 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Learning for Speech Recognition: the Power of Gradients
Paper and Code
Dec 10, 2016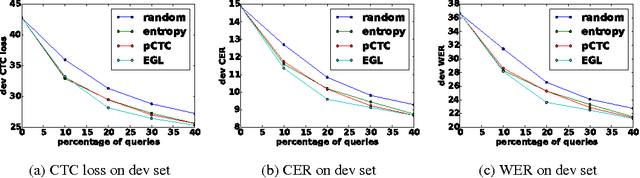
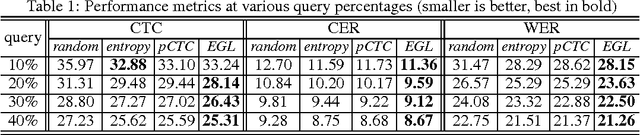
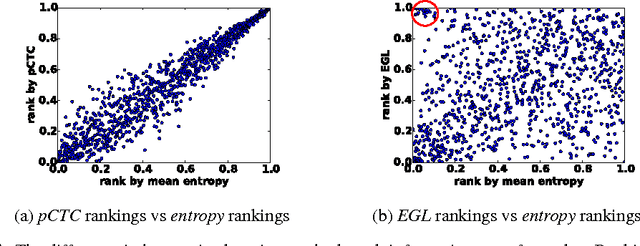
In training speech recognition systems, labeling audio clips can be expensive, and not all data is equally valuable. Active learning aims to label only the most informative samples to reduce cost. For speech recognition, confidence scores and other likelihood-based active learning methods have been shown to be effective. Gradient-based active learning methods, however, are still not well-understood. This work investigates the Expected Gradient Length (EGL) approach in active learning for end-to-end speech recognition. We justify EGL from a variance reduction perspective, and observe that EGL's measure of informativeness picks novel samples uncorrelated with confidence scores. Experimentally, we show that EGL can reduce word errors by 11\%, or alternatively, reduce the number of samples to label by 50\%, when compared to random sampling.