 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDGH: Dynamic Gaussian Hair
Dec 18, 2025The creation of photorealistic dynamic hair remains a major challenge in digital human modeling because of the complex motions, occlusions, and light scattering. Existing methods often resort to static capture and physics-based models that do not scale as they require manual parameter fine-tuning to handle the diversity of hairstyles and motions, and heavy computation to obtain high-quality appearance. In this paper, we present Dynamic Gaussian Hair (DGH), a novel framework that efficiently learns hair dynamics and appearance. We propose: (1) a coarse-to-fine model that learns temporally coherent hair motion dynamics across diverse hairstyles; (2) a strand-guided optimization module that learns a dynamic 3D Gaussian representation for hair appearance with support for differentiable rendering, enabling gradient-based learning of view-consistent appearance under motion. Unlike prior simulation-based pipelines, our approach is fully data-driven, scales with training data, and generalizes across various hairstyles and head motion sequences. Additionally, DGH can be seamlessly integrated into a 3D Gaussian avatar framework, enabling realistic, animatable hair for high-fidelity avatar representation. DGH achieves promising geometry and appearance results, providing a scalable, data-driven alternative to physics-based simulation and rendering.
3D-QAE: Fully Quantum Auto-Encoding of 3D Point Clouds
Nov 09, 2023



Existing methods for learning 3D representations are deep neural networks trained and tested on classical hardware. Quantum machine learning architectures, despite their theoretically predicted advantages in terms of speed and the representational capacity, have so far not been considered for this problem nor for tasks involving 3D data in general. This paper thus introduces the first quantum auto-encoder for 3D point clouds. Our 3D-QAE approach is fully quantum, i.e. all its data processing components are designed for quantum hardware. It is trained on collections of 3D point clouds to produce their compressed representations. Along with finding a suitable architecture, the core challenges in designing such a fully quantum model include 3D data normalisation and parameter optimisation, and we propose solutions for both these tasks. Experiments on simulated gate-based quantum hardware demonstrate that our method outperforms simple classical baselines, paving the way for a new research direction in 3D computer vision. The source code is available at https://4dqv.mpi-inf.mpg.de/QAE3D/.
* 20 pages, 11 figures, 5 tables
SceNeRFlow: Time-Consistent Reconstruction of General Dynamic Scenes
Aug 16, 2023



Existing methods for the 4D reconstruction of general, non-rigidly deforming objects focus on novel-view synthesis and neglect correspondences. However, time consistency enables advanced downstream tasks like 3D editing, motion analysis, or virtual-asset creation. We propose SceNeRFlow to reconstruct a general, non-rigid scene in a time-consistent manner. Our dynamic-NeRF method takes multi-view RGB videos and background images from static cameras with known camera parameters as input. It then reconstructs the deformations of an estimated canonical model of the geometry and appearance in an online fashion. Since this canonical model is time-invariant, we obtain correspondences even for long-term, long-range motions. We employ neural scene representations to parametrize the components of our method. Like prior dynamic-NeRF methods, we use a backwards deformation model. We find non-trivial adaptations of this model necessary to handle larger motions: We decompose the deformations into a strongly regularized coarse component and a weakly regularized fine component, where the coarse component also extends the deformation field into the space surrounding the object, which enables tracking over time. We show experimentally that, unlike prior work that only handles small motion, our method enables the reconstruction of studio-scale motions.
CCuantuMM: Cycle-Consistent Quantum-Hybrid Matching of Multiple Shapes
Mar 28, 2023

