 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$\mathtt{emuflow}$: Normalising Flows for Joint Cosmological Analysis
Sep 02, 2024
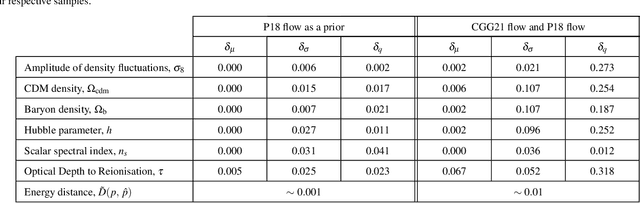
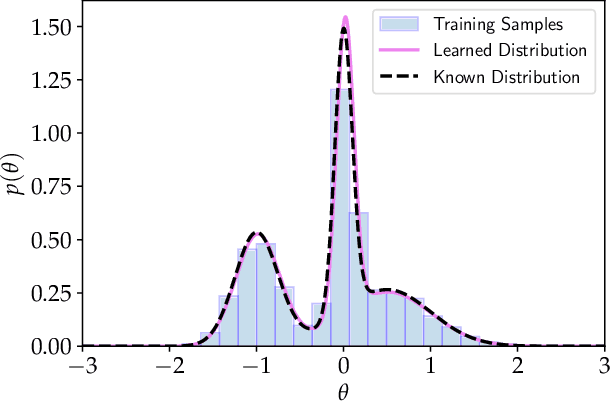
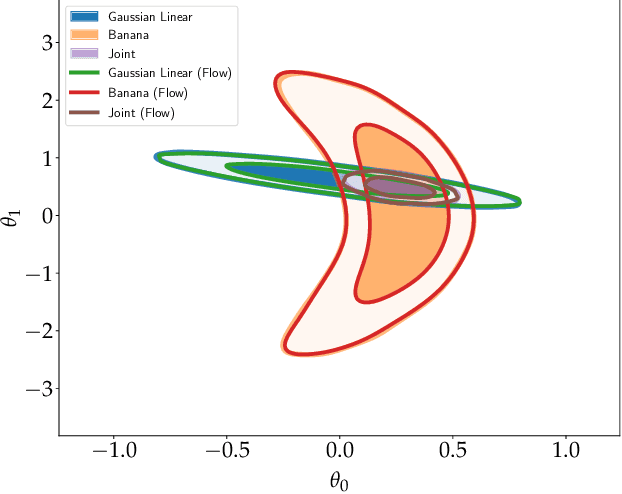
Given the growth in the variety and precision of astronomical datasets of interest for cosmology, the best cosmological constraints are invariably obtained by combining data from different experiments. At the likelihood level, one complication in doing so is the need to marginalise over large-dimensional parameter models describing the data of each experiment. These include both the relatively small number of cosmological parameters of interest and a large number of "nuisance" parameters. Sampling over the joint parameter space for multiple experiments can thus become a very computationally expensive operation. This can be significantly simplified if one could sample directly from the marginal cosmological posterior distribution of preceding experiments, depending only on the common set of cosmological parameters. In this paper, we show that this can be achieved by emulating marginal posterior distributions via normalising flows. The resulting trained normalising flow models can be used to efficiently combine cosmological constraints from independent datasets without increasing the dimensionality of the parameter space under study. We show that the method is able to accurately describe the posterior distribution of real cosmological datasets, as well as the joint distribution of different datasets, even when significant tension exists between experiments. The resulting joint constraints can be obtained in a fraction of the time it would take to combine the same datasets at the level of their likelihoods. We construct normalising flow models for a set of public cosmological datasets of general interests and make them available, together with the software used to train them, and to exploit them in cosmological parameter inference.
