 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOPT-IML: Scaling Language Model Instruction Meta Learning through the Lens of Generalization
Dec 28, 2022



Recent work has shown that fine-tuning large pre-trained language models on a collection of tasks described via instructions, a.k.a. instruction-tuning, improves their zero and few-shot generalization to unseen tasks. However, there is a limited understanding of the performance trade-offs of different decisions made during the instruction-tuning process. These decisions include the scale and diversity of the instruction-tuning benchmark, different task sampling strategies, fine-tuning with and without demonstrations, training using specialized datasets for reasoning and dialogue, and finally, the fine-tuning objectives themselves. In this paper, we characterize the effect of instruction-tuning decisions on downstream task performance when scaling both model and benchmark sizes. To this end, we create OPT-IML Bench: a large benchmark for Instruction Meta-Learning (IML) of 2000 NLP tasks consolidated into task categories from 8 existing benchmarks, and prepare an evaluation framework to measure three types of model generalizations: to tasks from fully held-out categories, to held-out tasks from seen categories, and to held-out instances from seen tasks. Through the lens of this framework, we first present insights about instruction-tuning decisions as applied to OPT-30B and further exploit these insights to train OPT-IML 30B and 175B, which are instruction-tuned versions of OPT. OPT-IML demonstrates all three generalization abilities at both scales on four different evaluation benchmarks with diverse tasks and input formats -- PromptSource, FLAN, Super-NaturalInstructions, and UnifiedSKG. Not only does it significantly outperform OPT on all benchmarks but is also highly competitive with existing models fine-tuned on each specific benchmark. We release OPT-IML at both scales, together with the OPT-IML Bench evaluation framework.
Large scale distributed neural network training through online distillation
Apr 09, 2018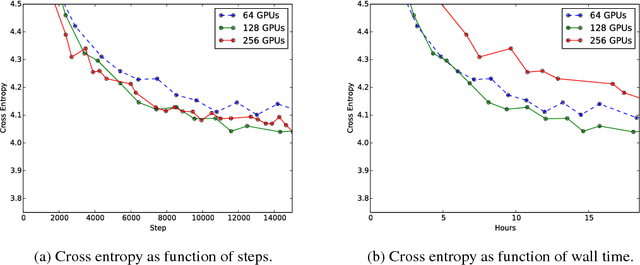

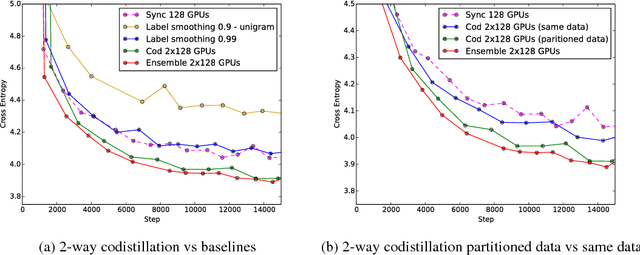
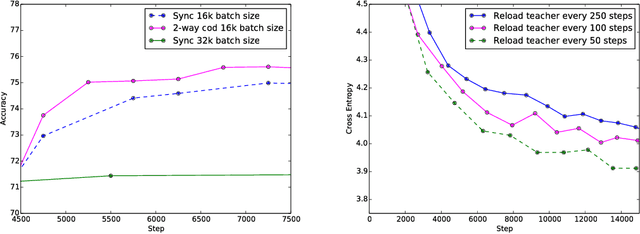
Techniques such as ensembling and distillation promise model quality improvements when paired with almost any base model. However, due to increased test-time cost (for ensembles) and increased complexity of the training pipeline (for distillation), these techniques are challenging to use in industrial settings. In this paper we explore a variant of distillation which is relatively straightforward to use as it does not require a complicated multi-stage setup or many new hyperparameters. Our first claim is that online distillation enables us to use extra parallelism to fit very large datasets about twice as fast. Crucially, we can still speed up training even after we have already reached the point at which additional parallelism provides no benefit for synchronous or asynchronous stochastic gradient descent. Two neural networks trained on disjoint subsets of the data can share knowledge by encouraging each model to agree with the predictions the other model would have made. These predictions can come from a stale version of the other model so they can be safely computed using weights that only rarely get transmitted. Our second claim is that online distillation is a cost-effective way to make the exact predictions of a model dramatically more reproducible. We support our claims using experiments on the Criteo Display Ad Challenge dataset, ImageNet, and the largest to-date dataset used for neural language modeling, containing $6\times 10^{11}$ tokens and based on the Common Crawl repository of web data.
Regularizing Neural Networks by Penalizing Confident Output Distributions
Jan 23, 2017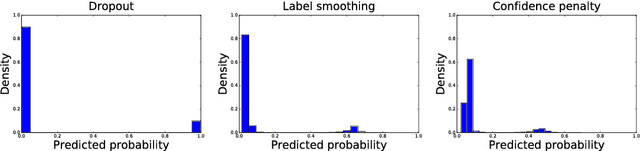


