 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData consistency networks for (calibration-less) accelerated parallel MR image reconstruction
Sep 25, 2019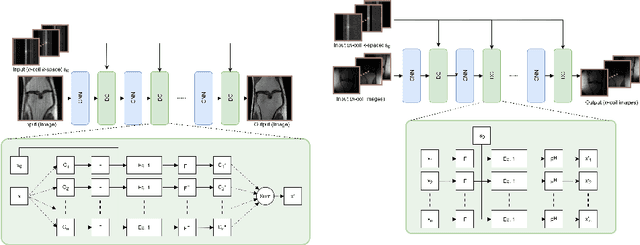
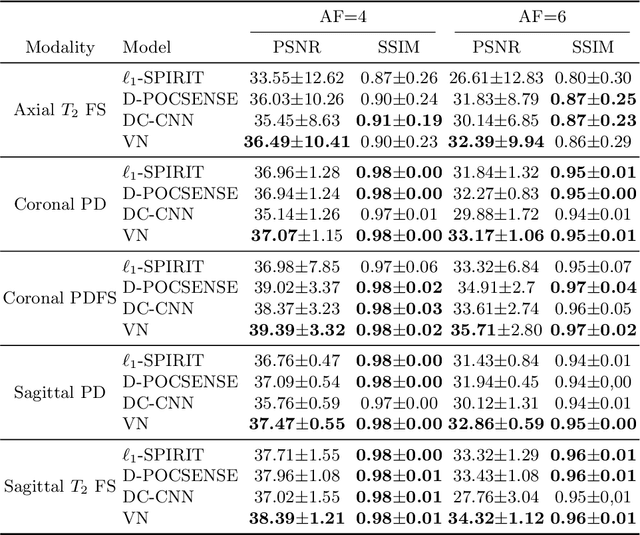
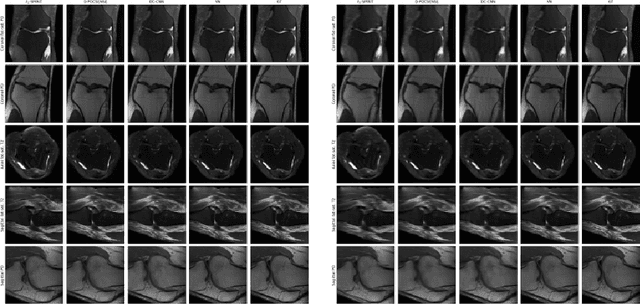
We present simple reconstruction networks for multi-coil data by extending deep cascade of CNN's and exploiting the data consistency layer. In particular, we propose two variants, where one is inspired by POCSENSE and the other is calibration-less. We show that the proposed approaches are competitive relative to the state of the art both quantitatively and qualitatively.
Smile, be Happy :) Emoji Embedding for Visual Sentiment Analysis
Jul 14, 2019
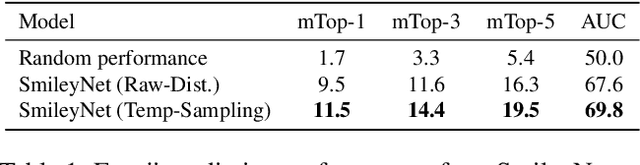
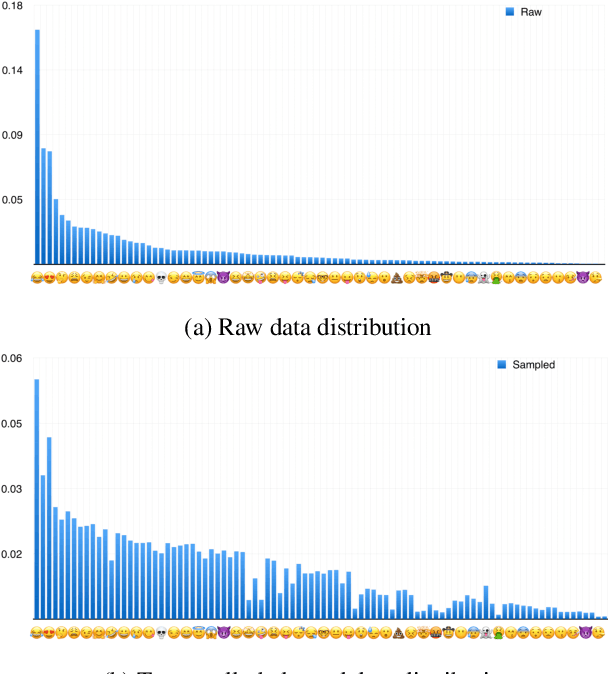
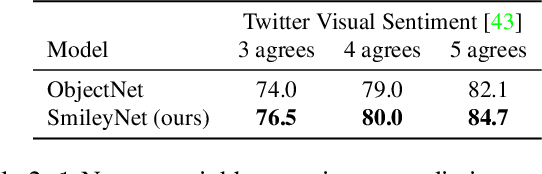
Due to the lack of large-scale datasets, the prevailing approach in visual sentiment analysis is to leverage models trained for object classification in large datasets like ImageNet. However, objects are sentiment neutral which hinders the expected gain of transfer learning for such tasks. In this work, we propose to overcome this problem by learning a novel sentiment-aligned image embedding that is better suited for subsequent visual sentiment analysis. Our embedding leverages the intricate relation between emojis and images in large-scale and readily available data from social media. Emojis are language-agnostic, consistent, and carry a clear sentiment signal which make them an excellent proxy to learn a sentiment aligned embedding. Hence, we construct a novel dataset of $4$ million images collected from Twitter with their associated emojis. We train a deep neural model for image embedding using emoji prediction task as a proxy. Our evaluation demonstrates that the proposed embedding outperforms the popular object-based