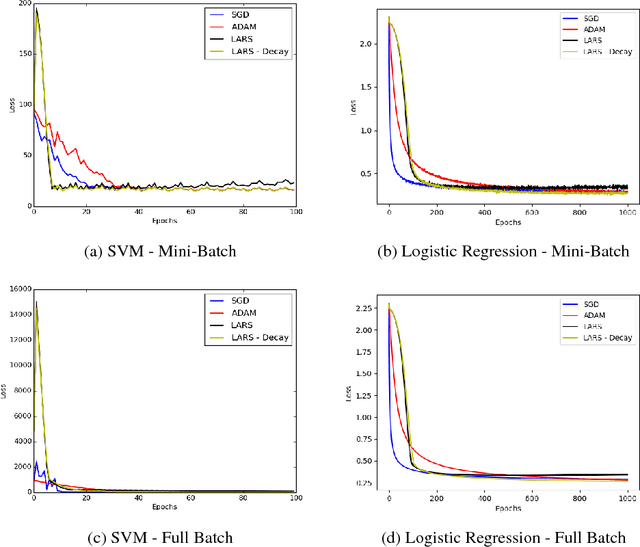
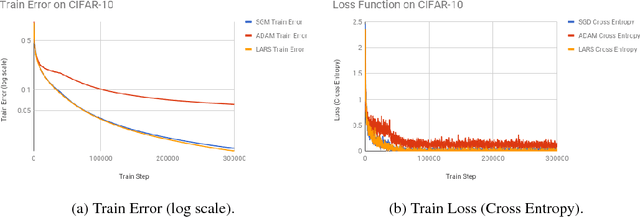
The rise of deep learning in recent years has brought with it increasingly clever optimization methods to deal with complex, non-linear loss functions. These methods are often designed with convex optimization in mind, but have been shown to work well in practice even for the highly non-convex optimization associated with neural networks. However, one significant drawback of these methods when they are applied to deep learning is that the magnitude of the update step is sometimes disproportionate to the magnitude of the weights (much smaller or larger), leading to training instabilities such as vanishing and exploding gradients. An idea to combat this issue is gradient descent with proportional updates. Gradient descent with proportional updates was introduced in 2017. It was independently developed by You et al (Layer-wise Adaptive Rate Scaling (LARS) algorithm) and by Abu-El-Haija (PercentDelta algorithm). The basic idea of both of these algorithms is to make each step of the gradient descent proportional to the current weight norm and independent of the gradient magnitude. It is common in the context of new optimization methods to prove convergence or derive regret bounds under the assumption of Lipschitz continuity and convexity. However, even though LARS and PercentDelta were shown to work well in practice, there is no theoretical analysis of the convergence properties of these algorithms. Thus it is not clear if the idea of gradient descent with proportional updates is used in the optimal way, or if it could be improved by using a different norm or specific learning rate schedule, for example. Moreover, it is not clear if these algorithms can be extended to other problems, besides neural networks. We attempt to answer these questions by establishing the theoretical analysis of gradient descent with proportional updates, and verifying this analysis with empirical examples.
Nintendo Super Smash Bros. Melee: An "Untouchable" Agent
Dec 08, 2017
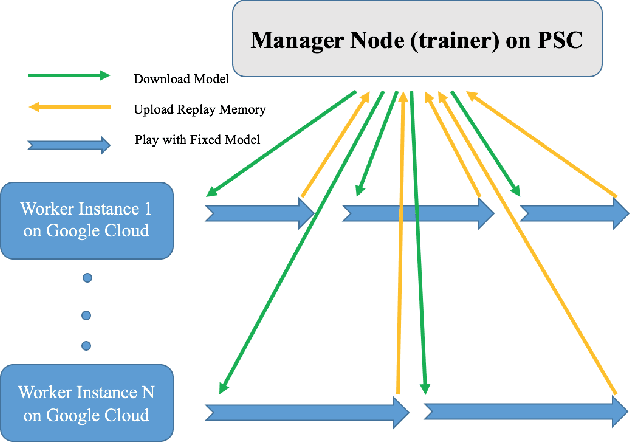
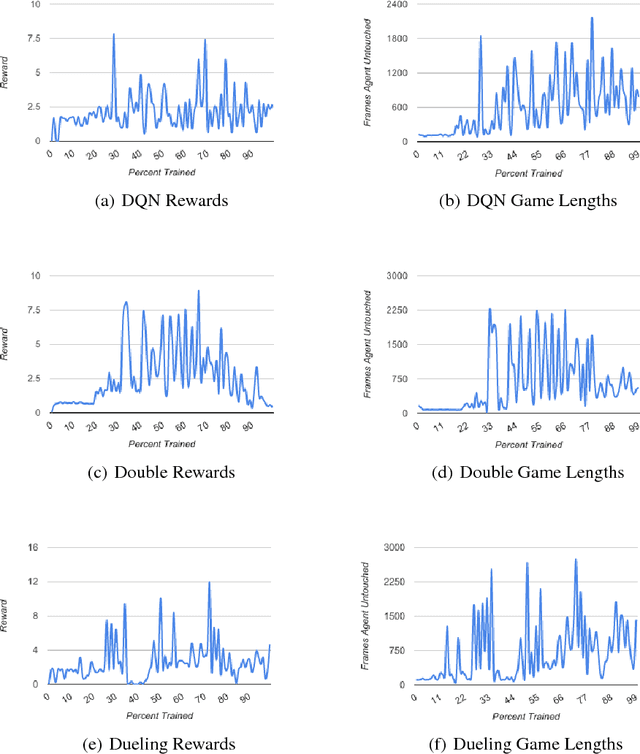
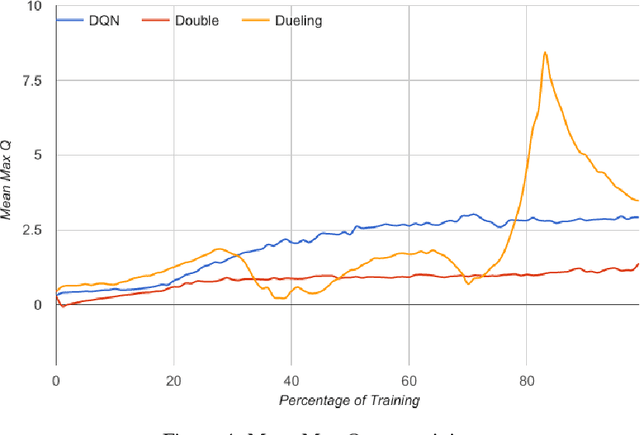
Nintendo's Super Smash Bros. Melee fighting game can be emulated on modern hardware allowing us to inspect internal memory states, such as character positions. We created an AI that avoids being hit by training using these internal memory states and outputting controller button presses. After training on a month's worth of Melee matches, our best agent learned to avoid the toughest AI built into the game for a full minute 74.6% of the time.