 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep In-GPU Experience Replay
Jan 09, 2018
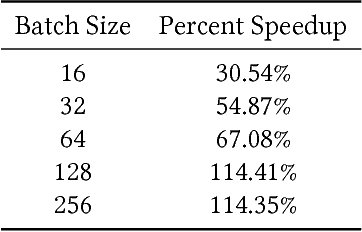
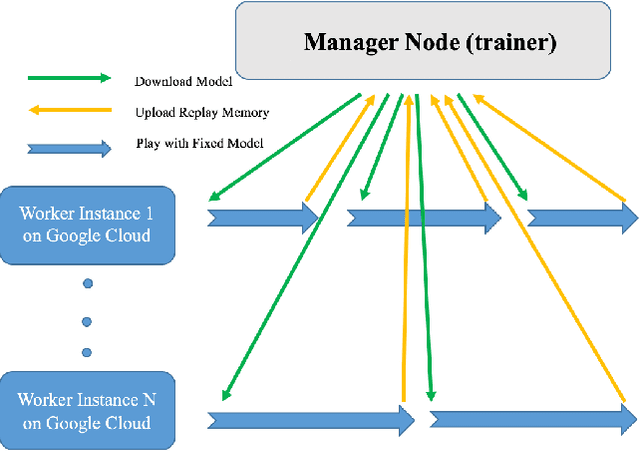
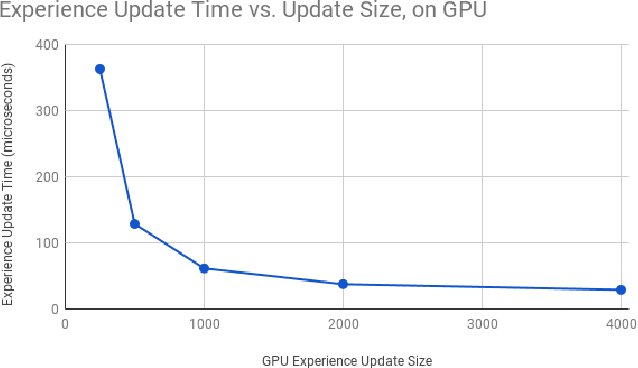
Experience replay allows a reinforcement learning agent to train on samples from a large amount of the most recent experiences. A simple in-RAM experience replay stores these most recent experiences in a list in RAM, and then copies sampled batches to the GPU for training. I moved this list to the GPU, thus creating an in-GPU experience replay, and a training step that no longer has inputs copied from the CPU. I trained an agent to play Super Smash Bros. Melee, using internal game memory values as inputs and outputting controller button presses. A single state in Melee contains 27 floats, so the full experience replay fits on a single GPU. For a batch size of 128, the in-GPU experience replay trained twice as fast as the in-RAM experience replay. As far as I know, this is the first in-GPU implementation of experience replay. Finally, I note a few ideas for fitting the experience replay inside the GPU when the environment state requires more memory.
Convergence Analysis of Gradient Descent Algorithms with Proportional Updates
Jan 09, 2018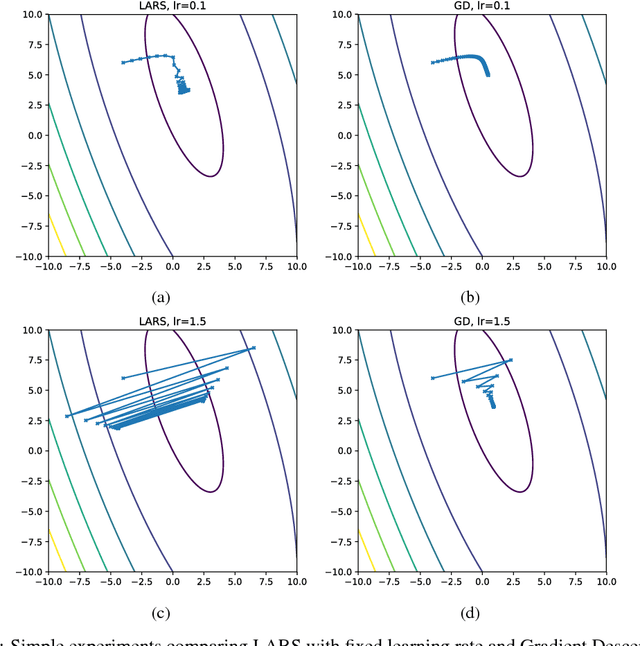
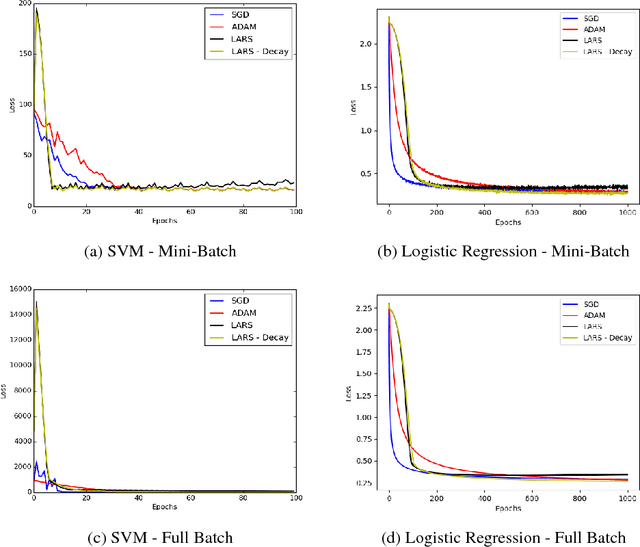
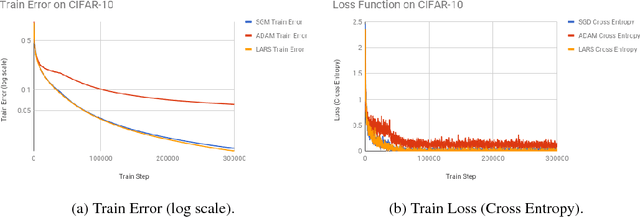
The rise of deep learning in recent years has brought with it increasingly clever optimization methods to deal with complex, non-linear loss functions. These methods are often designed with convex optimization in mind, but have been shown to work well in practice even for the highly non-convex optimization associated with neural networks. However, one significant drawback of these methods when they are applied to deep learning is that the magnitude of the update step is sometimes disproportionate to the magnitude of the weights (much smaller or larger), leading to training