 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowing What, Where and When to Look: Efficient Video Action Modeling with Attention
Paper and Code
Apr 02, 2020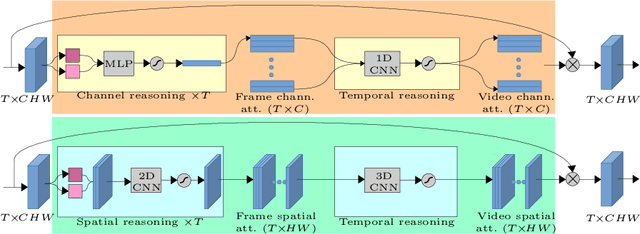

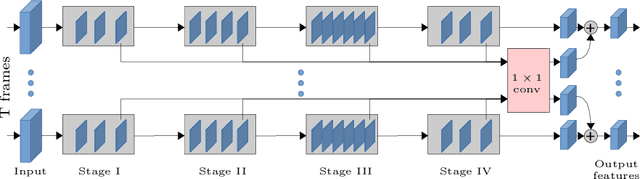
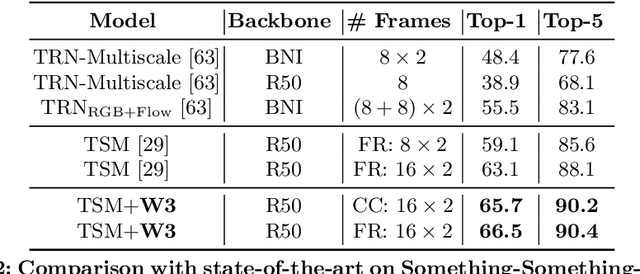
Attentive video modeling is essential for action recognition in unconstrained videos due to their rich yet redundant information over space and time. However, introducing attention in a deep neural network for action recognition is challenging for two reasons. First, an effective attention module needs to learn what (objects and their local motion patterns), where (spatially), and when (temporally) to focus on. Second, a video attention module must be efficient because existing action recognition models already suffer from high computational cost. To address both challenges, a novel What-Where-When (W3) video attention module is proposed. Departing from existing alternatives, our W3 module models all three facets of video attention jointly. Crucially, it is extremely efficient by factorizing the high-dimensional video feature data into low-dimensional meaningful spaces (1D channel vector for `what' and 2D spatial tensors for `where'), followed by lightweight temporal attention reasoning. Extensive experiments show that our attention model brings significant improvements to existing action recognition models, achieving new state-of-the-art performance on a number of benchmarks.