 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnCommon Objects in 3D
Jan 13, 2025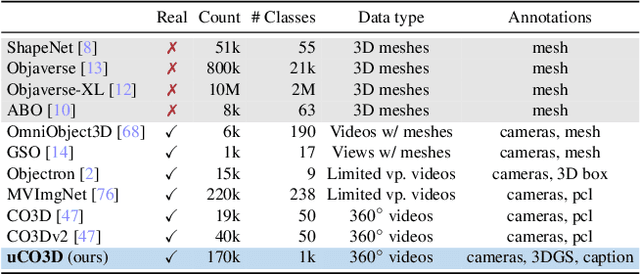


We introduce Uncommon Objects in 3D (uCO3D), a new object-centric dataset for 3D deep learning and 3D generative AI. uCO3D is the largest publicly-available collection of high-resolution videos of objects with 3D annotations that ensures full-360$^{\circ}$ coverage. uCO3D is significantly more diverse than MVImgNet and CO3Dv2, covering more than 1,000 object categories. It is also of higher quality, due to extensive quality checks of both the collected videos and the 3D annotations. Similar to analogous datasets, uCO3D contains annotations for 3D camera poses, depth maps and sparse point clouds. In addition, each object is equipped with a caption and a 3D Gaussian Splat reconstruction. We train several large 3D models on MVImgNet, CO3Dv2, and uCO3D and obtain superior results using the latter, showing that uCO3D is better for learning applications.
Meta 3D Gen
Jul 02, 2024


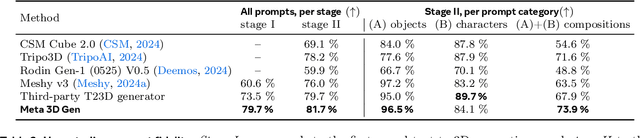
We introduce Meta 3D Gen (3DGen), a new state-of-the-art, fast pipeline for text-to-3D asset generation. 3DGen offers 3D asset creation with high prompt fidelity and high-quality 3D shapes and textures in under a minute. It supports physically-based rendering (PBR), necessary for 3D asset relighting in real-world applications. Additionally, 3DGen supports generative retexturing of previously generated (or artist-created) 3D shapes using additional textual inputs provided by the user. 3DGen integrates key technical components, Meta 3D AssetGen and Meta 3D TextureGen, that we developed for text-to-3D and text-to-texture generation, respectively. By combining their strengths, 3DGen represents 3D objects simultaneously in three ways: in view space, in volumetric space, and in UV (or texture) space. The integration of these two techniques achieves a win rate of 68% with respect to the single-stage model. We compare 3DGen to numerous industry baselines, and show that it outperforms them in terms of prompt fidelity and visual quality for complex textual prompts, while being significantly faster.
Move Anything with Layered Scene Diffusion
Apr 10, 2024



Diffusion models generate images with an unprecedented level of quality, but how can we freely rearrange image layouts? Recent works generate controllable scenes via learning spatially disentangled latent codes, but these methods do not apply to diffusion models due to their fixed forward process. In this work, we propose SceneDiffusion to optimize a layered scene representation during the diffusion sampling process. Our key insight is that spatial disentanglement can be obtained by jointly denoising scene renderings at different spatial layouts. Our generated scenes support a wide range of spatial editing operations, including moving, resizing, cloning, and layer-wise appearance editing operations, including object restyling and replacing. Moreover, a scene can be generated conditioned on a reference image, thus enabling object moving for in-the-wild images. Notably, this approach is training-free, compatible with general text-to-image diffusion models, and responsive in less than a second.
Learning Garment DensePose for Robust Warping in Virtual Try-On
Mar 30, 2023


