 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFISHING Net: Future Inference of Semantic Heatmaps In Grids
Jun 17, 2020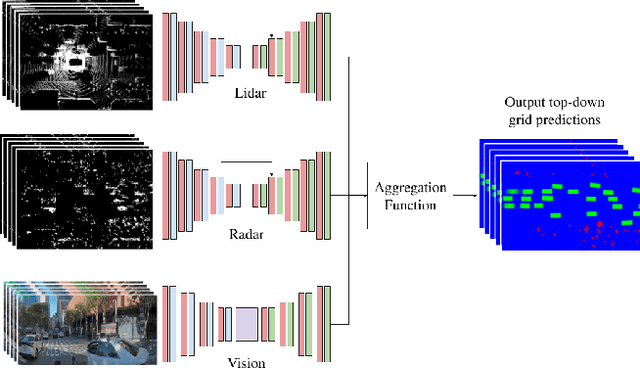
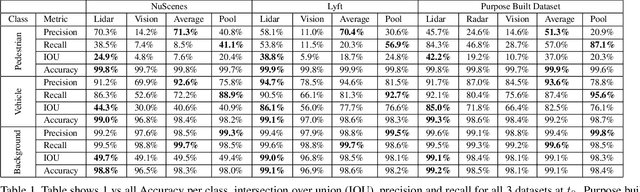

For autonomous robots to navigate a complex environment, it is crucial to understand the surrounding scene both geometrically and semantically. Modern autonomous robots employ multiple sets of sensors, including lidars, radars, and cameras. Managing the different reference frames and characteristics of the sensors, and merging their observations into a single representation complicates perception. Choosing a single unified representation for all sensors simplifies the task of perception and fusion. In this work, we present an end-to-end pipeline that performs semantic segmentation and short term prediction using a top-down representation. Our approach consists of an ensemble of neural networks which take in sensor data from different sensor modalities and transform them into a single common top-down semantic grid representation. We find this representation favorable as it is agnostic to sensor-specific reference frames and captures both the semantic and geometric information for the surrounding scene. Because the modalities share a single output representation, they can be easily aggregated to produce a fused output. In this work we predict short-term semantic grids but the framework can be extended to other tasks. This approach offers a simple, extensible, end-to-end approach for multi-modal perception and prediction.
Rules of the Road: Predicting Driving Behavior with a Convolutional Model of Semantic Interactions
Jun 21, 2019
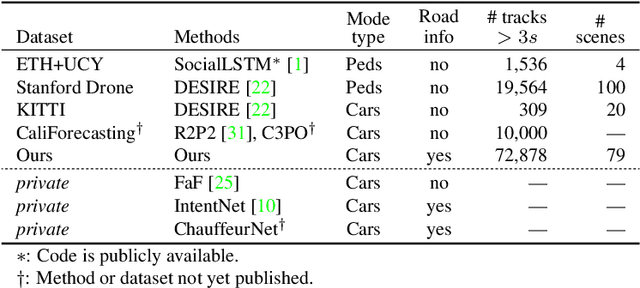

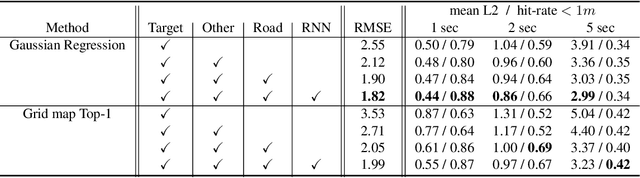
We focus on the problem of predicting future states of entities in complex, real-world driving scenarios. Previous research has used low-level signals to predict short time horizons, and has not addressed how to leverage key assets relied upon heavily by industry self-driving systems: (1) large 3D perception efforts which provide highly accurate 3D states of agents with rich attributes, and (2) detailed and accurate semantic maps of the environment (lanes, traffic lights, crosswalks, etc). We present a unified representation which encodes such high-level semantic information in a spatial grid, allowing the use of deep convolutional models to fuse complex scene context. This enables learning entity-entity and entity-environment interactions with simple, feed-forward computations in each timestep within an overall temporal model of an agent's behavior. We propose different ways of modelling the future as a distribution over future states using standard supervised learning. We introduce a novel dataset providing industry-grade rich perception and semantic inputs, and empirically show we can effectively learn fundamentals of driving behavior.
* Accepted at CVPR 2019
The Unreasonable Effectiveness of Noisy Data for Fine-Grained Recognition
Oct 18, 2016
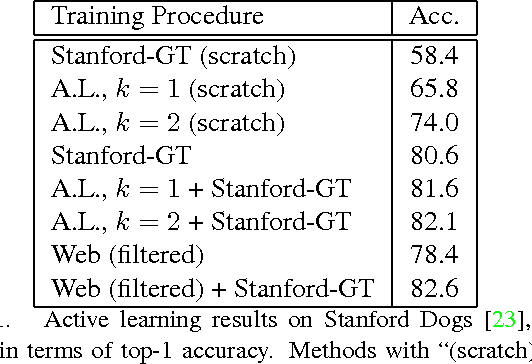

