 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvariant Representations for Noisy Speech Recognition
Nov 27, 2016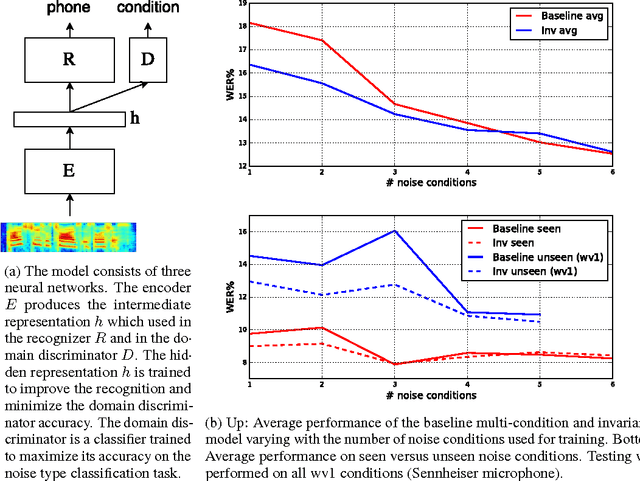
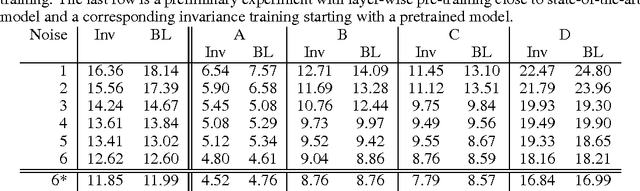
Modern automatic speech recognition (ASR) systems need to be robust under acoustic variability arising from environmental, speaker, channel, and recording conditions. Ensuring such robustness to variability is a challenge in modern day neural network-based ASR systems, especially when all types of variability are not seen during training. We attempt to address this problem by encouraging the neural network acoustic model to learn invariant feature representations. We use ideas from recent research on image generation using Generative Adversarial Networks and domain adaptation ideas extending adversarial gradient-based training. A recent work from Ganin et al. proposes to use adversarial training for image domain adaptation by using an intermediate representation from the main target classification network to deteriorate the domain classifier performance through a separate neural network. Our work focuses on investigating neural architectures which produce representations invariant to noise conditions for ASR. We evaluate the proposed architecture on the Aurora-4 task, a popular benchmark for noise robust ASR. We show that our method generalizes better than the standard multi-condition training especially when only a few noise categories are seen during training.
Task Loss Estimation for Sequence Prediction
Jan 19, 2016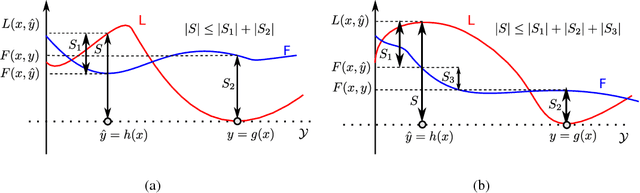
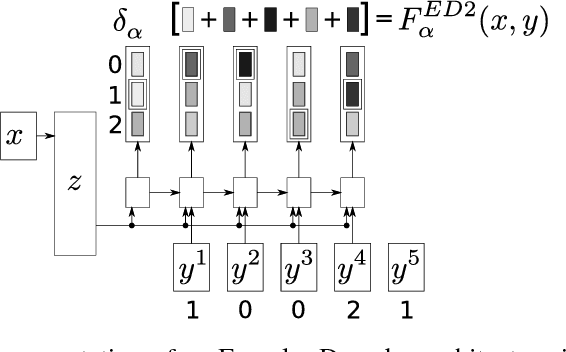
Often, the performance on a supervised machine learning task is evaluated with a emph{task loss} function that cannot be optimized directly. Examples of such loss functions include the classification error, the edit distance and the BLEU score. A common workaround for this problem is to instead optimize a emph{surrogate loss} function, such as for instance cross-entropy or hinge loss. In order for this remedy to be effective, it is important to ensure that minimization of the surrogate loss results in minimization of the task loss, a condition that we call emph{consistency with the task loss}. In this work, we propose another method for deriving differentiable surrogate losses that provably meet this requirement. We focus on the broad class of models that define a score for every input-output pair. Our idea is that this score can be interpreted as an estimate of the task loss, and that the estimation error may be used as a consistent surrogate loss. A distinct feature of such an approach is that it defines the desirable value of the score for every input-output pair. We use this property to design specialized surrogate losses for Encoder-Decoder models often used for sequence prediction tasks. In our experiment, we benchmark on the task of speech recognition. Using a new surrogate loss instead of cross-entropy to train an Encoder-Decoder speech recognizer brings a significant ~13% relative improvement in terms of Character Error Rate (CER) in the case when no extra corpora are used for language modeling.