counterpart consistently across several sentiment analysis benchmarks. Furthermore, without bell and whistles, our compact, effective and simple embedding outperforms the more elaborate and customized state-of-the-art deep models on these public benchmarks. Additionally, we introduce a novel emoji representation based on their visual emotional response which support a deeper understanding of the emoji modality and their usage on social media.
Deep Hashing using Entropy Regularised Product Quantisation Network
Feb 11, 2019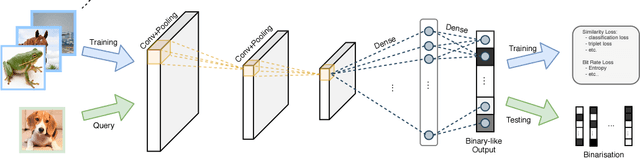
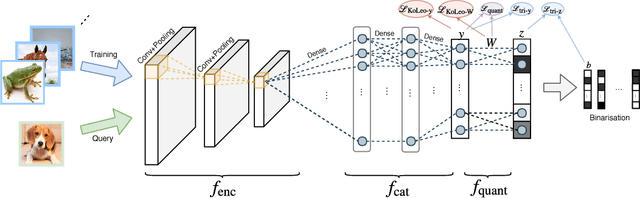
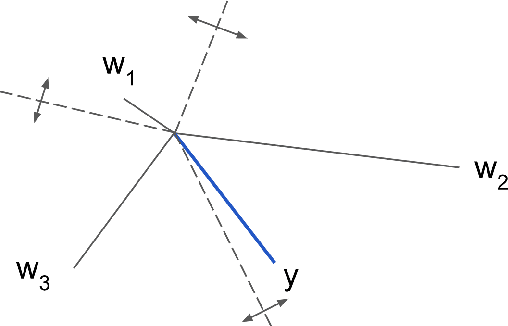
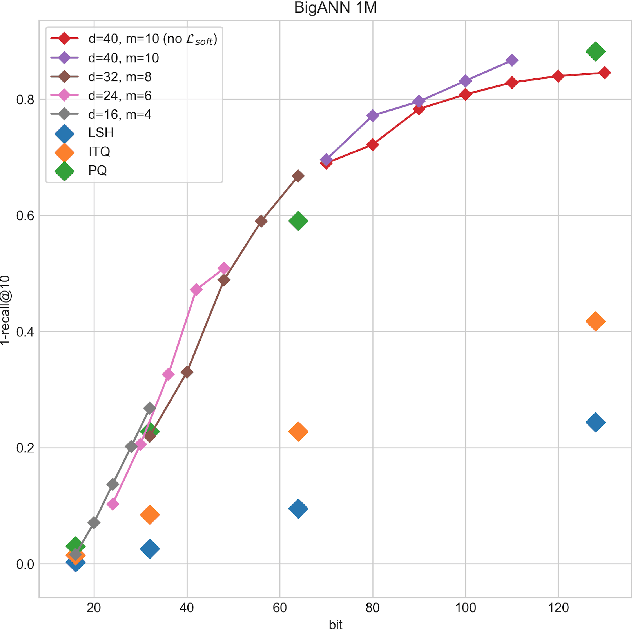
In large scale systems, approximate nearest neighbour search is a crucial algorithm to enable efficient data retrievals. Recently, deep learning-based hashing algorithms have been proposed as a promising paradigm to enable data dependent schemes. Often their efficacy is only demonstrated on data sets with fixed, limited numbers of classes. In practical scenarios, those labels are not always available or one requires a method that can handle a higher input variability, as well as a higher granularity. To fulfil those requirements, we look at more flexible similarity measures. In this work, we present a novel, flexible, end-to-end trainable network for large-scale data hashing. Our method works by transforming the data distribution to behave as a uniform distribution on a product of spheres. The transformed data is subsequently hashed to a binary form in a way that maximises entropy of the output, (i.e. to fully utilise the available bit-rate capacity) while maintaining the correctness (i.e. close items hash to the same key in the map). We show that the method outperforms baseline approaches such as locality-sensitive hashing and product quantisation in the limited capacity regime.
