 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuthenticated Workflows: A Systems Approach to Protecting Agentic AI
Feb 11, 2026Agentic AI systems automate enterprise workflows but existing defenses--guardrails, semantic filters--are probabilistic and routinely bypassed. We introduce authenticated workflows, the first complete trust layer for enterprise agentic AI. Security reduces to protecting four fundamental boundaries: prompts, tools, data, and context. We enforce intent (operations satisfy organizational policies) and integrity (operations are cryptographically authentic) at every boundary crossing, combining cryptographic elimination of attack classes with runtime policy enforcement. This delivers deterministic security--operations either carry valid cryptographic proof or are rejected. We introduce MAPL, an AI-native policy language that expresses agentic constraints dynamically as agents evolve and invocation context changes, scaling as O(log M + N) policies versus O(M x N) rules through hierarchical composition with cryptographic attestations for workflow dependencies. We prove practicality through a universal security runtime integrating nine leading frameworks (MCP, A2A, OpenAI, Claude, LangChain, CrewAI, AutoGen, LlamaIndex, Haystack) through thin adapters requiring zero protocol modifications. Formal proofs establish completeness and soundness. Empirical validation shows 100% recall with zero false positives across 174 test cases, protection against 9 of 10 OWASP Top 10 risks, and complete mitigation of two high impact production CVEs.
Protecting Context and Prompts: Deterministic Security for Non-Deterministic AI
Feb 11, 2026Large Language Model (LLM) applications are vulnerable to prompt injection and context manipulation attacks that traditional security models cannot prevent. We introduce two novel primitives--authenticated prompts and authenticated context--that provide cryptographically verifiable provenance across LLM workflows. Authenticated prompts enable self-contained lineage verification, while authenticated context uses tamper-evident hash chains to ensure integrity of dynamic inputs. Building on these primitives, we formalize a policy algebra with four proven theorems providing protocol-level Byzantine resistance--even adversarial agents cannot violate organizational policies. Five complementary defenses--from lightweight resource controls to LLM-based semantic validation--deliver layered, preventative security with formal guarantees. Evaluation against representative attacks spanning 6 exhaustive categories achieves 100% detection with zero false positives and nominal overhead. We demonstrate the first approach combining cryptographically enforced prompt lineage, tamper-evident context, and provable policy reasoning--shifting LLM security from reactive detection to preventative guarantees.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
NVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Distributed Multigrid Neural Solvers on Megavoxel Domains
Apr 29, 2021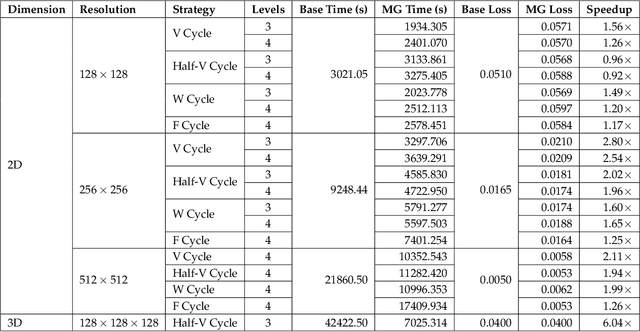


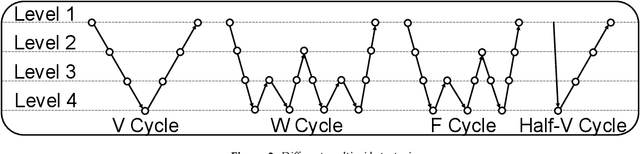
We consider the distributed training of large-scale neural networks that serve as PDE solvers producing full field outputs. We specifically consider neural solvers for the generalized 3D Poisson equation over megavoxel domains. A scalable framework is presented that integrates two distinct advances. First, we accelerate training a large model via a method analogous to the multigrid technique used in numerical linear algebra. Here, the network is trained using a hierarchy of increasing resolution inputs in sequence, analogous to the 'V', 'W', 'F', and 'Half-V' cycles used in multigrid approaches. In conjunction with the multi-grid approach, we implement a distributed deep learning framework which significantly reduces the time to solve. We show the scalability of this approach on both GPU (Azure VMs on Cloud) and CPU clusters (PSC Bridges2). This approach is deployed to train a generalized 3D Poisson solver that scales well to predict output full-field solutions up to the resolution of 512x512x512 for a high dimensional family of inputs.