Batch Normalized Recurrent Neural Networks
Oct 05, 2015
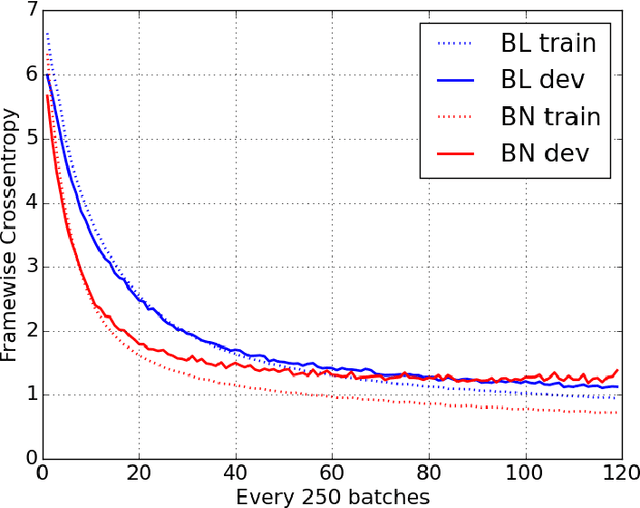
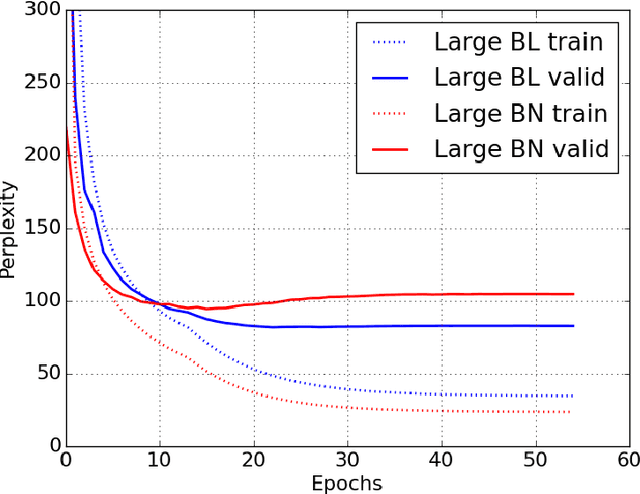
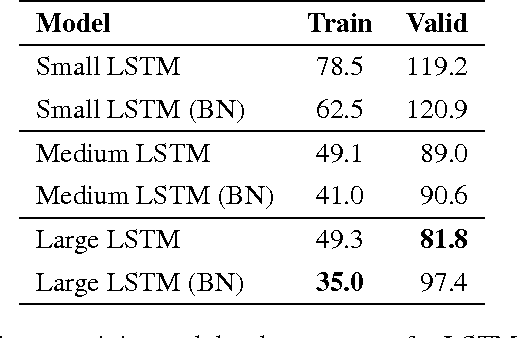
Recurrent Neural Networks (RNNs) are powerful models for sequential data that have the potential to learn long-term dependencies. However, they are computationally expensive to train and difficult to parallelize. Recent work has shown that normalizing intermediate representations of neural networks can significantly improve convergence rates in feedforward neural networks . In particular, batch normalization, which uses mini-batch statistics to standardize features, was shown to significantly reduce training time. In this paper, we show that applying batch normalization to the hidden-to-hidden transitions of our RNNs doesn't help the training procedure. We also show that when applied to the input-to-hidden transitions, batch normalization can lead to a faster convergence of the training criterion but doesn't seem to improve the generalization performance on both our language modelling and speech recognition tasks. All in all, applying batch normalization to RNNs turns out to be more challenging than applying it to feedforward networks, but certain variants of it can still be beneficial.