Imbalance Learning for Variable Star Classification
Feb 27, 2020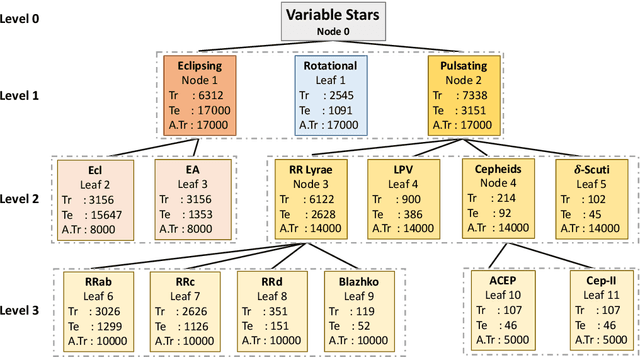

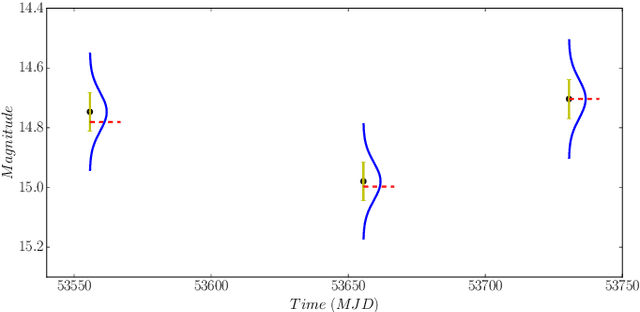
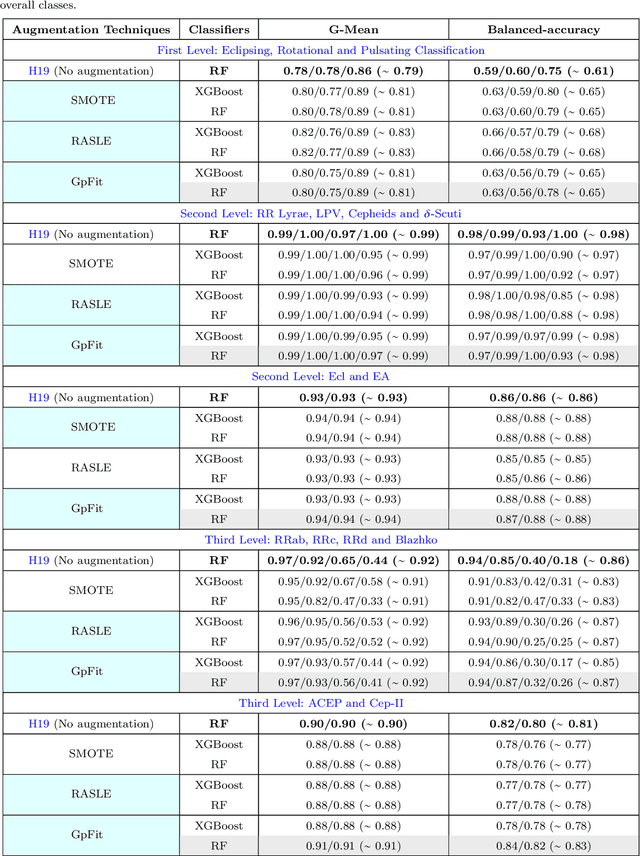
The accurate automated classification of variable stars into their respective sub-types is difficult. Machine learning based solutions often fall foul of the imbalanced learning problem, which causes poor generalisation performance in practice, especially on rare variable star sub-types. In previous work, we attempted to overcome such deficiencies via the development of a hierarchical machine learning classifier. This 'algorithm-level' approach to tackling imbalance, yielded promising results on Catalina Real-Time Survey (CRTS) data, outperforming the binary and multi-class classification schemes previously applied in this area. In this work, we attempt to further improve hierarchical classification performance by applying 'data-level' approaches to directly augment the training data so that they better describe under-represented classes. We apply and report results for three data augmentation methods in particular: $\textit{R}$andomly $\textit{A}$ugmented $\textit{S}$ampled $\textit{L}$ight curves from magnitude $\textit{E}$rror ($\texttt{RASLE}$), augmenting light curves with Gaussian Process modelling ($\texttt{GpFit}$) and the Synthetic Minority Over-sampling Technique ($\texttt{SMOTE}$). When combining the 'algorithm-level' (i.e. the hierarchical scheme) together with the 'data-level' approach, we further improve variable star classification accuracy by 1-4$\%$. We found that a higher classification rate is obtained when using $\texttt{GpFit}$ in the hierarchical model. Further improvement of the metric scores requires a better standard set of correctly identified variable stars and, perhaps enhanced features are needed.
