 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImbalance Learning for Variable Star Classification
Paper and Code
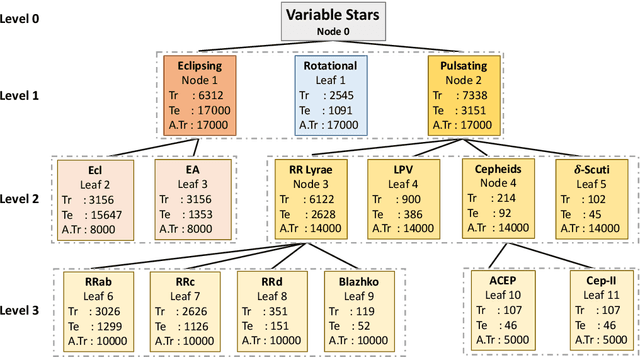

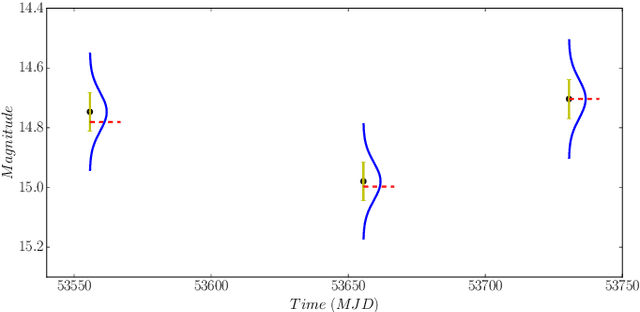
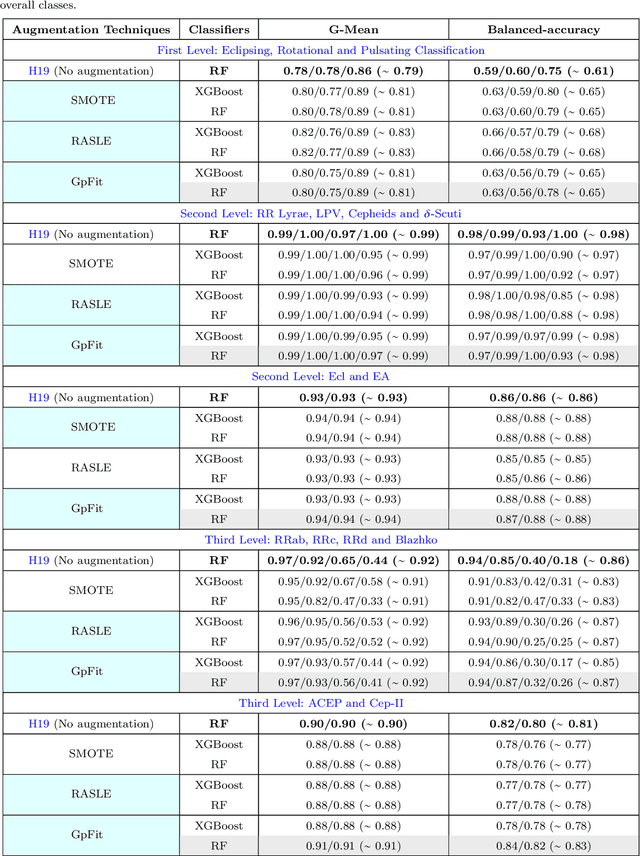
The accurate automated classification of variable stars into their respective sub-types is difficult. Machine learning based solutions often fall foul of the imbalanced learning problem, which causes poor generalisation performance in practice, especially on rare variable star sub-types. In previous work, we attempted to overcome such deficiencies via the development of a hierarchical machine learning classifier. This 'algorithm-level' approach to tackling imbalance, yielded promising results on Catalina Real-Time Survey (CRTS) data, outperforming the binary and multi-class classification schemes previously applied in this area. In this work, we attempt to further improve hierarchical classification performance by applying 'data-level' approaches to directly augment the training data so that they better describe under-represented classes. We apply and report results for three data augmentation methods in particular: $\textit{R}$andomly $\textit{A}$ugmented $\textit{S}$ampled $\textit{L}$ight curves from magnitude $\textit{E}$rror ($\texttt{RASLE}$), augmenting light curves with Gaussian Process modelling ($\texttt{GpFit}$) and the Synthetic Minority Over-sampling Technique ($\texttt{SMOTE}$). When combining the 'algorithm-level' (i.e. the hierarchical scheme) together with the 'data-level' approach, we further improve variable star classification accuracy by 1-4$\%$. We found that a higher classification rate is obtained when using $\texttt{GpFit}$ in the hierarchical model. Further improvement of the metric scores requires a better standard set of correctly identified variable stars and, perhaps enhanced features are needed.