WebRED: Effective Pretraining And Finetuning For Relation Extraction On The Web
Feb 18, 2021

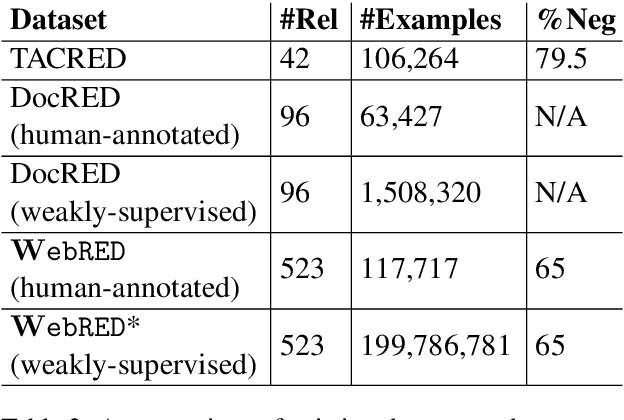
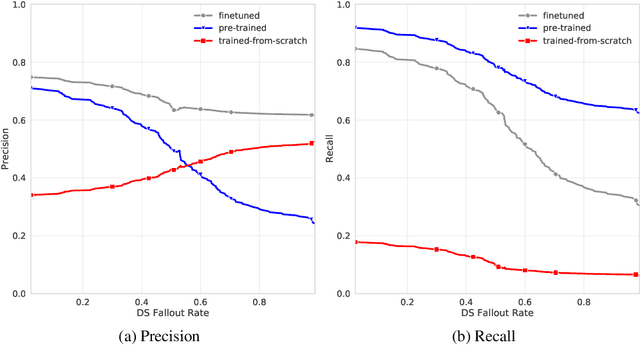
Relation extraction is used to populate knowledge bases that are important to many applications. Prior datasets used to train relation extraction models either suffer from noisy labels due to distant supervision, are limited to certain domains or are too small to train high-capacity models. This constrains downstream applications of relation extraction. We therefore introduce: WebRED (Web Relation Extraction Dataset), a strongly-supervised human annotated dataset for extracting relationships from a variety of text found on the World Wide Web, consisting of ~110K examples. We also describe the methods we used to collect ~200M examples as pre-training data for this task. We show that combining pre-training on a large weakly supervised dataset with fine-tuning on a small strongly-supervised dataset leads to better relation extraction performance. We provide baselines for this new dataset and present a case for the importance of human annotation in improving the performance of relation extraction from text found on the web.