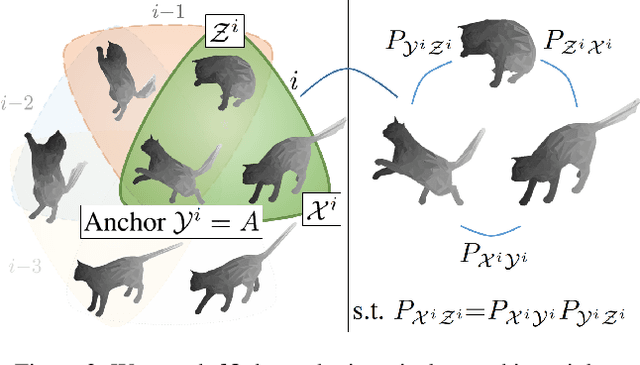

Jointly matching multiple, non-rigidly deformed 3D shapes is a challenging, $\mathcal{NP}$-hard problem. A perfect matching is necessarily cycle-consistent: Following the pairwise point correspondences along several shapes must end up at the starting vertex of the original shape. Unfortunately, existing quantum shape-matching methods do not support multiple shapes and even less cycle consistency. This paper addresses the open challenges and introduces the first quantum-hybrid approach for 3D shape multi-matching; in addition, it is also cycle-consistent. Its iterative formulation is admissible to modern adiabatic quantum hardware and scales linearly with the total number of input shapes. Both these characteristics are achieved by reducing the $N$-shape case to a sequence of three-shape matchings, the derivation of which is our main technical contribution. Thanks to quantum annealing, high-quality solutions with low energy are retrieved for the intermediate $\mathcal{NP}$-hard objectives. On benchmark datasets, the proposed approach significantly outperforms extensions to multi-shape matching of a previous quantum-hybrid two-shape matching method and is on-par with classical multi-matching methods.
State of the Art in Dense Monocular Non-Rigid 3D Reconstruction
Oct 27, 20223D reconstruction of deformable (or non-rigid) scenes from a set of monocular 2D image observations is a long-standing and actively researched area of computer vision and graphics. It is an ill-posed inverse problem, since--without additional prior assumptions--it permits infinitely many solutions leading to accurate projection to the input 2D images. Non-rigid reconstruction is a foundational building block for downstream applications like robotics, AR/VR, or visual content creation. The key advantage of using monocular cameras is their omnipresence and availability to the end users as well as their ease of use compared to more sophisticated camera set-ups such as stereo or multi-view systems. This survey focuses on state-of-the-art methods for dense non-rigid 3D reconstruction of various deformable objects and composite scenes from monocular videos or sets of monocular views. It reviews the fundamentals of 3D reconstruction and deformation modeling from 2D image observations. We then start from general methods--that handle arbitrary scenes and make only a few prior assumptions--and proceed towards techniques making stronger assumptions about the observed objects and types of deformations (e.g. human faces, bodies, hands, and animals). A significant part of this STAR is also devoted to classification and a high-level comparison of the methods, as well as an overview of the datasets for training and evaluation of the discussed techniques. We conclude by discussing open challenges in the field and the social aspects associated with the usage of the reviewed methods.
QuAnt: Quantum Annealing with Learnt Couplings
Oct 13, 2022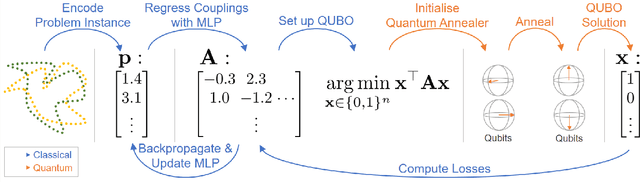
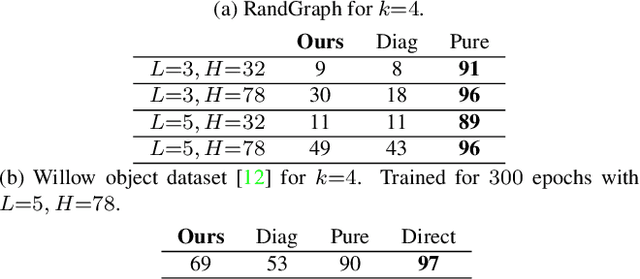
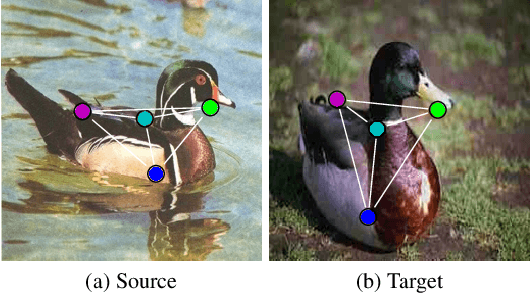
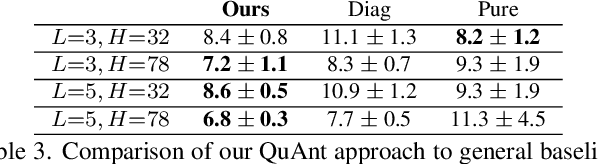
Modern quantum annealers can find high-quality solutions to combinatorial optimisation objectives given as quadratic unconstrained binary optimisation (QUBO) problems. Unfortunately, obtaining suitable QUBO forms in computer vision remains challenging and currently requires problem-specific analytical derivations. Moreover, such explicit formulations impose tangible constraints on solution encodings. In stark contrast to prior work, this paper proposes to learn QUBO forms from data through gradient backpropagation instead of deriving them. As a result, the solution encodings can be chosen flexibly and compactly. Furthermore, our methodology is general and virtually independent of the specifics of the target problem type. We demonstrate the advantages of learnt QUBOs on the diverse problem types of graph matching, 2D point cloud alignment and 3D rotation estimation. Our results are competitive with the previous quantum state of the art while requiring much fewer logical and physical qubits, enabling our method to scale to larger problems. The code and the new dataset will be open-sourced.
φ-SfT: Shape-from-Template with a Physics-Based Deformation Model
Mar 22, 2022

