 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusionSfM: Predicting Structure and Motion via Ray Origin and Endpoint Diffusion
May 08, 2025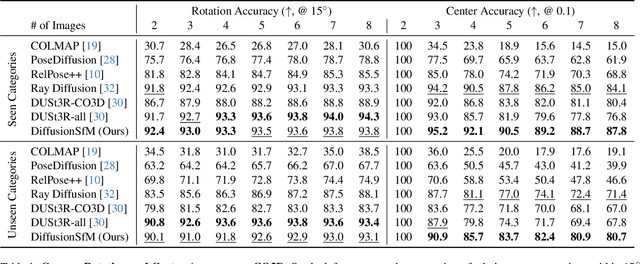
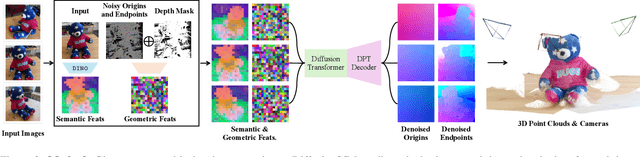

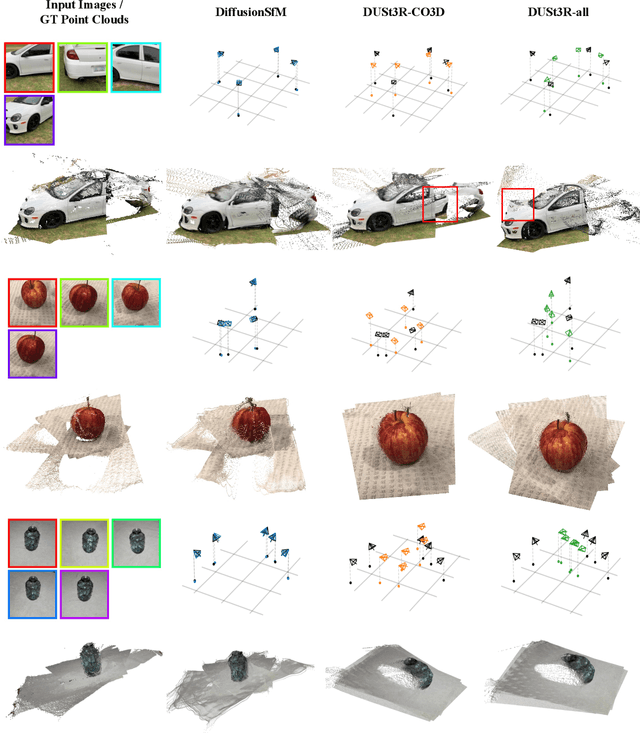
Current Structure-from-Motion (SfM) methods typically follow a two-stage pipeline, combining learned or geometric pairwise reasoning with a subsequent global optimization step. In contrast, we propose a data-driven multi-view reasoning approach that directly infers 3D scene geometry and camera poses from multi-view images. Our framework, DiffusionSfM, parameterizes scene geometry and cameras as pixel-wise ray origins and endpoints in a global frame and employs a transformer-based denoising diffusion model to predict them from multi-view inputs. To address practical challenges in training diffusion models with missing data and unbounded scene coordinates, we introduce specialized mechanisms that ensure robust learning. We empirically validate DiffusionSfM on both synthetic and real datasets, demonstrating that it outperforms classical and learning-based approaches while naturally modeling uncertainty.
WxC-Bench: A Novel Dataset for Weather and Climate Downstream Tasks
Dec 03, 2024



High-quality machine learning (ML)-ready datasets play a foundational role in developing new artificial intelligence (AI) models or fine-tuning existing models for scientific applications such as weather and climate analysis. Unfortunately, despite the growing development of new deep learning models for weather and climate, there is a scarcity of curated, pre-processed machine learning (ML)-ready datasets. Curating such high-quality datasets for developing new models is challenging particularly because the modality of the input data varies significantly for different downstream tasks addressing different atmospheric scales (spatial and temporal). Here we introduce WxC-Bench (Weather and Climate Bench), a multi-modal dataset designed to support the development of generalizable AI models for downstream use-cases in weather and climate research. WxC-Bench is designed as a dataset of datasets for developing ML-models for a complex weather and climate system, addressing selected downstream tasks as machine learning phenomenon. WxC-Bench encompasses several atmospheric processes from meso-$\beta$ (20 - 200 km) scale to synoptic scales (2500 km), such as aviation turbulence, hurricane intensity and track monitoring, weather analog search, gravity wave parameterization, and natural language report generation. We provide a comprehensive description of the dataset and also present a technical validation for baseline analysis. The dataset and code to prepare the ML-ready data have been made publicly available on Hugging Face -- https://huggingface.co/datasets/nasa-impact/WxC-Bench
Cameras as Rays: Pose Estimation via Ray Diffusion
Feb 22, 2024



