 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Sparse Networks Using Targeted Dropout
Paper and Code

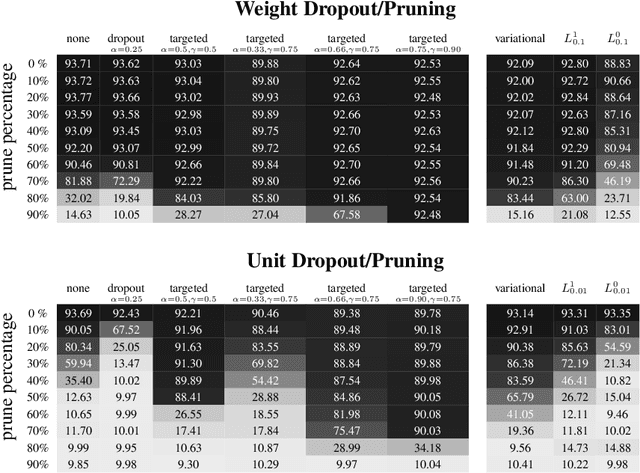
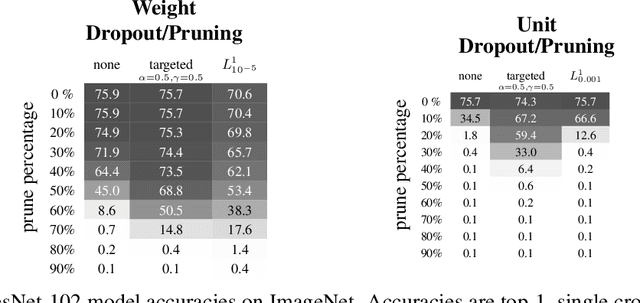
Neural networks are easier to optimise when they have many more weights than are required for modelling the mapping from inputs to outputs. This suggests a two-stage learning procedure that first learns a large net and then prunes away connections or hidden units. But standard training does not necessarily encourage nets to be amenable to pruning. We introduce targeted dropout, a method for training a neural network so that it is robust to subsequent pruning. Before computing the gradients for each weight update, targeted dropout stochastically selects a set of units or weights to be dropped using a simple self-reinforcing sparsity criterion and then computes the gradients for the remaining weights. The resulting network is robust to post hoc pruning of weights or units that frequently occur in the dropped sets. The method improves upon more complicated sparsifying regularisers while being simple to implement and easy to tune.