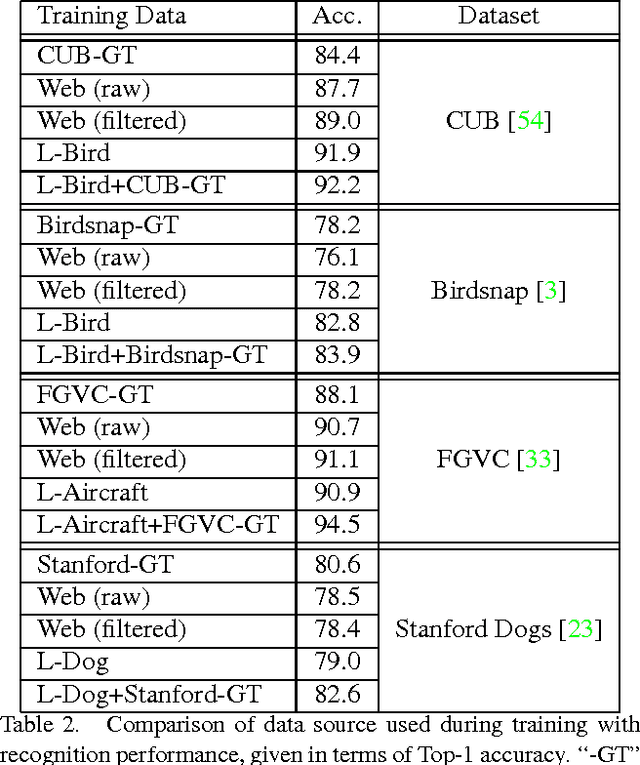
Current approaches for fine-grained recognition do the following: First, recruit experts to annotate a dataset of images, optionally also collecting more structured data in the form of part annotations and bounding boxes. Second, train a model utilizing this data. Toward the goal of solving fine-grained recognition, we introduce an alternative approach, leveraging free, noisy data from the web and simple, generic methods of recognition. This approach has benefits in both performance and scalability. We demonstrate its efficacy on four fine-grained datasets, greatly exceeding existing state of the art without the manual collection of even a single label, and furthermore show first results at scaling to more than 10,000 fine-grained categories. Quantitatively, we achieve top-1 accuracies of 92.3% on CUB-200-2011, 85.4% on Birdsnap, 93.4% on FGVC-Aircraft, and 80.8% on Stanford Dogs without using their annotated training sets. We compare our approach to an active learning approach for expanding fine-grained datasets.
PlaNet - Photo Geolocation with Convolutional Neural Networks
Feb 17, 2016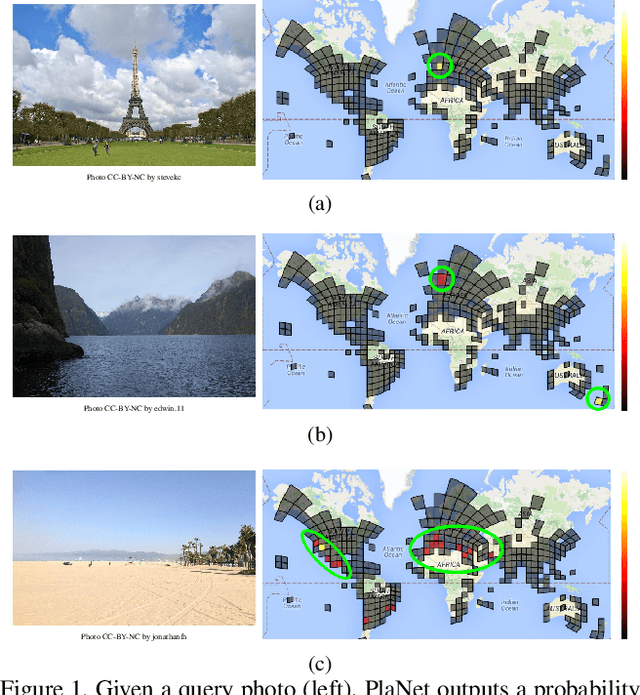
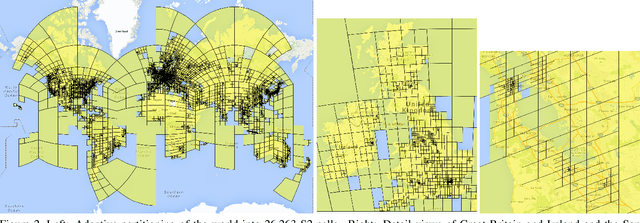