Generalising Deep Learning MRI Reconstruction across Different Domains
Jan 31, 2019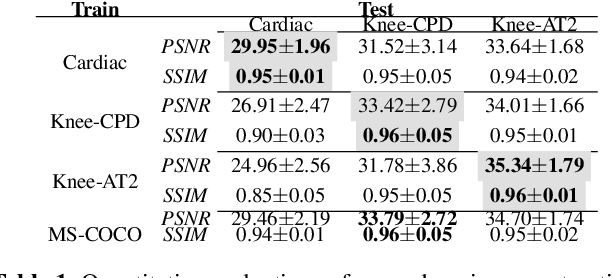
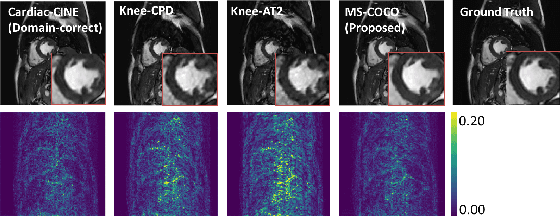

We look into robustness of deep learning based MRI reconstruction when tested on unseen contrasts and organs. We then propose to generalise the network by training with large publicly-available natural image datasets with synthesised phase information to achieve high cross-domain reconstruction performance which is competitive with domain-specific training. To explain its generalisation mechanism, we have also analysed patch sets for different training datasets.
Convolutional Recurrent Neural Networks for Dynamic MR Image Reconstruction
Oct 14, 2018


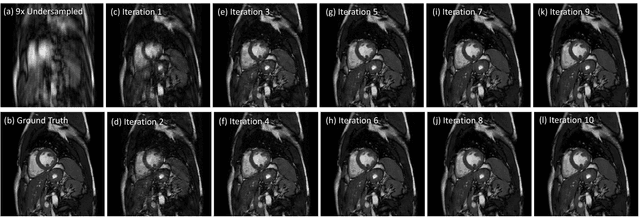
Accelerating the data acquisition of dynamic magnetic resonance imaging (MRI) leads to a challenging ill-posed inverse problem, which has received great interest from both the signal processing and machine learning community over the last decades. The key ingredient to the problem is how to exploit the temporal correlation of the MR sequence to resolve the aliasing artefact. Traditionally, such observation led to a formulation of a non-convex optimisation problem, which were solved using iterative algorithms. Recently, however, deep learning based-approaches have gained significant popularity due to its ability to solve general inversion problems. In this work, we propose a unique, novel convolutional recurrent neural network (CRNN) architecture which reconstructs high quality cardiac MR images from highly undersampled k-space data by jointly exploiting the dependencies of the temporal sequences as well as the iterative nature of the traditional optimisation algorithms. In particular, the proposed architecture embeds the structure of the traditional iterative algorithms, efficiently modelling the recurrence of the iterative reconstruction stages by using recurrent hidden connections over such iterations. In addition, spatiotemporal dependencies are simultaneously learnt by exploiting bidirectional recurrent hidden connections across time sequences. The proposed algorithm is able to learn both the temporal dependency and the iterative reconstruction process effectively with only a very small number of parameters, while outperforming current MR reconstruction methods in terms of computational complexity, reconstruction accuracy and speed.