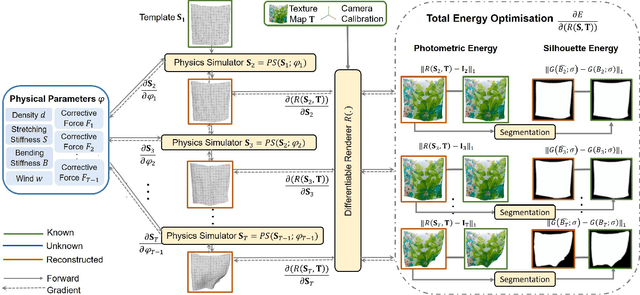
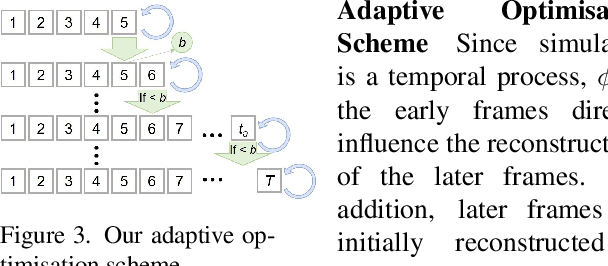
Shape-from-Template (SfT) methods estimate 3D surface deformations from a single monocular RGB camera while assuming a 3D state known in advance (a template). This is an important yet challenging problem due to the under-constrained nature of the monocular setting. Existing SfT techniques predominantly use geometric and simplified deformation models, which often limits their reconstruction abilities. In contrast to previous works, this paper proposes a new SfT approach explaining 2D observations through physical simulations accounting for forces and material properties. Our differentiable physics simulator regularises the surface evolution and optimises the material elastic properties such as bending coefficients, stretching stiffness and density. We use a differentiable renderer to minimise the dense reprojection error between the estimated 3D states and the input images and recover the deformation parameters using an adaptive gradient-based optimisation. For the evaluation, we record with an RGB-D camera challenging real surfaces exposed to physical forces with various material properties and textures. Our approach significantly reduces the 3D reconstruction error compared to multiple competing methods. For the source code and data, see https://4dqv.mpi-inf.mpg.de/phi-SfT/.