 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Activation via Multivariate Projection
Paper and Code
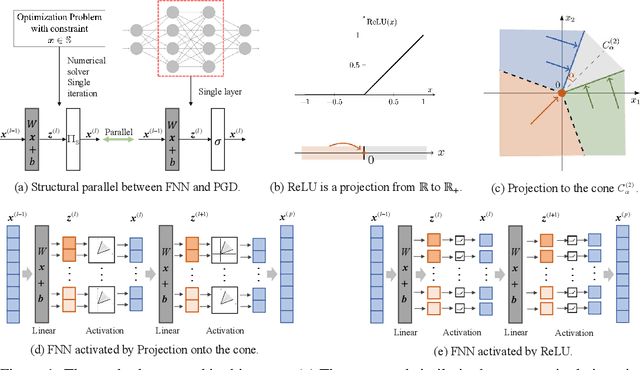
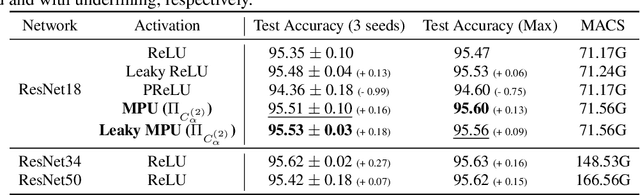
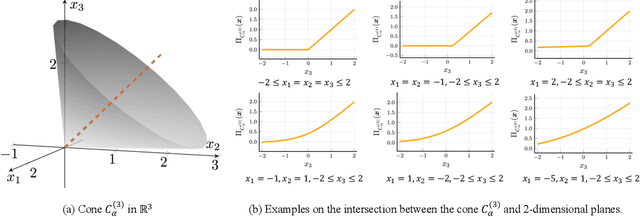
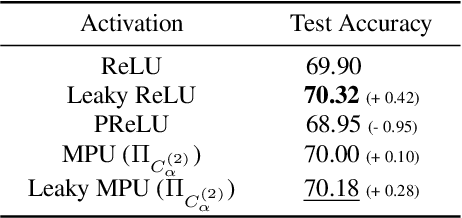
Activation functions are essential to introduce nonlinearity into neural networks, with the Rectified Linear Unit (ReLU) often favored for its simplicity and effectiveness. Motivated by the structural similarity between a shallow Feedforward Neural Network (FNN) and a single iteration of the Projected Gradient Descent (PGD) algorithm, a standard approach for solving constrained optimization problems, we consider ReLU as a projection from R onto the nonnegative half-line R+. Building on this interpretation, we extend ReLU by substituting it with a generalized projection operator onto a convex cone, such as the Second-Order Cone (SOC) projection, thereby naturally extending it to a Multivariate Projection Unit (MPU), an activation function with multiple inputs and multiple outputs. We further provide a mathematical proof establishing that FNNs activated by SOC projections outperform those utilizing ReLU in terms of expressive power. Experimental evaluations on widely-adopted architectures further corroborate MPU's effectiveness against a broader range of existing activation functions.