Anatomically Constrained Neural Networks (ACNN): Application to Cardiac Image Enhancement and Segmentation
Dec 05, 2017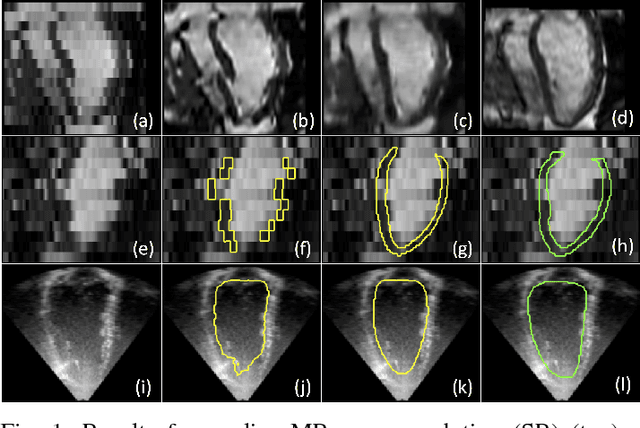
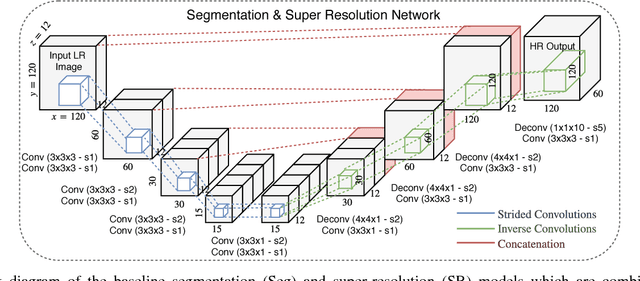
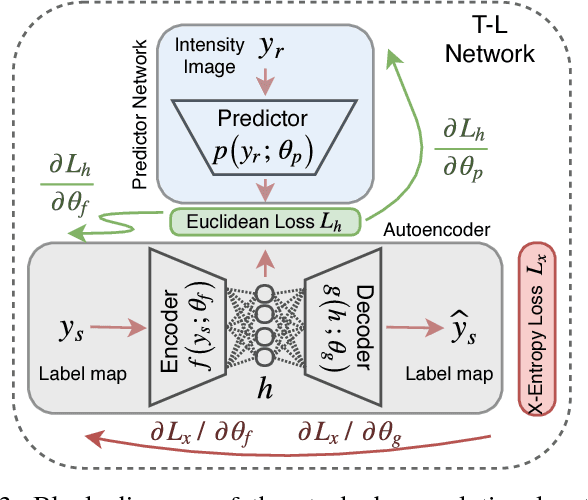
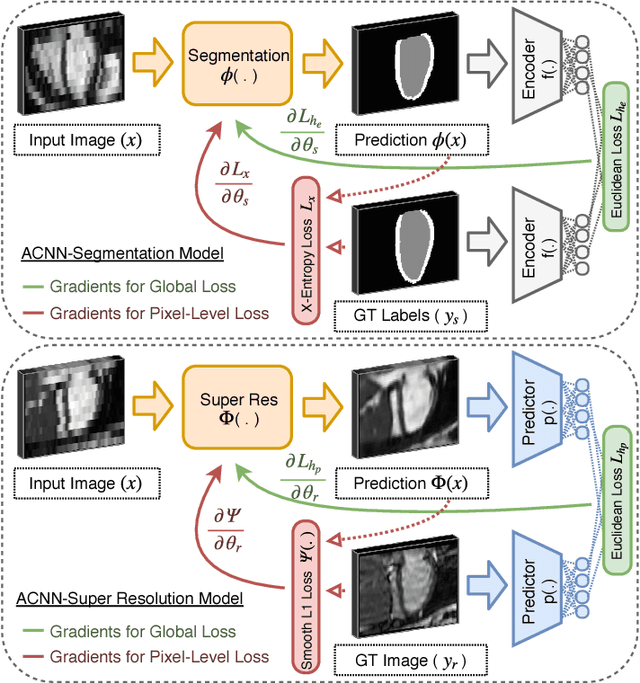
Incorporation of prior knowledge about organ shape and location is key to improve performance of image analysis approaches. In particular, priors can be useful in cases where images are corrupted and contain artefacts due to limitations in image acquisition. The highly constrained nature of anatomical objects can be well captured with learning based techniques. However, in most recent and promising techniques such as CNN based segmentation it is not obvious how to incorporate such prior knowledge. State-of-the-art methods operate as pixel-wise classifiers where the training objectives do not incorporate the structure and inter-dependencies of the output. To overcome this limitation, we propose a generic training strategy that incorporates anatomical prior knowledge into CNNs through a new regularisation model, which is trained end-to-end. The new framework encourages models to follow the global anatomical properties of the underlying anatomy (e.g. shape, label structure) via learned non-linear representations of the shape. We show that the proposed approach can be easily adapted to different analysis tasks (e.g. image enhancement, segmentation) and improve the prediction accuracy of the state-of-the-art models. The applicability of our approach is shown on multi-modal cardiac datasets and public benchmarks. Additionally, we demonstrate how the learned deep models of 3D shapes can be interpreted and used as biomarkers for classification of cardiac pathologies.