Is Batch Norm unique? An empirical investigation and prescription to emulate the best properties of common normalizers without batch dependence
Oct 21, 2020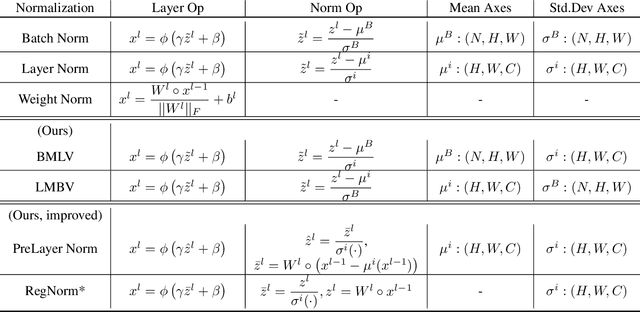
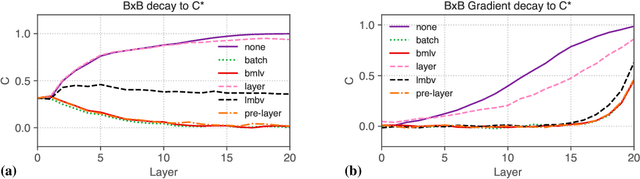
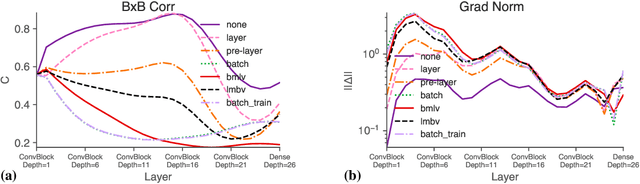
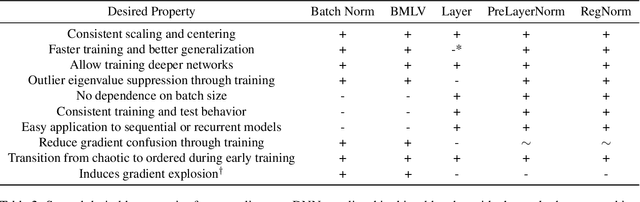
We perform an extensive empirical study of the statistical properties of Batch Norm and other common normalizers. This includes an examination of the correlation between representations of minibatches, gradient norms, and Hessian spectra both at initialization and over the course of training. Through this analysis, we identify several statistical properties which appear linked to Batch Norm's superior performance. We propose two simple normalizers, PreLayerNorm and RegNorm, which better match these desirable properties without involving operations along the batch dimension. We show that PreLayerNorm and RegNorm achieve much of the performance of Batch Norm without requiring batch dependence, that they reliably outperform LayerNorm, and that they can be applied in situations where Batch Norm is ineffective.
Assessing The Factual Accuracy of Generated Text
May 30, 2019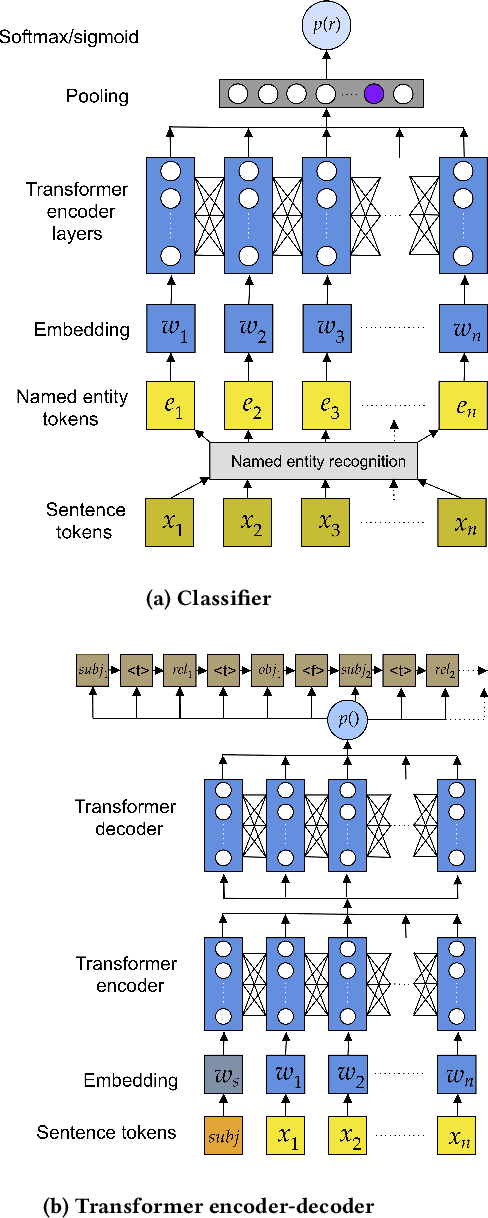
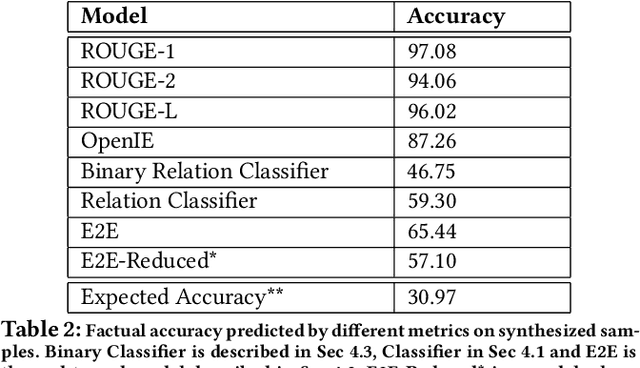

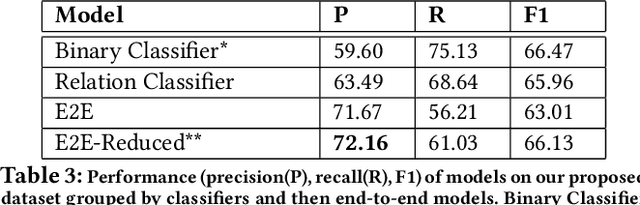
We propose a model-based metric to estimate the factual accuracy of generated text that is complementary to typical scoring schemes like ROUGE (Recall-Oriented Understudy for Gisting Evaluation) and BLEU (Bilingual Evaluation Understudy). We introduce and release a new large-scale dataset based on Wikipedia and Wikidata to train relation classifiers and end-to-end fact extraction models. The end-to-end models are shown to be able to extract complete sets of facts from datasets with full pages of text. We then analyse multiple models that estimate factual accuracy on a Wikipedia text summarization task, and show their efficacy compared to ROUGE and other model-free variants by conducting a human evaluation study.
