 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWebRED: Effective Pretraining And Finetuning For Relation Extraction On The Web
Feb 18, 2021

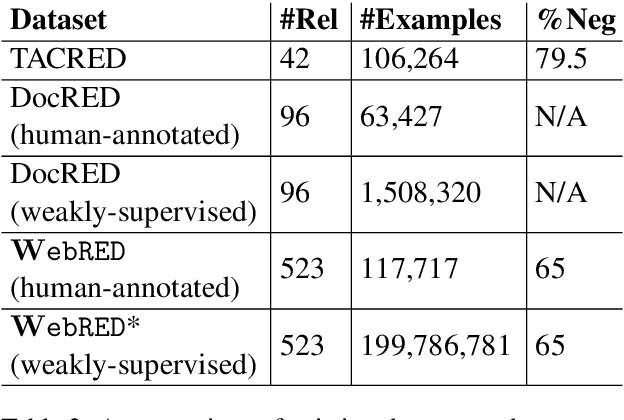
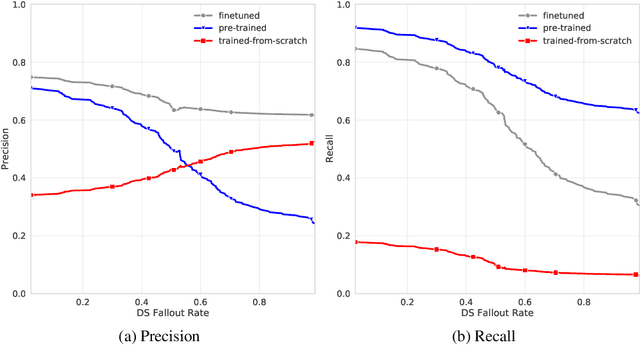
Relation extraction is used to populate knowledge bases that are important to many applications. Prior datasets used to train relation extraction models either suffer from noisy labels due to distant supervision, are limited to certain domains or are too small to train high-capacity models. This constrains downstream applications of relation extraction. We therefore introduce: WebRED (Web Relation Extraction Dataset), a strongly-supervised human annotated dataset for extracting relationships from a variety of text found on the World Wide Web, consisting of ~110K examples. We also describe the methods we used to collect ~200M examples as pre-training data for this task. We show that combining pre-training on a large weakly supervised dataset with fine-tuning on a small strongly-supervised dataset leads to better relation extraction performance. We provide baselines for this new dataset and present a case for the importance of human annotation in improving the performance of relation extraction from text found on the web.
Large scale distributed neural network training through online distillation
Apr 09, 2018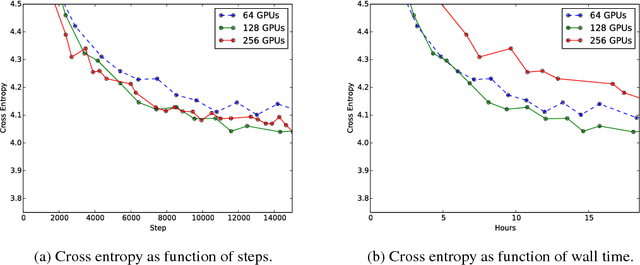

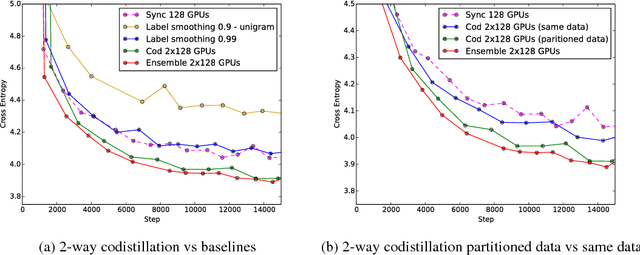
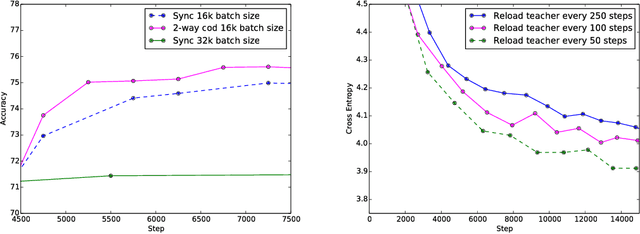
Techniques such as ensembling and distillation promise model quality improvements when paired with almost any base model. However, due to increased test-time cost (for ensembles) and increased complexity of the training pipeline (for distillation), these techniques are challenging to use in industrial settings. In this paper we explore a variant of distillation which is relatively straightforward to use as it does not require a complicated multi-stage setup or many new hyperparameters. Our first claim is that online distillation enables us to use extra parallelism to fit very large datasets about twice as fast. Crucially, we can still speed up training even after we have already reached the point at which additional parallelism provides no benefit for synchronous or asynchronous stochastic gradient descent. Two neural networks trained on disjoint subsets of the data can share knowledge by encouraging each model to agree with the predictions the other model would have made. These predictions can come from a stale version of the other model so they can be safely computed using weights that only rarely get transmitted. Our second claim is that online distillation is a cost-effective way to make the exact predictions of a model dramatically more reproducible. We support our claims using experiments on the Criteo Display Ad Challenge dataset, ImageNet, and the largest to-date dataset used for neural language modeling, containing $6\times 10^{11}$ tokens and based on the Common Crawl repository of web data.