 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFilmComposer: LLM-Driven Music Production for Silent Film Clips
Mar 11, 2025
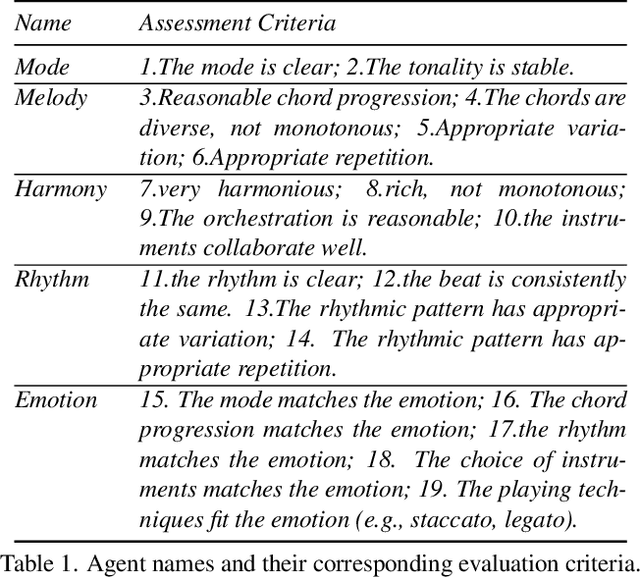
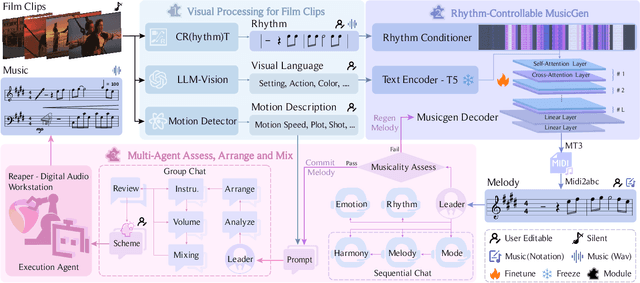
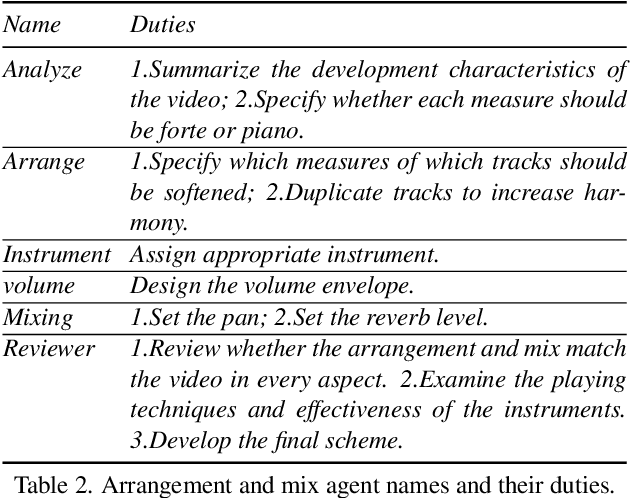
In this work, we implement music production for silent film clips using LLM-driven method. Given the strong professional demands of film music production, we propose the FilmComposer, simulating the actual workflows of professional musicians. FilmComposer is the first to combine large generative models with a multi-agent approach, leveraging the advantages of both waveform music and symbolic music generation. Additionally, FilmComposer is the first to focus on the three core elements of music production for film-audio quality, musicality, and musical development-and introduces various controls, such as rhythm, semantics, and visuals, to enhance these key aspects. Specifically, FilmComposer consists of the visual processing module, rhythm-controllable MusicGen, and multi-agent assessment, arrangement and mix. In addition, our framework can seamlessly integrate into the actual music production pipeline and allows user intervention in every step, providing strong interactivity and a high degree of creative freedom. Furthermore, we propose MusicPro-7k which includes 7,418 film clips, music, description, rhythm spots and main melody, considering the lack of a professional and high-quality film music dataset. Finally, both the standard metrics and the new specialized metrics we propose demonstrate that the music generated by our model achieves state-of-the-art performance in terms of quality, consistency with video, diversity, musicality, and musical development. Project page: https://apple-jun.github.io/FilmComposer.github.io/
SonicVisionLM: Playing Sound with Vision Language Models
Jan 27, 2024



There has been a growing interest in the task of generating sound for silent videos, primarily because of its practicality in streamlining video post-production. However, existing methods for video-sound generation attempt to directly create sound from visual representations, which can be challenging due to the difficulty of aligning visual representations with audio representations. In this paper, we present SonicVisionLM, a novel framework aimed at generating a wide range of sound effects by leveraging vision language models. Instead of generating audio directly from video, we use the capabilities of powerful vision language models (VLMs). When provided with a silent video, our approach first identifies events within the video using a VLM to suggest possible sounds that match the video content. This shift in approach transforms the challenging task of aligning image and audio into more well-studied sub-problems of aligning image-to-text and text-to-audio through the popular diffusion models. To improve the quality of audio recommendations with LLMs, we have collected an extensive dataset that maps text descriptions to specific sound effects and developed temporally controlled audio adapters. Our approach surpasses current state-of-the-art methods for converting video to audio, resulting in enhanced synchronization with the visuals and improved alignment between audio and video components. Project page: https://yusiissy.github.io/SonicVisionLM.github.io/