 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAniGaussian: Animatable Gaussian Avatar with Pose-guided Deformation
Feb 24, 2025

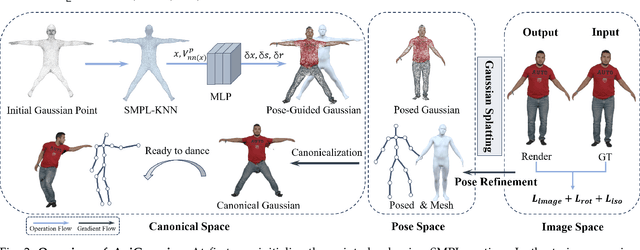

Recent advancements in Gaussian-based human body reconstruction have achieved notable success in creating animatable avatars. However, there are ongoing challenges to fully exploit the SMPL model's prior knowledge and enhance the visual fidelity of these models to achieve more refined avatar reconstructions. In this paper, we introduce AniGaussian which addresses the above issues with two insights. First, we propose an innovative pose guided deformation strategy that effectively constrains the dynamic Gaussian avatar with SMPL pose guidance, ensuring that the reconstructed model not only captures the detailed surface nuances but also maintains anatomical correctness across a wide range of motions. Second, we tackle the expressiveness limitations of Gaussian models in representing dynamic human bodies. We incorporate rigid-based priors from previous works to enhance the dynamic transform capabilities of the Gaussian model. Furthermore, we introduce a split-with-scale strategy that significantly improves geometry quality. The ablative study experiment demonstrates the effectiveness of our innovative model design. Through extensive comparisons with existing methods, AniGaussian demonstrates superior performance in both qualitative result and quantitative metrics.
Infinite Motion: Extended Motion Generation via Long Text Instructions
Jul 11, 2024



In the realm of motion generation, the creation of long-duration, high-quality motion sequences remains a significant challenge. This paper presents our groundbreaking work on "Infinite Motion", a novel approach that leverages long text to extended motion generation, effectively bridging the gap between short and long-duration motion synthesis. Our core insight is the strategic extension and reassembly of existing high-quality text-motion datasets, which has led to the creation of a novel benchmark dataset to facilitate the training of models for extended motion sequences. A key innovation of our model is its ability to accept arbitrary lengths of text as input, enabling the generation of motion sequences tailored to specific narratives or scenarios. Furthermore, we incorporate the timestamp design for text which allows precise editing of local segments within the generated sequences, offering unparalleled control and flexibility in motion synthesis. We further demonstrate the versatility and practical utility of "Infinite Motion" through three specific applications: natural language interactive editing, motion sequence editing within long sequences and splicing of independent motion sequences. Each application highlights the adaptability of our approach and broadens the spectrum of possibilities for research and development in motion generation. Through extensive experiments, we demonstrate the superior performance of our model in generating long sequence motions compared to existing methods.Project page: https://shuochengzhai.github.io/Infinite-motion.github.io/
GaussianBody: Clothed Human Reconstruction via 3d Gaussian Splatting
Jan 27, 2024In this work, we propose a novel clothed human reconstruction method called GaussianBody, based on 3D Gaussian Splatting. Compared with the costly neural radiance based models, 3D Gaussian Splatting has recently demonstrated great performance in terms of training time and rendering quality. However, applying the static 3D Gaussian Splatting model to the dynamic human reconstruction problem is non-trivial due to complicated non-rigid deformations and rich cloth details. To address these challenges, our method considers explicit pose-guided deformation to associate dynamic Gaussians across the canonical space and the observation space, introducing a physically-based prior with regularized transformations helps mitigate ambiguity between the two spaces. During the training process, we further propose a pose refinement strategy to update the pose regression for compensating the inaccurate initial estimation and a split-with-scale mechanism to enhance the density of regressed point clouds. The experiments validate that our method can achieve state-of-the-art photorealistic novel-view rendering results with high-quality details for dynamic clothed human bodies, along with explicit geometry reconstruction.