A Deep Cascade of Convolutional Neural Networks for Dynamic MR Image Reconstruction
Nov 23, 2017



Inspired by recent advances in deep learning, we propose a framework for reconstructing dynamic sequences of 2D cardiac magnetic resonance (MR) images from undersampled data using a deep cascade of convolutional neural networks (CNNs) to accelerate the data acquisition process. In particular, we address the case where data is acquired using aggressive Cartesian undersampling. Firstly, we show that when each 2D image frame is reconstructed independently, the proposed method outperforms state-of-the-art 2D compressed sensing approaches such as dictionary learning-based MR image reconstruction, in terms of reconstruction error and reconstruction speed. Secondly, when reconstructing the frames of the sequences jointly, we demonstrate that CNNs can learn spatio-temporal correlations efficiently by combining convolution and data sharing approaches. We show that the proposed method consistently outperforms state-of-the-art methods and is capable of preserving anatomical structure more faithfully up to 11-fold undersampling. Moreover, reconstruction is very fast: each complete dynamic sequence can be reconstructed in less than 10s and, for the 2D case, each image frame can be reconstructed in 23ms, enabling real-time applications.
Frame Interpolation with Multi-Scale Deep Loss Functions and Generative Adversarial Networks
Nov 16, 2017

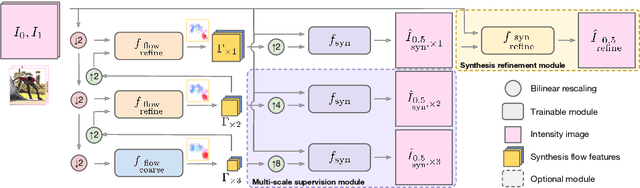
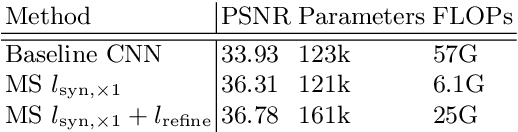
Frame interpolation attempts to synthesise intermediate frames given one or more consecutive video frames. In recent years, deep learning approaches, and in particular convolutional neural networks, have succeeded at tackling low- and high-level computer vision problems including frame interpolation. There are two main pursuits in this line of research, namely algorithm efficiency and reconstruction quality. In this paper, we present a multi-scale generative adversarial network for frame interpolation (FIGAN). To maximise the efficiency of our network, we propose a novel multi-scale residual estimation module where the predicted flow and synthesised frame are constructed in a coarse-to-fine fashion. To improve the quality of synthesised intermediate video frames, our network is jointly supervised at different levels with a perceptual loss function that consists of an adversarial and two content losses. We evaluate the proposed approach using a collection of 60fps videos from YouTube-8m. Our results improve the state-of-the-art accuracy and efficiency, and a subjective visual quality comparable to the best performing interpolation method.
