 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAtomic Information Flow: A Network Flow Model for Tool Attributions in RAG Systems
Feb 04, 2026Many tool-based Retrieval Augmented Generation (RAG) systems lack precise mechanisms for tracing final responses back to specific tool components -- a critical gap as systems scale to complex multi-agent architectures. We present \textbf{Atomic Information Flow (AIF)}, a graph-based network flow model that decomposes tool outputs and LLM calls into atoms: indivisible, self-contained units of information. By modeling LLM orchestration as a directed flow of atoms from tool and LLM nodes to a response super-sink, AIF enables granular attribution metrics for AI explainability. Motivated by the max-flow min-cut theorem in network flow theory, we train a lightweight Gemma3 (4B parameter) language model as a context compressor to approximate the minimum cut of tool atoms using flow signals computed offline by AIF. We note that the base Gemma3-4B model struggles to identify critical information with \textbf{54.7\%} accuracy on HotpotQA, barely outperforming lexical baselines (BM25). However, post-training on AIF signals boosts accuracy to \textbf{82.71\%} (+28.01 points) while achieving \textbf{87.52\%} (+1.85\%) context token compression -- bridging the gap with the Gemma3-27B variant, a model nearly $7\times$ larger.
Automatic Historical Feature Generation through Tree-based Method in Ads Prediction
Dec 31, 2020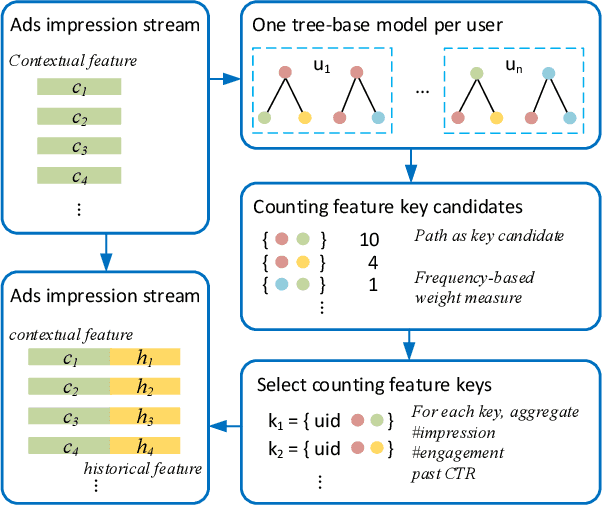

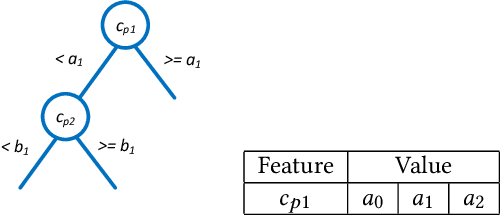
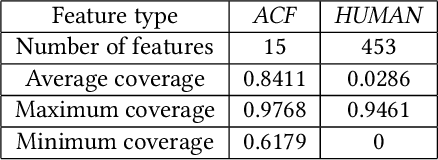
Historical features are important in ads click-through rate (CTR) prediction, because they account for past engagements between users and ads. In this paper, we study how to efficiently construct historical features through counting features. The key challenge of such problem lies in how to automatically identify counting keys. We propose a tree-based method for counting key selection. The intuition is that a decision tree naturally provides various combinations of features, which could be used as counting key candidate. In order to select personalized counting features, we train one decision tree model per user, and the counting keys are selected across different users with a frequency-based importance measure. To validate the effectiveness of proposed solution, we conduct large scale experiments on Twitter video advertising data. In both online learning and offline training settings, the automatically identified counting features outperform the manually curated counting features.
Addressing Delayed Feedback for Continuous Training with Neural Networks in CTR prediction
Jul 15, 2019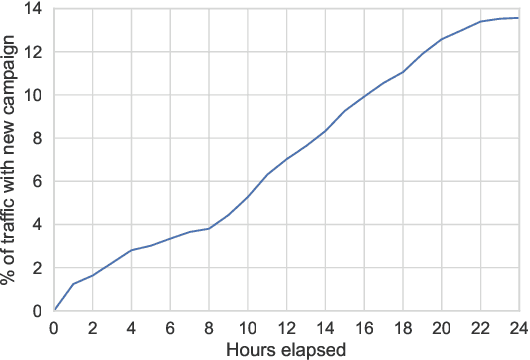
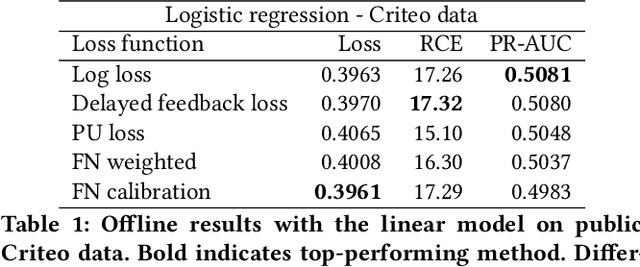
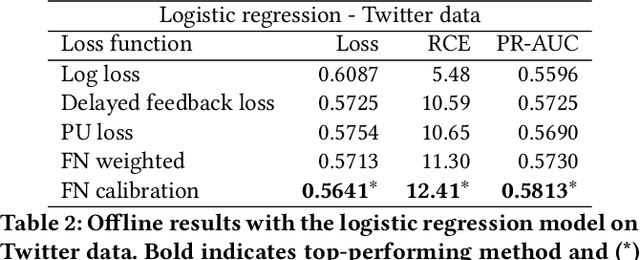
One of the challenges in display advertising is that the distribution of features and click through rate (CTR) can exhibit large shifts over time due to seasonality, changes to ad campaigns and other factors. The predominant strategy to keep up with these shifts is to train predictive models continuously, on fresh data, in order to prevent them from becoming stale. However, in many ad systems positive labels are only observed after a possibly long and random delay. These delayed labels pose a challenge to data freshness in continuous training: fresh data may not have complete label information at the time they are ingested by the training algorithm. Naive strategies which consider any data point a negative example until a positive label becomes available tend to underestimate CTR, resulting in inferior user experience and suboptimal performance for advertisers. The focus of this paper is to identify the best combination of loss functions and models that enable large-scale learning from a continuous stream of data in the presence of delayed labels. In this work, we compare 5 different loss functions, 3 of them applied to this problem for the first time. We benchmark their performance in offline settings on both public and proprietary datasets in conjunction with shallow and deep model architectures. We also discuss the engineering cost associated with implementing each loss function in a production environment. Finally, we carried out online experiments with the top performing methods, in order to validate their performance in a continuous training scheme. While training on 668 million in-house data points offline, our proposed methods outperform previous state-of-the-art by 3% relative cross entropy (RCE). During online experiments, we observed 55% gain in revenue per thousand requests (RPMq) against naive log loss.