 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgocentric Action Recognition by Video Attention and Temporal Context
Paper and Code
Jul 03, 2020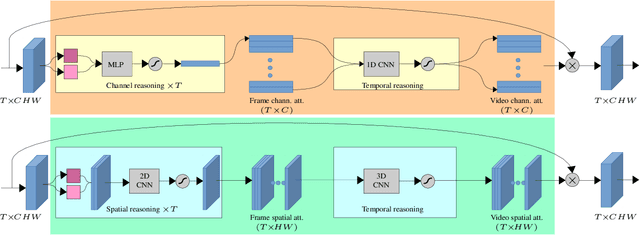

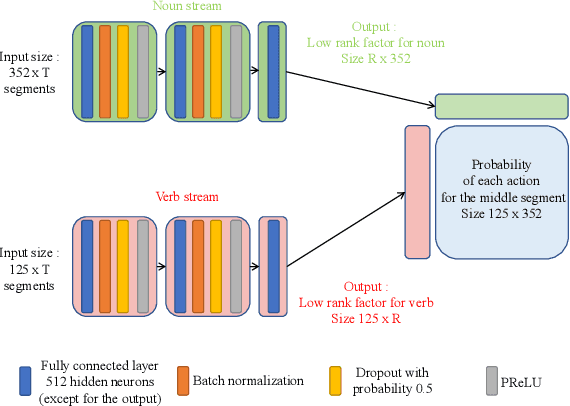
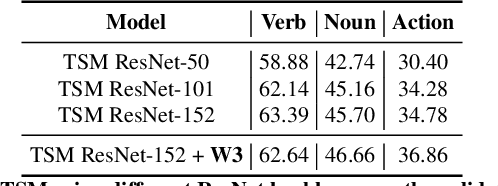
We present the submission of Samsung AI Centre Cambridge to the CVPR2020 EPIC-Kitchens Action Recognition Challenge. In this challenge, action recognition is posed as the problem of simultaneously predicting a single `verb' and `noun' class label given an input trimmed video clip. That is, a `verb' and a `noun' together define a compositional `action' class. The challenging aspects of this real-life action recognition task include small fast moving objects, complex hand-object interactions, and occlusions. At the core of our submission is a recently-proposed spatial-temporal video attention model, called `W3' (`What-Where-When') attention~\cite{perez2020knowing}. We further introduce a simple yet effective contextual learning mechanism to model `action' class scores directly from long-term temporal behaviour based on the `verb' and `noun' prediction scores. Our solution achieves strong performance on the challenge metrics without using object-specific reasoning nor extra training data. In particular, our best solution with multimodal ensemble achieves the 2$^{nd}$ best position for `verb', and 3$^{rd}$ best for `noun' and `action' on the Seen Kitchens test set.