Checkerboard artifact free sub-pixel convolution: A note on sub-pixel convolution, resize convolution and convolution resize
Jul 10, 2017
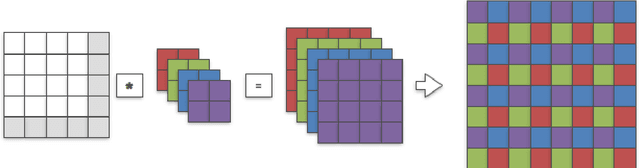
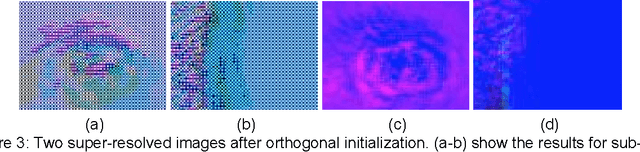
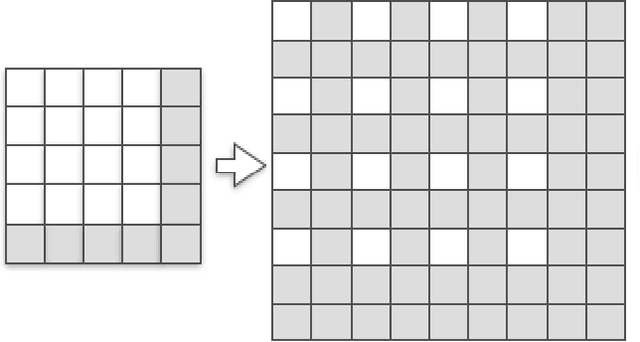
The most prominent problem associated with the deconvolution layer is the presence of checkerboard artifacts in output images and dense labels. To combat this problem, smoothness constraints, post processing and different architecture designs have been proposed. Odena et al. highlight three sources of checkerboard artifacts: deconvolution overlap, random initialization and loss functions. In this note, we proposed an initialization method for sub-pixel convolution known as convolution NN resize. Compared to sub-pixel convolution initialized with schemes designed for standard convolution kernels, it is free from checkerboard artifacts immediately after initialization. Compared to resize convolution, at the same computational complexity, it has more modelling power and converges to solutions with smaller test errors.
Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
May 25, 2017
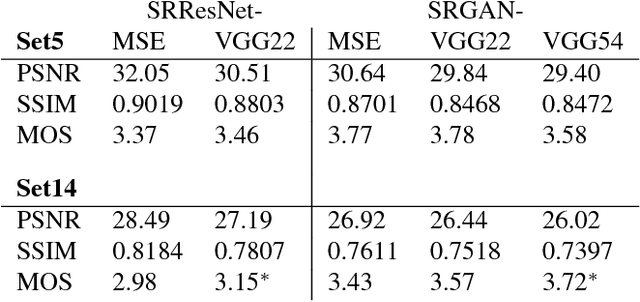

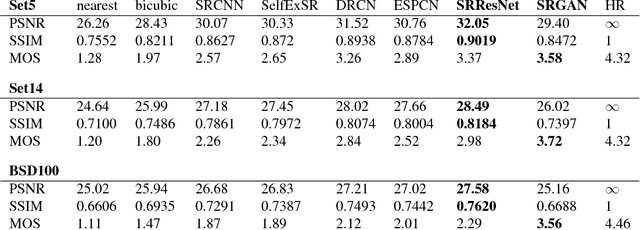
Despite the breakthroughs in accuracy and speed of single image super-resolution using faster and deeper convolutional neural networks, one central problem remains largely unsolved: how do we recover the finer texture details when we super-resolve at large upscaling factors? The behavior of optimization-based super-resolution methods is principally driven by the choice of the objective function. Recent work has largely focused on minimizing the mean squared reconstruction error. The resulting estimates have high peak signal-to-noise ratios, but they are often lacking high-frequency details and are perceptually unsatisfying in the sense that they fail to match the fidelity expected at the higher resolution. In this paper, we present SRGAN, a generative adversarial network (GAN) for image super-resolution (SR). To our knowledge, it is the first framework capable of inferring photo-realistic natural images for 4x upscaling factors. To achieve this, we propose a perceptual loss function which consists of an adversarial loss and a content loss. The adversarial loss pushes our solution to the natural image manifold using a discriminator network that is trained to differentiate between the super-resolved images and original photo-realistic images. In addition, we use a content loss motivated by perceptual similarity instead of similarity in pixel space. Our deep residual network is able to recover photo-realistic textures from heavily downsampled images on public benchmarks. An extensive mean-opinion-score (MOS) test shows hugely significant gains in perceptual quality using SRGAN. The MOS scores obtained with SRGAN are closer to those of the original high-resolution images than to those obtained with any state-of-the-art method.