A Mean Field Theory of Batch Normalization
Mar 05, 2019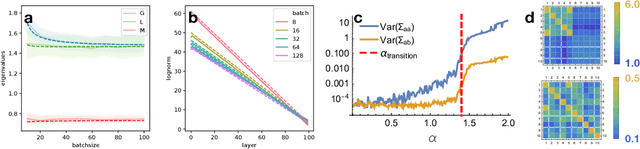
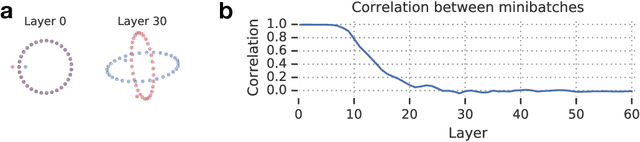
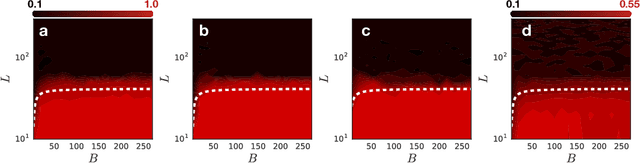
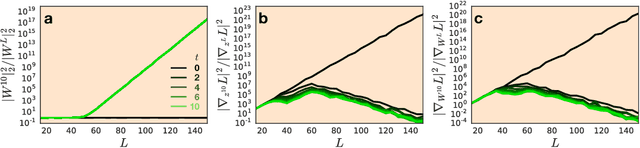
We develop a mean field theory for batch normalization in fully-connected feedforward neural networks. In so doing, we provide a precise characterization of signal propagation and gradient backpropagation in wide batch-normalized networks at initialization. Our theory shows that gradient signals grow exponentially in depth and that these exploding gradients cannot be eliminated by tuning the initial weight variances or by adjusting the nonlinear activation function. Indeed, batch normalization itself is the cause of gradient explosion. As a result, vanilla batch-normalized networks without skip connections are not trainable at large depths for common initialization schemes, a prediction that we verify with a variety of empirical simulations. While gradient explosion cannot be eliminated, it can be reduced by tuning the network close to the linear regime, which improves the trainability of deep batch-normalized networks without residual connections. Finally, we investigate the learning dynamics of batch-normalized networks and observe that after a single step of optimization the networks achieve a relatively stable equilibrium in which gradients have dramatically smaller dynamic range. Our theory leverages Laplace, Fourier, and Gegenbauer transforms and we derive new identities that may be of independent interest.