Comparing Multi-class, Binary and Hierarchical Machine Learning Classification schemes for variable stars
Jul 18, 2019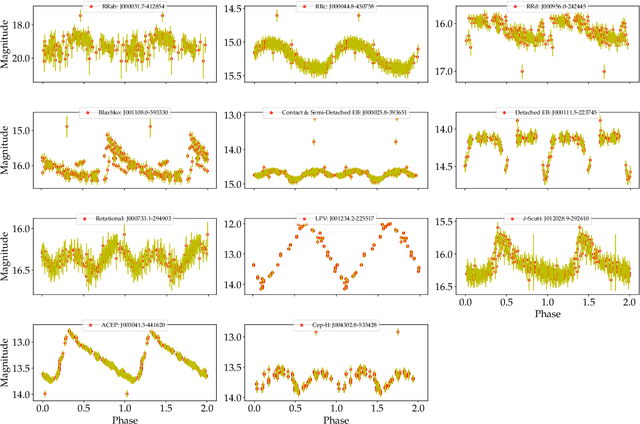

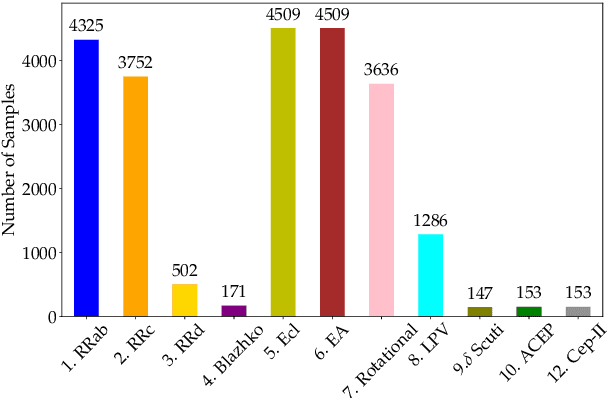
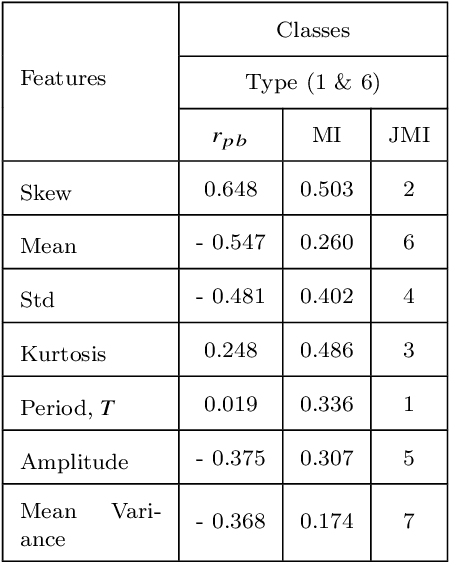
Upcoming synoptic surveys are set to generate an unprecedented amount of data. This requires an automatic framework that can quickly and efficiently provide classification labels for several new object classification challenges. Using data describing 11 types of variable stars from the Catalina Real-Time Transient Surveys (CRTS), we illustrate how to capture the most important information from computed features and describe detailed methods of how to robustly use Information Theory for feature selection and evaluation. We apply three Machine Learning (ML) algorithms and demonstrate how to optimize these classifiers via cross-validation techniques. For the CRTS dataset, we find that the Random Forest (RF) classifier performs best in terms of balanced-accuracy and geometric means. We demonstrate substantially improved classification results by converting the multi-class problem into a binary classification task, achieving a balanced-accuracy rate of $\sim$99 per cent for the classification of ${\delta}$-Scuti and Anomalous Cepheids (ACEP). Additionally, we describe how classification performance can be improved via converting a 'flat-multi-class' problem into a hierarchical taxonomy. We develop a new hierarchical structure and propose a new set of classification features, enabling the accurate identification of subtypes of cepheids, RR Lyrae and eclipsing binary stars in CRTS data.