Estimating camera poses is a fundamental task for 3D reconstruction and remains challenging given sparse views (<10). In contrast to existing approaches that pursue top-down prediction of global parametrizations of camera extrinsics, we propose a distributed representation of camera pose that treats a camera as a bundle of rays. This representation allows for a tight coupling with spatial image features improving pose precision. We observe that this representation is naturally suited for set-level level transformers and develop a regression-based approach that maps image patches to corresponding rays. To capture the inherent uncertainties in sparse-view pose inference, we adapt this approach to learn a denoising diffusion model which allows us to sample plausible modes while improving performance. Our proposed methods, both regression- and diffusion-based, demonstrate state-of-the-art performance on camera pose estimation on CO3D while generalizing to unseen object categories and in-the-wild captures.
RelPose++: Recovering 6D Poses from Sparse-view Observations
May 08, 2023We address the task of estimating 6D camera poses from sparse-view image sets (2-8 images). This task is a vital pre-processing stage for nearly all contemporary (neural) reconstruction algorithms but remains challenging given sparse views, especially for objects with visual symmetries and texture-less surfaces. We build on the recent RelPose framework which learns a network that infers distributions over relative rotations over image pairs. We extend this approach in two key ways; first, we use attentional transformer layers to process multiple images jointly, since additional views of an object may resolve ambiguous symmetries in any given image pair (such as the handle of a mug that becomes visible in a third view). Second, we augment this network to also report camera translations by defining an appropriate coordinate system that decouples the ambiguity in rotation estimation from translation prediction. Our final system results in large improvements in 6D pose prediction over prior art on both seen and unseen object categories and also enables pose estimation and 3D reconstruction for in-the-wild objects.
A Real-World Demonstration of Machine Learning Generalizability: Intracranial Hemorrhage Detection on Head CT
Feb 09, 2021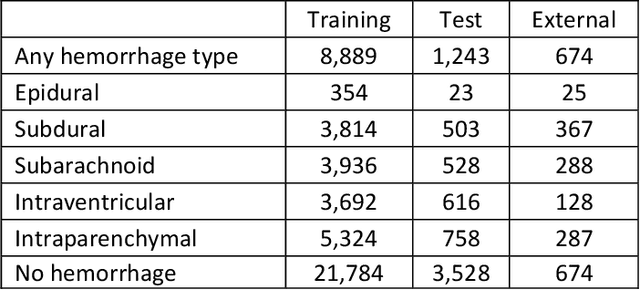

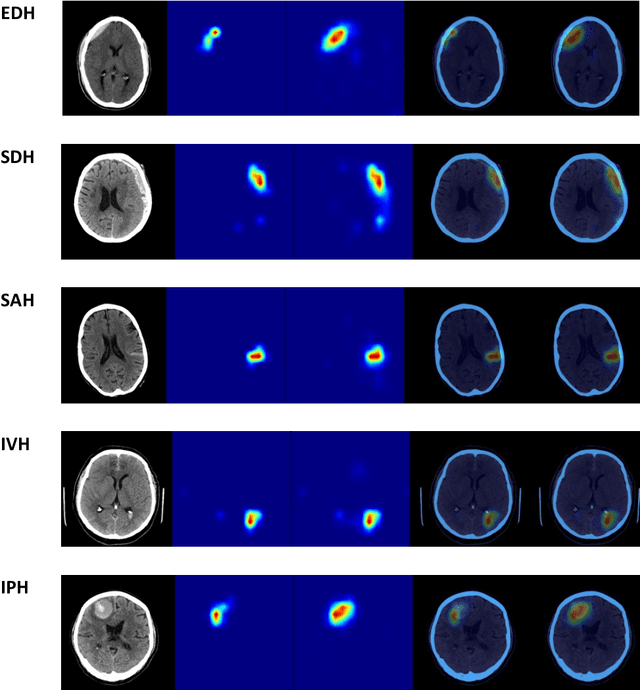

Machine learning (ML) holds great promise in transforming healthcare. While published studies have shown the utility of ML models in interpreting medical imaging examinations, these are often evaluated under laboratory settings. The importance of real world evaluation is best illustrated by case studies that have documented successes and failures in the translation of these models into clinical environments. A key prerequisite for the clinical adoption of these technologies is demonstrating generalizable ML model performance under real world circumstances. The purpose of this study was to demonstrate that ML model generalizability is achievable in medical imaging with the detection of intracranial hemorrhage (ICH) on non-contrast computed tomography (CT) scans serving as the use case. An ML model was trained using 21,784 scans from the RSNA Intracranial Hemorrhage CT dataset while generalizability was evaluated using an external validation dataset obtained from our busy trauma and neurosurgical center. This real world external validation dataset consisted of every unenhanced head CT scan (n = 5,965) performed in our emergency department in 2019 without exclusion. The model demonstrated an AUC of 98.4%, sensitivity of 98.8%, and specificity of 98.0%, on the test dataset. On external validation, the model demonstrated an AUC of 95.4%, sensitivity of 91.3%, and specificity of 94.1%. Evaluating the ML model using a real world external validation dataset that is temporally and geographically distinct from the training dataset indicates that ML generalizability is achievable in medical imaging applications.