 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpportunities in AI/ML for the Rubin LSST Dark Energy Science Collaboration
Jan 20, 2026The Vera C. Rubin Observatory's Legacy Survey of Space and Time (LSST) will produce unprecedented volumes of heterogeneous astronomical data (images, catalogs, and alerts) that challenge traditional analysis pipelines. The LSST Dark Energy Science Collaboration (DESC) aims to derive robust constraints on dark energy and dark matter from these data, requiring methods that are statistically powerful, scalable, and operationally reliable. Artificial intelligence and machine learning (AI/ML) are already embedded across DESC science workflows, from photometric redshifts and transient classification to weak lensing inference and cosmological simulations. Yet their utility for precision cosmology hinges on trustworthy uncertainty quantification, robustness to covariate shift and model misspecification, and reproducible integration within scientific pipelines. This white paper surveys the current landscape of AI/ML across DESC's primary cosmological probes and cross-cutting analyses, revealing that the same core methodologies and fundamental challenges recur across disparate science cases. Since progress on these cross-cutting challenges would benefit multiple probes simultaneously, we identify key methodological research priorities, including Bayesian inference at scale, physics-informed methods, validation frameworks, and active learning for discovery. With an eye on emerging techniques, we also explore the potential of the latest foundation model methodologies and LLM-driven agentic AI systems to reshape DESC workflows, provided their deployment is coupled with rigorous evaluation and governance. Finally, we discuss critical software, computing, data infrastructure, and human capital requirements for the successful deployment of these new methodologies, and consider associated risks and opportunities for broader coordination with external actors.
$\mathtt{emuflow}$: Normalising Flows for Joint Cosmological Analysis
Sep 02, 2024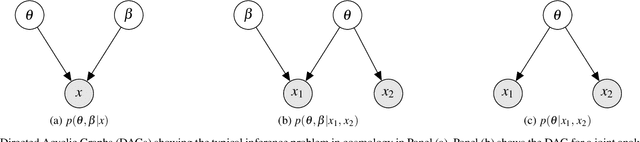
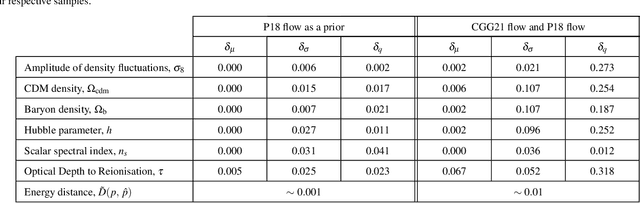
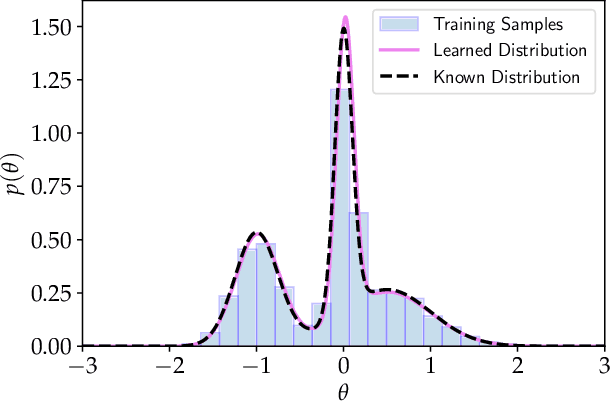
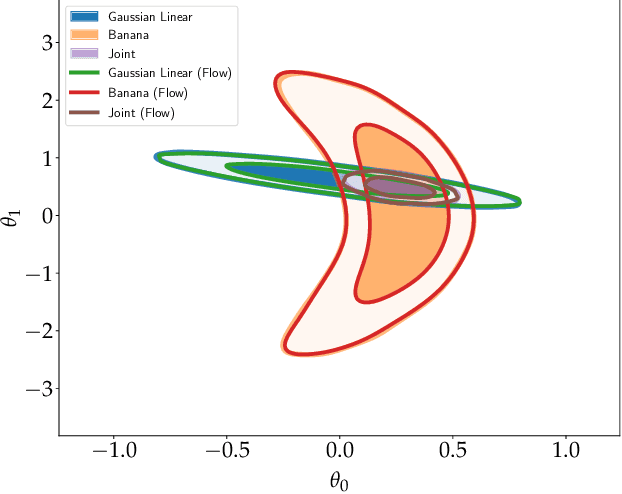
Given the growth in the variety and precision of astronomical datasets of interest for cosmology, the best cosmological constraints are invariably obtained by combining data from different experiments. At the likelihood level, one complication in doing so is the need to marginalise over large-dimensional parameter models describing the data of each experiment. These include both the relatively small number of cosmological parameters of interest and a large number of "nuisance" parameters. Sampling over the joint parameter space for multiple experiments can thus become a very computationally expensive operation. This can be significantly simplified if one could sample directly from the marginal cosmological posterior distribution of preceding experiments, depending only on the common set of cosmological parameters. In this paper, we show that this can be achieved by emulating marginal posterior distributions via normalising flows. The resulting trained normalising flow models can be used to efficiently combine cosmological constraints from independent datasets without increasing the dimensionality of the parameter space under study. We show that the method is able to accurately describe the posterior distribution of real cosmological datasets, as well as the joint distribution of different datasets, even when significant tension exists between experiments. The resulting joint constraints can be obtained in a fraction of the time it would take to combine the same datasets at the level of their likelihoods. We construct normalising flow models for a set of public cosmological datasets of general interests and make them available, together with the software used to train them, and to exploit them in cosmological parameter inference.