 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBatch Normalized Recurrent Neural Networks
Paper and Code
Oct 05, 2015
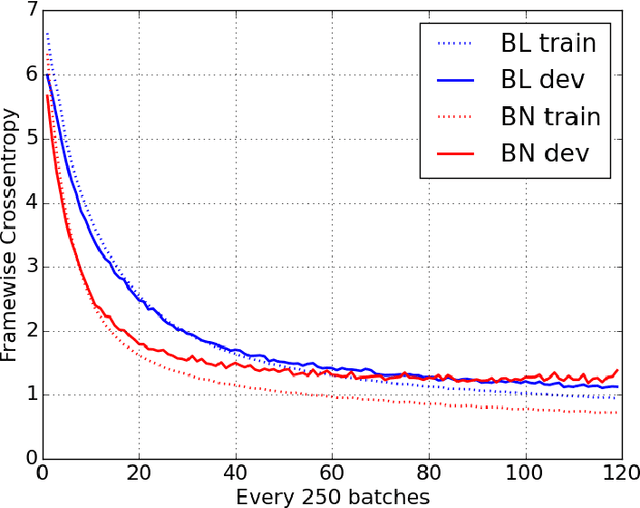
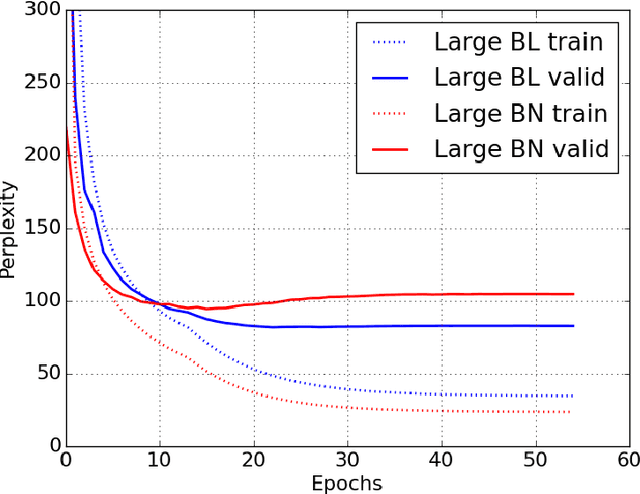
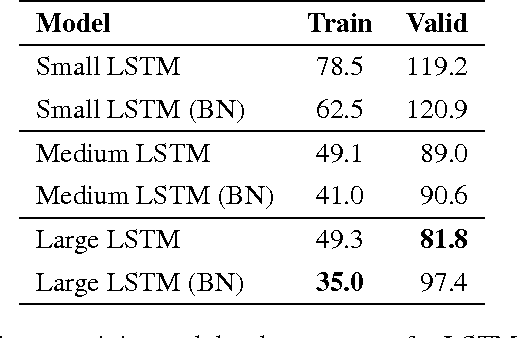
Recurrent Neural Networks (RNNs) are powerful models for sequential data that have the potential to learn long-term dependencies. However, they are computationally expensive to train and difficult to parallelize. Recent work has shown that normalizing intermediate representations of neural networks can significantly improve convergence rates in feedforward neural networks . In particular, batch normalization, which uses mini-batch statistics to standardize features, was shown to significantly reduce training time. In this paper, we show that applying batch normalization to the hidden-to-hidden transitions of our RNNs doesn't help the training procedure. We also show that when applied to the input-to-hidden transitions, batch normalization can lead to a faster convergence of the training criterion but doesn't seem to improve the generalization performance on both our language modelling and speech recognition tasks. All in all, applying batch normalization to RNNs turns out to be more challenging than applying it to feedforward networks, but certain variants of it can still be beneficial.