Virtual try-on, i.e making people virtually try new garments, is an active research area in computer vision with great commercial applications. Current virtual try-on methods usually work in a two-stage pipeline. First, the garment image is warped on the person's pose using a flow estimation network. Then in the second stage, the warped garment is fused with the person image to render a new try-on image. Unfortunately, such methods are heavily dependent on the quality of the garment warping which often fails when dealing with hard poses (e.g., a person lifting or crossing arms). In this work, we propose a robust warping method for virtual try-on based on a learned garment DensePose which has a direct correspondence with the person's DensePose. Due to the lack of annotated data, we show how to leverage an off-the-shelf person DensePose model and a pretrained flow model to learn the garment DensePose in a weakly supervised manner. The garment DensePose allows a robust warping to any person's pose without any additional computation. Our method achieves the state-of-the-art equivalent on virtual try-on benchmarks and shows warping robustness on in-the-wild person images with hard poses, making it more suited for real-world virtual try-on applications.
Few-shot Action Recognition with Prototype-centered Attentive Learning
Feb 03, 2021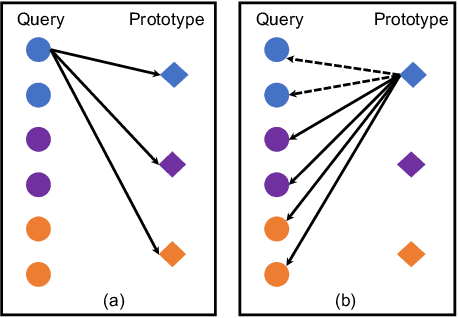
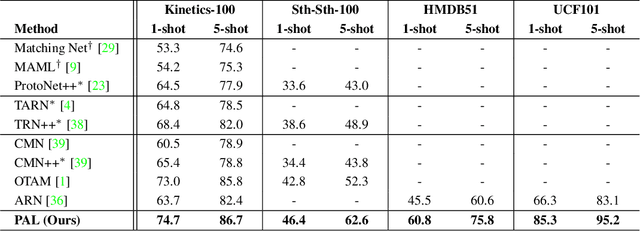
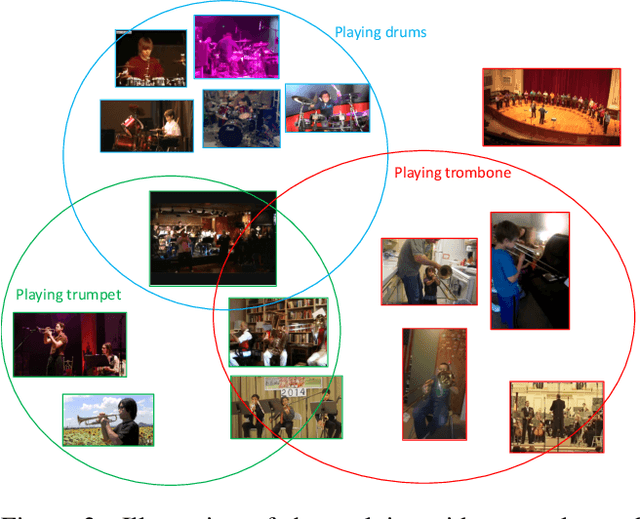
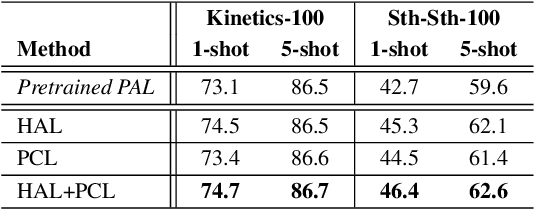
Few-shot action recognition aims to recognize action classes with few training samples. Most existing methods adopt a meta-learning approach with episodic training. In each episode, the few samples in a meta-training task are split into support and query sets. The former is used to build a classifier, which is then evaluated on the latter using a query-centered loss for model updating. There are however two major limitations: lack of data efficiency due to the query-centered only loss design and inability to deal with the support set outlying samples and inter-class distribution overlapping problems. In this paper, we overcome both limitations by proposing a new Prototype-centered Attentive Learning (PAL) model composed of two novel components. First, a prototype-centered contrastive learning loss is introduced to complement the conventional query-centered learning objective, in order to make full use of the limited training samples in each episode. Second, PAL further integrates a hybrid attentive learning mechanism that can minimize the negative impacts of outliers and promote class separation. Extensive experiments on four standard few-shot action benchmarks show that our method clearly outperforms previous state-of-the-art methods, with the improvement particularly significant (10+\%) on the most challenging fine-grained action recognition benchmark.
Egocentric Action Recognition by Video Attention and Temporal Context
Jul 03, 2020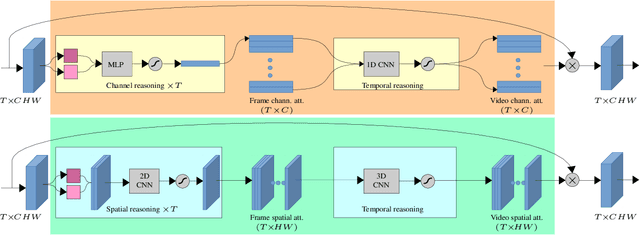