instabilities such as vanishing and exploding gradients. An idea to combat this issue is gradient descent with proportional updates. Gradient descent with proportional updates was introduced in 2017. It was independently developed by You et al (Layer-wise Adaptive Rate Scaling (LARS) algorithm) and by Abu-El-Haija (PercentDelta algorithm). The basic idea of both of these algorithms is to make each step of the gradient descent proportional to the current weight norm and independent of the gradient magnitude. It is common in the context of new optimization methods to prove convergence or derive regret bounds under the assumption of Lipschitz continuity and convexity. However, even though LARS and PercentDelta were shown to work well in practice, there is no theoretical analysis of the convergence properties of these algorithms. Thus it is not clear if the idea of gradient descent with proportional updates is used in the optimal way, or if it could be improved by using a different norm or specific learning rate schedule, for example. Moreover, it is not clear if these algorithms can be extended to other problems, besides neural networks. We attempt to answer these questions by establishing the theoretical analysis of gradient descent with proportional updates, and verifying this analysis with empirical examples.
Nintendo Super Smash Bros. Melee: An "Untouchable" Agent
Dec 08, 2017
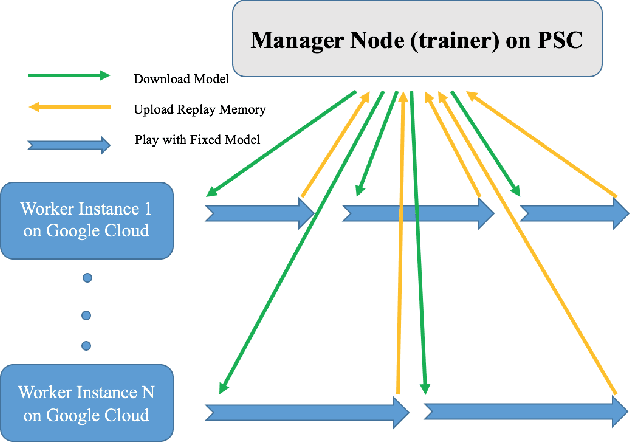
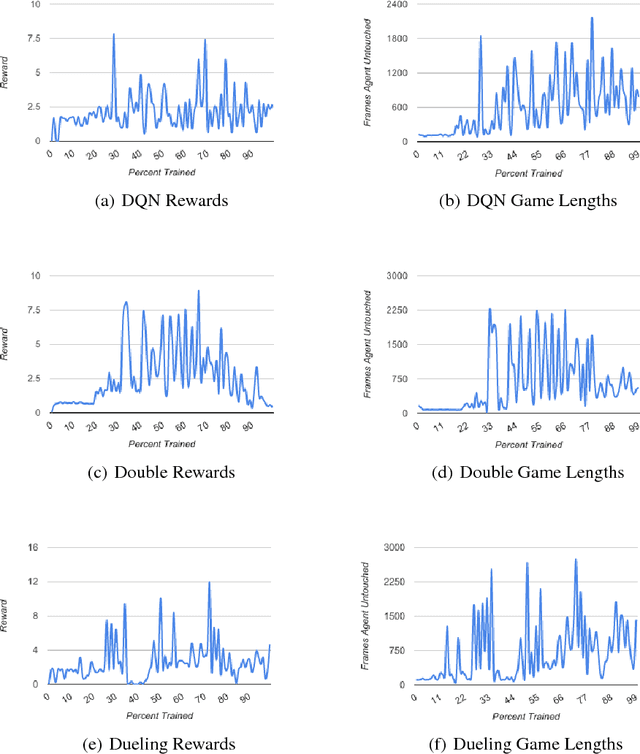
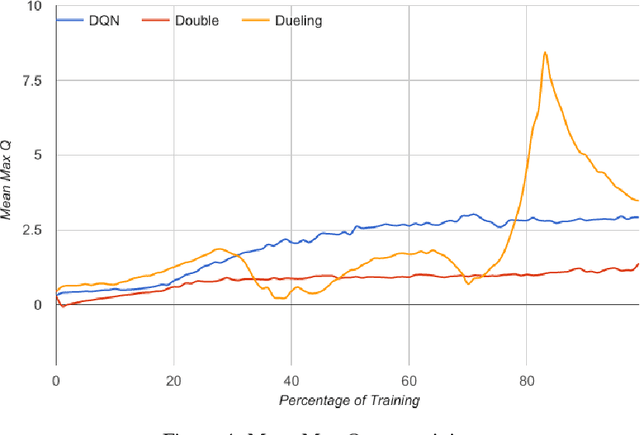
Nintendo's Super Smash Bros. Melee fighting game can be emulated on modern hardware allowing us to inspect internal memory states, such as character positions. We created an AI that avoids being hit by training using these internal memory states and outputting controller button presses. After training on a month's worth of Melee matches, our best agent learned to avoid the toughest AI built into the game for a full minute 74.6% of the time.