 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinetuning AI Foundation Models to Develop Subgrid-Scale Parameterizations: A Case Study on Atmospheric Gravity Waves
Sep 04, 2025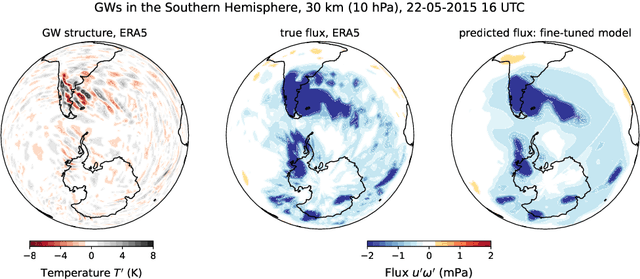



Global climate models parameterize a range of atmospheric-oceanic processes like gravity waves, clouds, moist convection, and turbulence that cannot be sufficiently resolved. These subgrid-scale closures for unresolved processes are a leading source of model uncertainty. Here, we present a new approach to developing machine learning parameterizations of small-scale climate processes by fine-tuning a pre-trained AI foundation model (FM). FMs are largely unexplored in climate research. A pre-trained encoder-decoder from a 2.3 billion parameter FM (NASA and IBM Research's Prithvi WxC) -- which contains a latent probabilistic representation of atmospheric evolution -- is fine-tuned (or reused) to create a deep learning parameterization for atmospheric gravity waves (GWs). The parameterization captures GW effects for a coarse-resolution climate model by learning the fluxes from an atmospheric reanalysis with 10 times finer resolution. A comparison of monthly averages and instantaneous evolution with a machine learning model baseline (an Attention U-Net) reveals superior predictive performance of the FM parameterization throughout the atmosphere, even in regions excluded from pre-training. This performance boost is quantified using the Hellinger distance, which is 0.11 for the baseline and 0.06 for the fine-tuned model. Our findings emphasize the versatility and reusability of FMs, which could be used to accomplish a range of atmosphere- and climate-related applications, leading the way for the creation of observations-driven and physically accurate parameterizations for more earth-system processes.
WxC-Bench: A Novel Dataset for Weather and Climate Downstream Tasks
Dec 03, 2024



High-quality machine learning (ML)-ready datasets play a foundational role in developing new artificial intelligence (AI) models or fine-tuning existing models for scientific applications such as weather and climate analysis. Unfortunately, despite the growing development of new deep learning models for weather and climate, there is a scarcity of curated, pre-processed machine learning (ML)-ready datasets. Curating such high-quality datasets for developing new models is challenging particularly because the modality of the input data varies significantly for different downstream tasks addressing different atmospheric scales (spatial and temporal). Here we introduce WxC-Bench (Weather and Climate Bench), a multi-modal dataset designed to support the development of generalizable AI models for downstream use-cases in weather and climate research. WxC-Bench is designed as a dataset of datasets for developing ML-models for a complex weather and climate system, addressing selected downstream tasks as machine learning phenomenon. WxC-Bench encompasses several atmospheric processes from meso-$\beta$ (20 - 200 km) scale to synoptic scales (2500 km), such as aviation turbulence, hurricane intensity and track monitoring, weather analog search, gravity wave parameterization, and natural language report generation. We provide a comprehensive description of the dataset and also present a technical validation for baseline analysis. The dataset and code to prepare the ML-ready data have been made publicly available on Hugging Face -- https://huggingface.co/datasets/nasa-impact/WxC-Bench
Machine Learning Global Simulation of Nonlocal Gravity Wave Propagation
Jun 20, 2024Global climate models typically operate at a grid resolution of hundreds of kilometers and fail to resolve atmospheric mesoscale processes, e.g., clouds, precipitation, and gravity waves (GWs). Model representation of these processes and their sources is essential to the global circulation and planetary energy budget, but subgrid scale contributions from these processes are often only approximately represented in models using parameterizations. These parameterizations are subject to approximations and idealizations, which limit their capability and accuracy. The most drastic of these approximations is the "single-column approximation" which completely neglects the horizontal evolution of these processes, resulting in key biases in current climate models. With a focus on atmospheric GWs, we present the first-ever global simulation of atmospheric GW fluxes using machine learning (ML) models trained on the WINDSET dataset to emulate global GW emulation in the atmosphere, as an alternative to traditional single-column parameterizations. Using an Attention U-Net-based architecture trained on globally resolved GW momentum fluxes, we illustrate the importance and effectiveness of global nonlocality, when simulating GWs using data-driven schemes.
