 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarDini: Masked Autoregressive Diffusion for Video Generation at Scale
Oct 26, 2024



We introduce MarDini, a new family of video diffusion models that integrate the advantages of masked auto-regression (MAR) into a unified diffusion model (DM) framework. Here, MAR handles temporal planning, while DM focuses on spatial generation in an asymmetric network design: i) a MAR-based planning model containing most of the parameters generates planning signals for each masked frame using low-resolution input; ii) a lightweight generation model uses these signals to produce high-resolution frames via diffusion de-noising. MarDini's MAR enables video generation conditioned on any number of masked frames at any frame positions: a single model can handle video interpolation (e.g., masking middle frames), image-to-video generation (e.g., masking from the second frame onward), and video expansion (e.g., masking half the frames). The efficient design allocates most of the computational resources to the low-resolution planning model, making computationally expensive but important spatio-temporal attention feasible at scale. MarDini sets a new state-of-the-art for video interpolation; meanwhile, within few inference steps, it efficiently generates videos on par with those of much more expensive advanced image-to-video models.
Move Anything with Layered Scene Diffusion
Apr 10, 2024



Diffusion models generate images with an unprecedented level of quality, but how can we freely rearrange image layouts? Recent works generate controllable scenes via learning spatially disentangled latent codes, but these methods do not apply to diffusion models due to their fixed forward process. In this work, we propose SceneDiffusion to optimize a layered scene representation during the diffusion sampling process. Our key insight is that spatial disentanglement can be obtained by jointly denoising scene renderings at different spatial layouts. Our generated scenes support a wide range of spatial editing operations, including moving, resizing, cloning, and layer-wise appearance editing operations, including object restyling and replacing. Moreover, a scene can be generated conditioned on a reference image, thus enabling object moving for in-the-wild images. Notably, this approach is training-free, compatible with general text-to-image diffusion models, and responsive in less than a second.
Two-Stage Session-based Recommendations with Candidate Rank Embeddings
Aug 22, 2019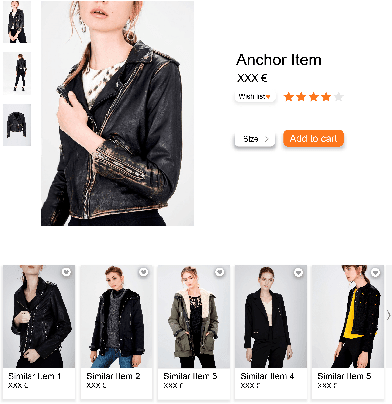
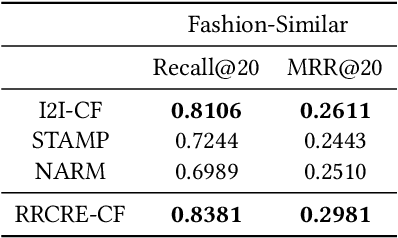
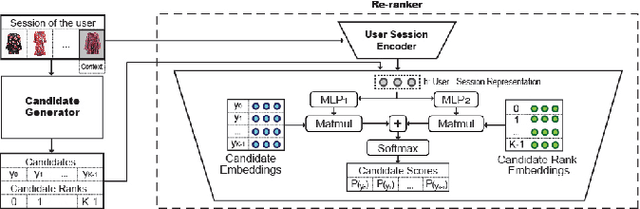
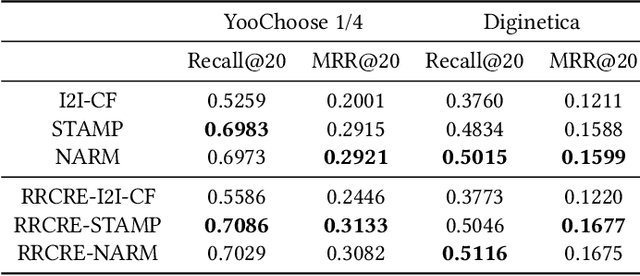
Recent advances in Session-based recommender systems have gained attention due to their potential of providing real-time personalized recommendations with high recall, especially when compared to traditional methods like matrix factorization and item-based collaborative filtering. Nowadays, two of the most recent methods are Short-Term Attention/Memory Priority Model for Session-based Recommendation (STAMP) and Neural Attentive Session-based Recommendation (NARM). However, when these two methods were applied in the similar-item recommendation dataset of Zalando (Fashion-Similar), they did not work out-of-the-box compared to a simple Collaborative-Filtering approach. Aiming for improving the similar-item recommendation, we propose to concentrate efforts on enhancing the rank of the few most relevant items from the original recommendations, by employing the information of the session of the user encoded by an attention network. The efficacy of this strategy was confirmed when using a novel Candidate Rank Embedding that encodes the global ranking information of each candidate in the re-ranking process. Experimental results in Fashion-Similar show significant improvements over the baseline on Recall and MRR at 20, as well as improvements in Click Through Rate based on an online test. Additionally, it is important to point out from the evaluation that was performed the potential of this method on the next click prediction problem because when applied to STAMP and NARM, it improves the Recall and MRR at 20 on two publicly available real-world datasets.