Is it possible to build a system to determine the location where a photo was taken using just its pixels? In general, the problem seems exceptionally difficult: it is trivial to construct situations where no location can be inferred. Yet images often contain informative cues such as landmarks, weather patterns, vegetation, road markings, and architectural details, which in combination may allow one to determine an approximate location and occasionally an exact location. Websites such as GeoGuessr and View from your Window suggest that humans are relatively good at integrating these cues to geolocate images, especially en-masse. In computer vision, the photo geolocation problem is usually approached using image retrieval methods. In contrast, we pose the problem as one of classification by subdividing the surface of the earth into thousands of multi-scale geographic cells, and train a deep network using millions of geotagged images. While previous approaches only recognize landmarks or perform approximate matching using global image descriptors, our model is able to use and integrate multiple visible cues. We show that the resulting model, called PlaNet, outperforms previous approaches and even attains superhuman levels of accuracy in some cases. Moreover, we extend our model to photo albums by combining it with a long short-term memory (LSTM) architecture. By learning to exploit temporal coherence to geolocate uncertain photos, we demonstrate that this model achieves a 50% performance improvement over the single-image model.
DeepStereo: Learning to Predict New Views from the World's Imagery
Jun 22, 2015

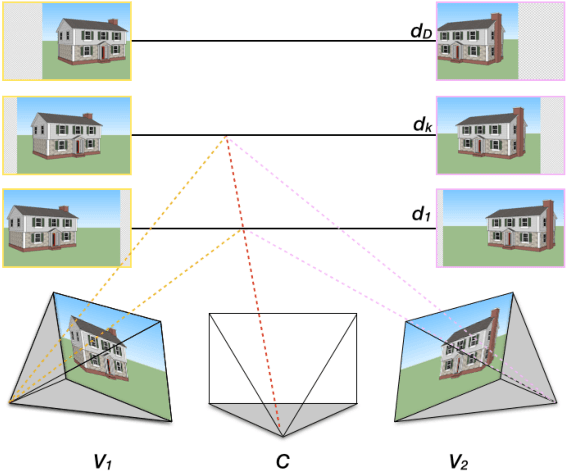
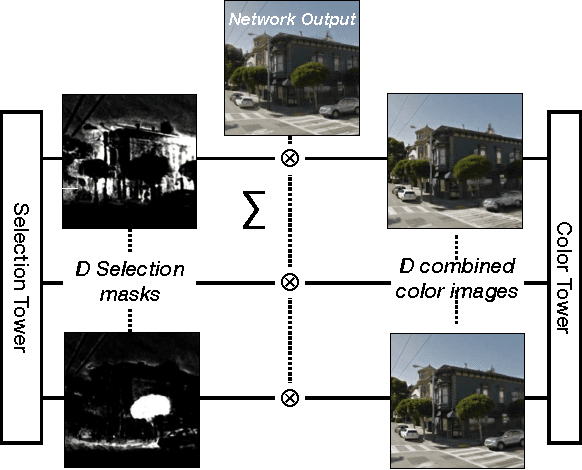
Deep networks have recently enjoyed enormous success when applied to recognition and classification problems in computer vision, but their use in graphics problems has been limited. In this work, we present a novel deep architecture that performs new view synthesis directly from pixels, trained from a large number of posed image sets. In contrast to traditional approaches which consist of multiple complex stages of processing, each of which require careful tuning and can fail in unexpected ways, our system is trained end-to-end. The pixels from neighboring views of a scene are presented to the network which then directly produces the pixels of the unseen view. The benefits of our approach include generality (we only require posed image sets and can easily apply our method to different domains), and high quality results on traditionally difficult scenes. We believe this is due to the end-to-end nature of our system which is able to plausibly generate pixels according to color, depth, and texture priors learnt automatically from the training data. To verify our method we show that it can convincingly reproduce known test views from nearby imagery. Additionally we show images rendered from novel viewpoints. To our knowledge, our work is the first to apply deep learning to the problem of new view synthesis from sets of real-world, natural imagery.
FaceNet: A Unified Embedding for Face Recognition and Clustering
Jun 17, 2015