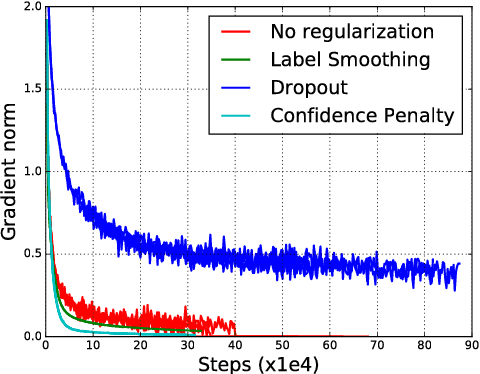
We systematically explore regularizing neural networks by penalizing low entropy output distributions. We show that penalizing low entropy output distributions, which has been shown to improve exploration in reinforcement learning, acts as a strong regularizer in supervised learning. Furthermore, we connect a maximum entropy based confidence penalty to label smoothing through the direction of the KL divergence. We exhaustively evaluate the proposed confidence penalty and label smoothing on 6 common benchmarks: image classification (MNIST and Cifar-10), language modeling (Penn Treebank), machine translation (WMT'14 English-to-German), and speech recognition (TIMIT and WSJ). We find that both label smoothing and the confidence penalty improve state-of-the-art models across benchmarks without modifying existing hyperparameters, suggesting the wide applicability of these regularizers.
Batch Normalized Recurrent Neural Networks
Oct 05, 2015
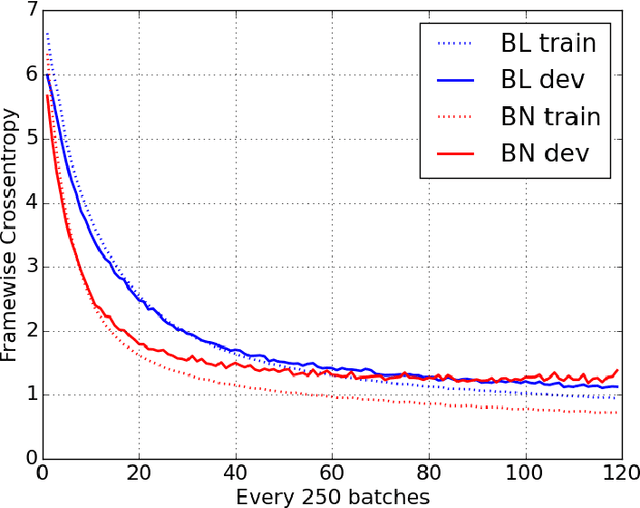
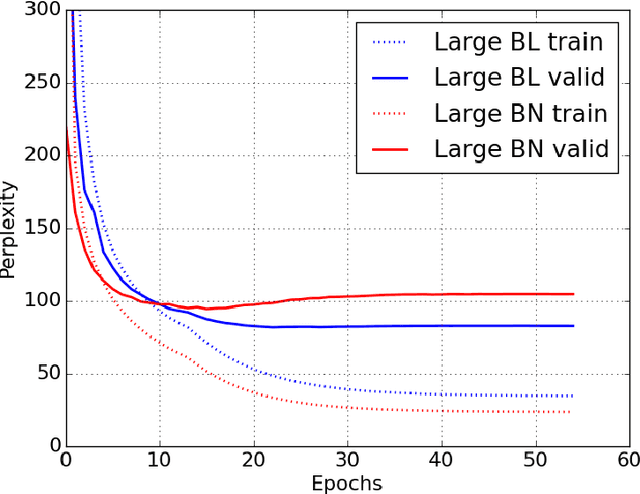
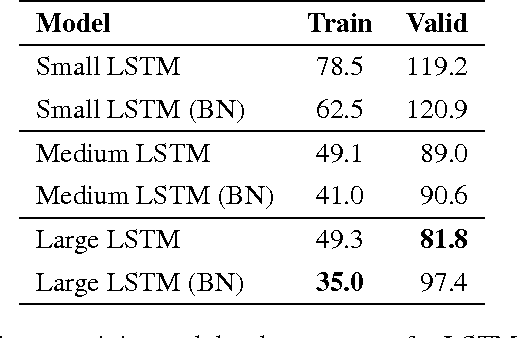
Recurrent Neural Networks (RNNs) are powerful models for sequential data that have the potential to learn long-term dependencies. However, they are computationally expensive to train and difficult to parallelize. Recent work has shown that normalizing intermediate representations of neural networks can significantly improve convergence rates in feedforward neural networks . In particular, batch normalization, which uses mini-batch statistics to standardize features, was shown to significantly reduce training time. In this paper, we show that applying batch normalization to the hidden-to-hidden transitions of our RNNs doesn't help the training procedure. We also show that when applied to the input-to-hidden transitions, batch normalization can lead to a faster convergence of the training criterion but doesn't seem to improve the generalization performance on both our language modelling and speech recognition tasks. All in all, applying batch normalization to RNNs turns out to be more challenging than applying it to feedforward networks, but certain variants of it can still be beneficial.