 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmile, be Happy :) Emoji Embedding for Visual Sentiment Analysis
Jul 14, 2019
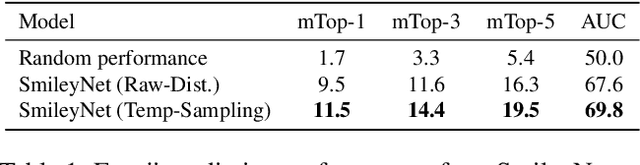
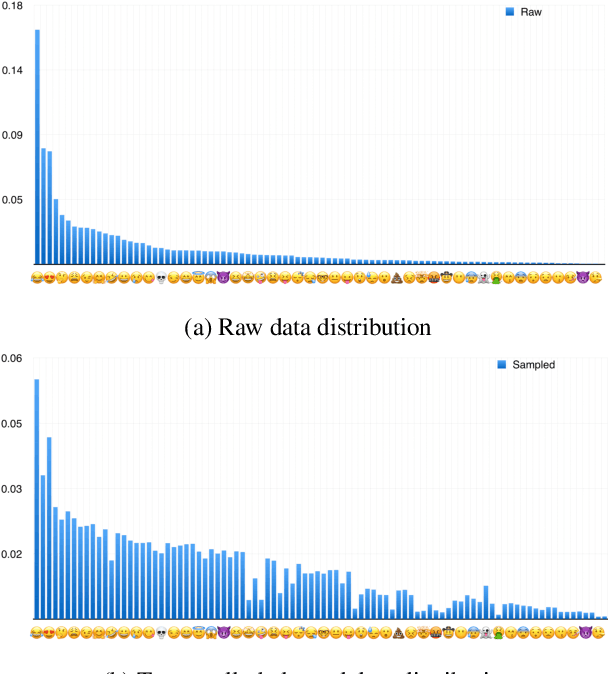
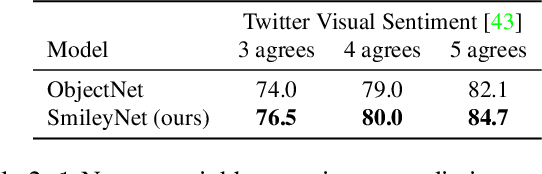
Due to the lack of large-scale datasets, the prevailing approach in visual sentiment analysis is to leverage models trained for object classification in large datasets like ImageNet. However, objects are sentiment neutral which hinders the expected gain of transfer learning for such tasks. In this work, we propose to overcome this problem by learning a novel sentiment-aligned image embedding that is better suited for subsequent visual sentiment analysis. Our embedding leverages the intricate relation between emojis and images in large-scale and readily available data from social media. Emojis are language-agnostic, consistent, and carry a clear sentiment signal which make them an excellent proxy to learn a sentiment aligned embedding. Hence, we construct a novel dataset of $4$ million images collected from Twitter with their associated emojis. We train a deep neural model for image embedding using emoji prediction task as a proxy. Our evaluation demonstrates that the proposed embedding outperforms the popular object-based counterpart consistently across several sentiment analysis benchmarks. Furthermore, without bell and whistles, our compact, effective and simple embedding outperforms the more elaborate and customized state-of-the-art deep models on these public benchmarks. Additionally, we introduce a novel emoji representation based on their visual emotional response which support a deeper understanding of the emoji modality and their usage on social media.
Checkerboard artifact free sub-pixel convolution: A note on sub-pixel convolution, resize convolution and convolution resize
Jul 10, 2017
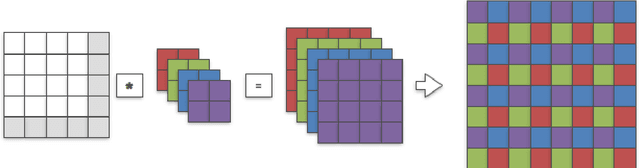
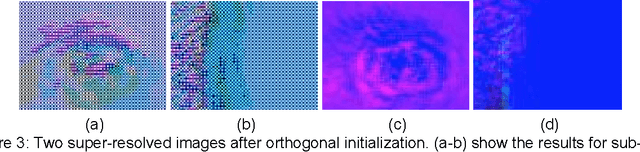
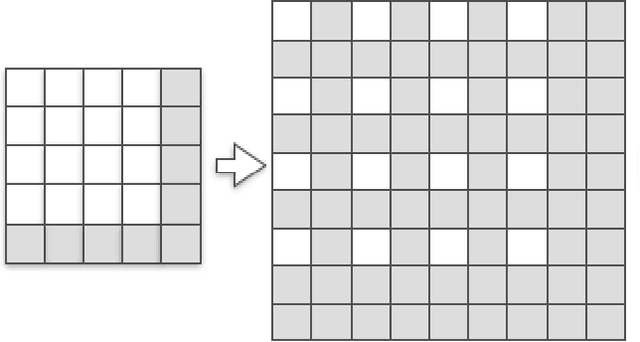
The most prominent problem associated with the deconvolution layer is the presence of checkerboard artifacts in output images and dense labels. To combat this problem, smoothness constraints, post processing and different architecture designs have been proposed. Odena et al. highlight three sources of checkerboard artifacts: deconvolution overlap, random initialization and loss functions. In this note, we proposed an initialization method for sub-pixel convolution known as convolution NN resize. Compared to sub-pixel convolution initialized with schemes designed for standard convolution kernels, it is free from checkerboard artifacts immediately after initialization. Compared to resize convolution, at the same computational complexity, it has more modelling power and converges to solutions with smaller test errors.
Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
May 25, 2017
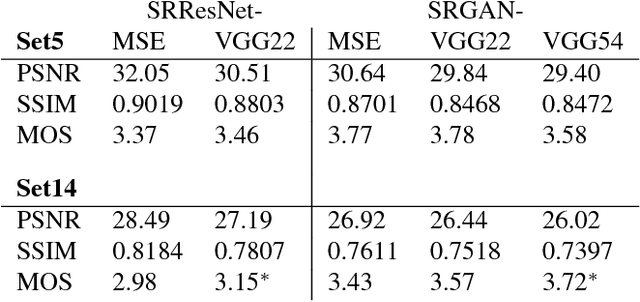

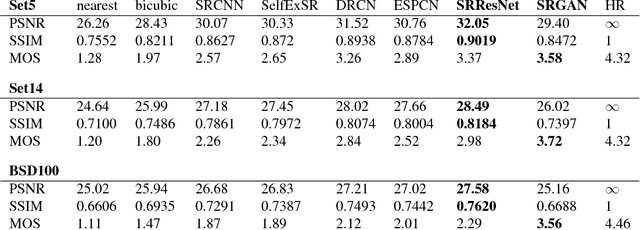
Despite the breakthroughs in accuracy and speed of single image super-resolution using faster and deeper convolutional neural networks, one central problem remains largely unsolved: how do we recover the finer texture details when we super-resolve at large upscaling factors? The behavior of optimization-based super-resolution methods is principally driven by the choice of the objective function. Recent work has largely focused on minimizing the mean squared reconstruction error. The resulting estimates have high peak signal-to-noise ratios, but they are often lacking high-frequency details and are perceptually unsatisfying in the sense that they fail to match the fidelity expected at the higher resolution. In this paper, we present SRGAN, a generative adversarial network (GAN) for image super-resolution (SR). To our knowledge, it is the first framework capable of inferring photo-realistic natural images for 4x upscaling factors. To achieve this, we propose a perceptual loss function which consists of an adversarial loss and a content loss. The adversarial loss pushes our solution to the natural image manifold using a discriminator network that is trained to differentiate between the super-resolved images and original photo-realistic images. In addition, we use a content loss motivated by perceptual similarity instead of similarity in pixel space. Our deep residual network is able to recover photo-realistic textures from heavily downsampled images on public benchmarks. An extensive mean-opinion-score (MOS) test shows hugely significant gains in perceptual quality using SRGAN. The MOS scores obtained with SRGAN are closer to those of the original high-resolution images than to those obtained with any state-of-the-art method.
Real-Time Video Super-Resolution with Spatio-Temporal Networks and Motion Compensation
Apr 10, 2017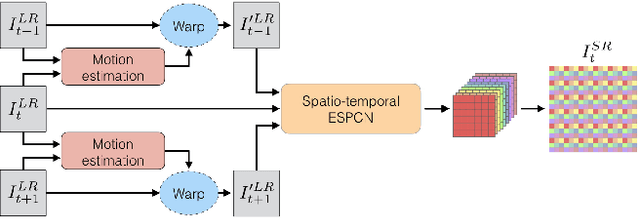

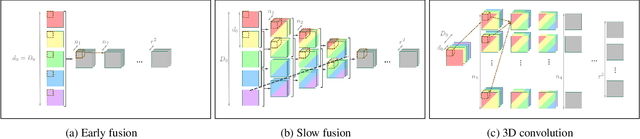
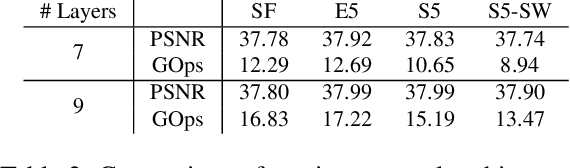
Convolutional neural networks have enabled accurate image super-resolution in real-time. However, recent attempts to benefit from temporal correlations in video super-resolution have been limited to naive or inefficient architectures. In this paper, we introduce spatio-temporal sub-pixel convolution networks that effectively exploit temporal redundancies and improve reconstruction accuracy while maintaining real-time speed. Specifically, we discuss the use of early fusion, slow fusion and 3D convolutions for the joint processing of multiple consecutive video frames. We also propose a novel joint motion compensation and video super-resolution algorithm that is orders of magnitude more efficient than competing methods, relying on a fast multi-resolution spatial transformer module that is end-to-end trainable. These contributions provide both higher accuracy and temporally more consistent videos, which we confirm qualitatively and quantitatively. Relative to single-frame models, spatio-temporal networks can either reduce the computational cost by 30% whilst maintaining the same quality or provide a 0.2dB gain for a similar computational cost. Results on publicly available datasets demonstrate that the proposed algorithms surpass current state-of-the-art performance in both accuracy and efficiency.
Is the deconvolution layer the same as a convolutional layer?
Sep 22, 2016In this note, we want to focus on aspects related to two questions most people asked us at CVPR about the network we presented. Firstly, What is the relationship between our proposed layer and the deconvolution layer? And secondly, why are convolutions in low-resolution (LR) space a better choice? These are key questions we tried to answer in the paper, but we were not able to go into as much depth and clarity as we would have liked in the space allowance. To better answer these questions in this note, we first discuss the relationships between the deconvolution layer in the forms of the transposed convolution layer, the sub-pixel convolutional layer and our efficient sub-pixel convolutional layer. We will refer to our efficient sub-pixel convolutional layer as a convolutional layer in LR space to distinguish it from the common sub-pixel convolutional layer. We will then show that for a fixed computational budget and complexity, a network with convolutions exclusively in LR space has more representation power at the same speed than a network that first upsamples the input in high resolution space.