Reducing Bias in Production Speech Models
May 11, 2017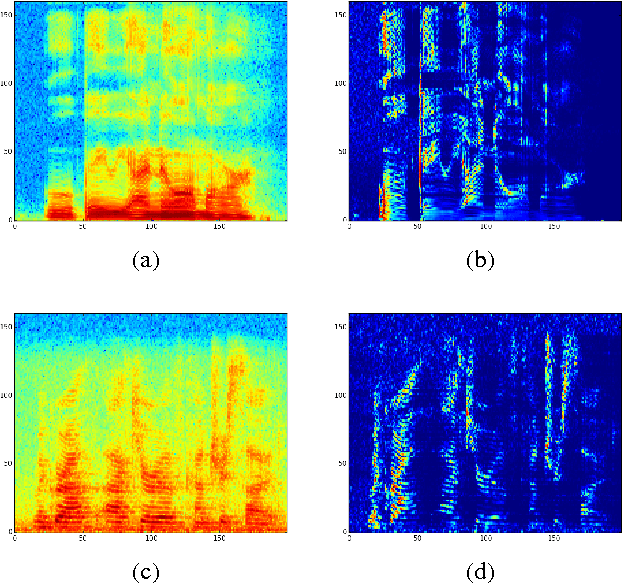
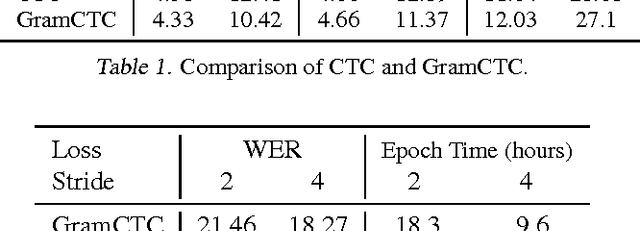
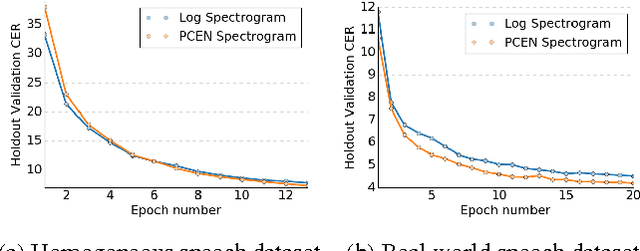
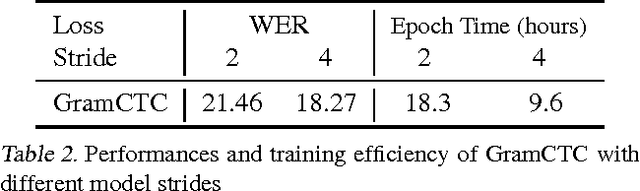
Replacing hand-engineered pipelines with end-to-end deep learning systems has enabled strong results in applications like speech and object recognition. However, the causality and latency constraints of production systems put end-to-end speech models back into the underfitting regime and expose biases in the model that we show cannot be overcome by "scaling up", i.e., training bigger models on more data. In this work we systematically identify and address sources of bias, reducing error rates by up to 20% while remaining practical for deployment. We achieve this by utilizing improved neural architectures for streaming inference, solving optimization issues, and employing strategies that increase audio and label modelling versatility.