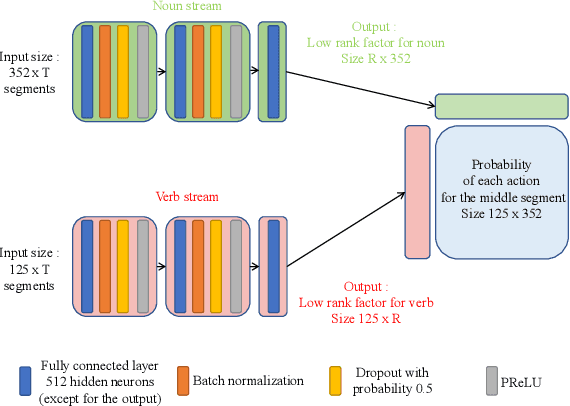
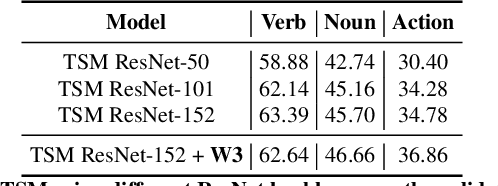
We present the submission of Samsung AI Centre Cambridge to the CVPR2020 EPIC-Kitchens Action Recognition Challenge. In this challenge, action recognition is posed as the problem of simultaneously predicting a single `verb' and `noun' class label given an input trimmed video clip. That is, a `verb' and a `noun' together define a compositional `action' class. The challenging aspects of this real-life action recognition task include small fast moving objects, complex hand-object interactions, and occlusions. At the core of our submission is a recently-proposed spatial-temporal video attention model, called `W3' (`What-Where-When') attention~\cite{perez2020knowing}. We further introduce a simple yet effective contextual learning mechanism to model `action' class scores directly from long-term temporal behaviour based on the `verb' and `noun' prediction scores. Our solution achieves strong performance on the challenge metrics without using object-specific reasoning nor extra training data. In particular, our best solution with multimodal ensemble achieves the 2$^{nd}$ best position for `verb', and 3$^{rd}$ best for `noun' and `action' on the Seen Kitchens test set.
Knowing What, Where and When to Look: Efficient Video Action Modeling with Attention
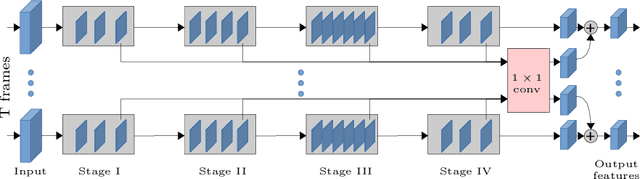
Apr 02, 2020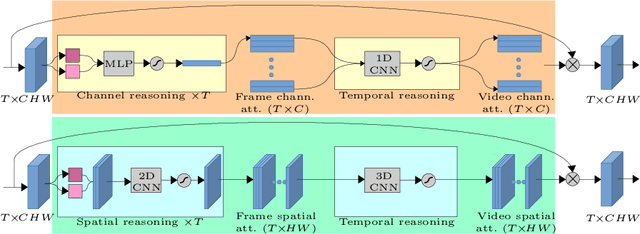

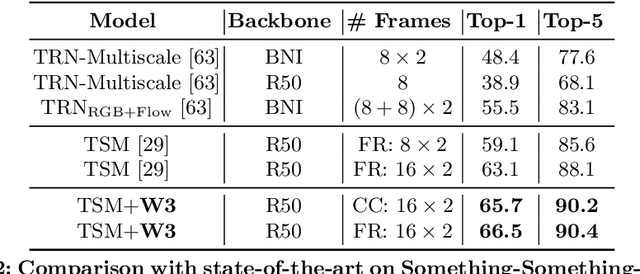
Attentive video modeling is essential for action recognition in unconstrained videos due to their rich yet redundant information over space and time. However, introducing attention in a deep neural network for action recognition is challenging for two reasons. First, an effective attention module needs to learn what (objects and their local motion patterns), where (spatially), and when (temporally) to focus on. Second, a video attention module must be efficient because existing action recognition models already suffer from high computational cost. To address both challenges, a novel What-Where-When (W3) video attention module is proposed. Departing from existing alternatives, our W3 module models all three facets of video attention jointly. Crucially, it is extremely efficient by factorizing the high-dimensional video feature data into low-dimensional meaningful spaces (1D channel vector for `what' and 2D spatial tensors for `where'), followed by lightweight temporal attention reasoning. Extensive experiments show that our attention model brings significant improvements to existing action recognition models, achieving new state-of-the-art performance on a number of benchmarks.