Despite significant recent advances in the field of face recognition, implementing face verification and recognition efficiently at scale presents serious challenges to current approaches. In this paper we present a system, called FaceNet, that directly learns a mapping from face images to a compact Euclidean space where distances directly correspond to a measure of face similarity. Once this space has been produced, tasks such as face recognition, verification and clustering can be easily implemented using standard techniques with FaceNet embeddings as feature vectors. Our method uses a deep convolutional network trained to directly optimize the embedding itself, rather than an intermediate bottleneck layer as in previous deep learning approaches. To train, we use triplets of roughly aligned matching / non-matching face patches generated using a novel online triplet mining method. The benefit of our approach is much greater representational efficiency: we achieve state-of-the-art face recognition performance using only 128-bytes per face. On the widely used Labeled Faces in the Wild (LFW) dataset, our system achieves a new record accuracy of 99.63%. On YouTube Faces DB it achieves 95.12%. Our system cuts the error rate in comparison to the best published result by 30% on both datasets. We also introduce the concept of harmonic embeddings, and a harmonic triplet loss, which describe different versions of face embeddings (produced by different networks) that are compatible to each other and allow for direct comparison between each other.
Learning Fine-grained Image Similarity with Deep Ranking
Apr 17, 2014
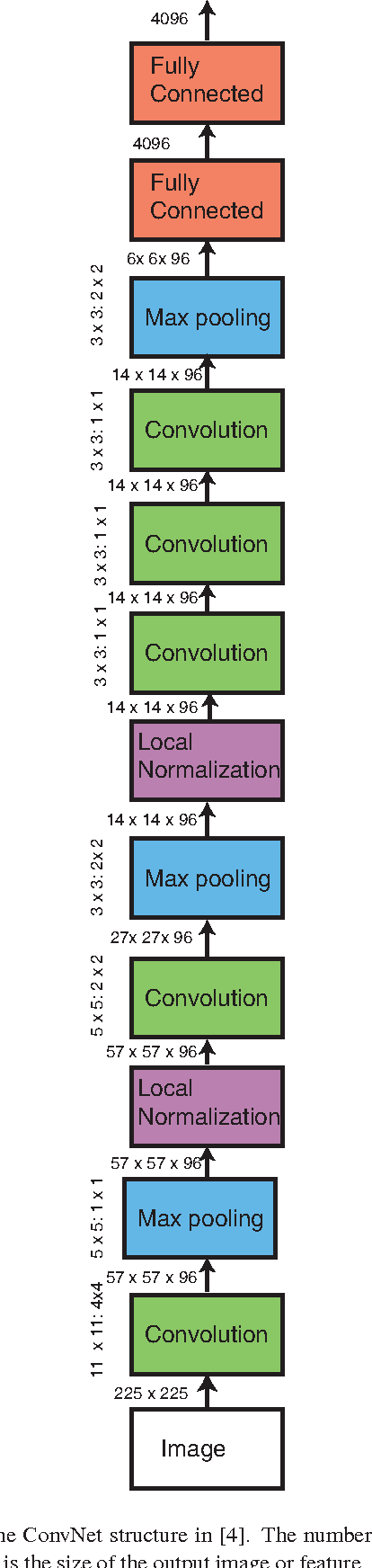

Learning fine-grained image similarity is a challenging task. It needs to capture between-class and within-class image differences. This paper proposes a deep ranking model that employs deep learning techniques to learn similarity metric directly from images.It has higher learning capability than models based on hand-crafted features. A novel multiscale network structure has been developed to describe the images effectively. An efficient triplet sampling algorithm is proposed to learn the model with distributed asynchronized stochastic gradient. Extensive experiments show that the proposed algorithm outperforms models based on hand-crafted visual features and deep classification models.