CLUE: Contextualised Unified Explainable Learning of User Engagement in Video Lectures
Jan 14, 2022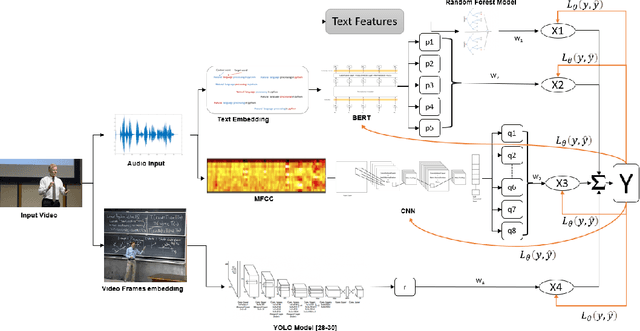
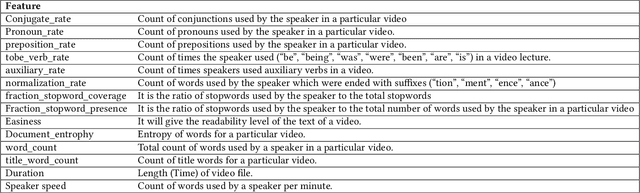
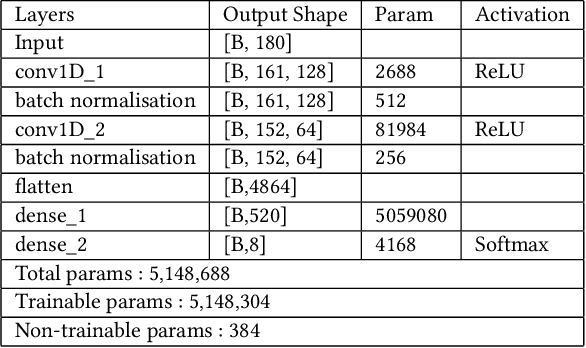
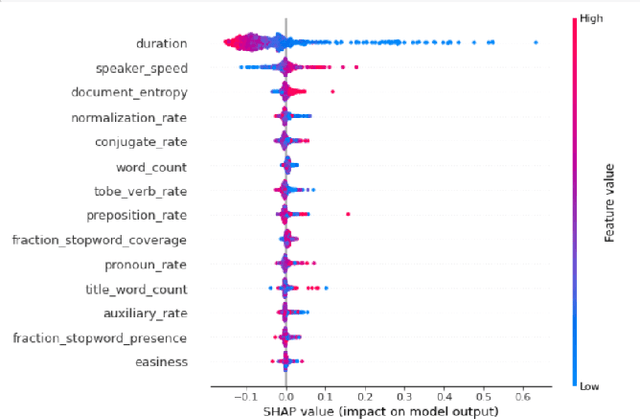
Predicting contextualised engagement in videos is a long-standing problem that has been popularly attempted by exploiting the number of views or the associated likes using different computational methods. The recent decade has seen a boom in online learning resources, and during the pandemic, there has been an exponential rise of online teaching videos without much quality control. The quality of the content could be improved if the creators could get constructive feedback on their content. Employing an army of domain expert volunteers to provide feedback on the videos might not scale. As a result, there has been a steep rise in developing computational methods to predict a user engagement score that is indicative of some form of possible user engagement, i.e., to what level a user would tend to engage with the content. A drawback in current methods is that they model various features separately, in a cascaded approach, that is prone to error propagation. Besides, most of them do not provide crucial explanations on how the creator could improve their content. In this paper, we have proposed a new unified model, CLUE for the educational domain, which learns from the features extracted from freely available public online teaching videos and provides explainable feedback on the video along with a user engagement score. Given the complexity of the task, our unified framework employs different pre-trained models working together as an ensemble of classifiers. Our model exploits various multi-modal features to model the complexity of language, context agnostic information, textual emotion of the delivered content, animation, speaker's pitch and speech emotions. Under a transfer learning setup, the overall model, in the unified space, is fine-tuned for downstream applications.