 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Conditional Predictors for Domain Adaptation
Jun 25, 2021

Learning guarantees often rely on assumptions of i.i.d. data, which will likely be violated in practice once predictors are deployed to perform real-world tasks. Domain adaptation approaches thus appeared as a useful framework yielding extra flexibility in that distinct train and test data distributions are supported, provided that other assumptions are satisfied such as covariate shift, which expects the conditional distributions over labels to be independent of the underlying data distribution. Several approaches were introduced in order to induce generalization across varying train and test data sources, and those often rely on the general idea of domain-invariance, in such a way that the data-generating distributions are to be disregarded by the prediction model. In this contribution, we tackle the problem of generalizing across data sources by approaching it from the opposite direction: we consider a conditional modeling approach in which predictions, in addition to being dependent on the input data, use information relative to the underlying data-generating distribution. For instance, the model has an explicit mechanism to adapt to changing environments and/or new data sources. We argue that such an approach is more generally applicable than current domain adaptation methods since it does not require extra assumptions such as covariate shift and further yields simpler training algorithms that avoid a common source of training instabilities caused by minimax formulations, often employed in domain-invariant methods.
Attention-based Extraction of Structured Information from Street View Imagery
Aug 20, 2017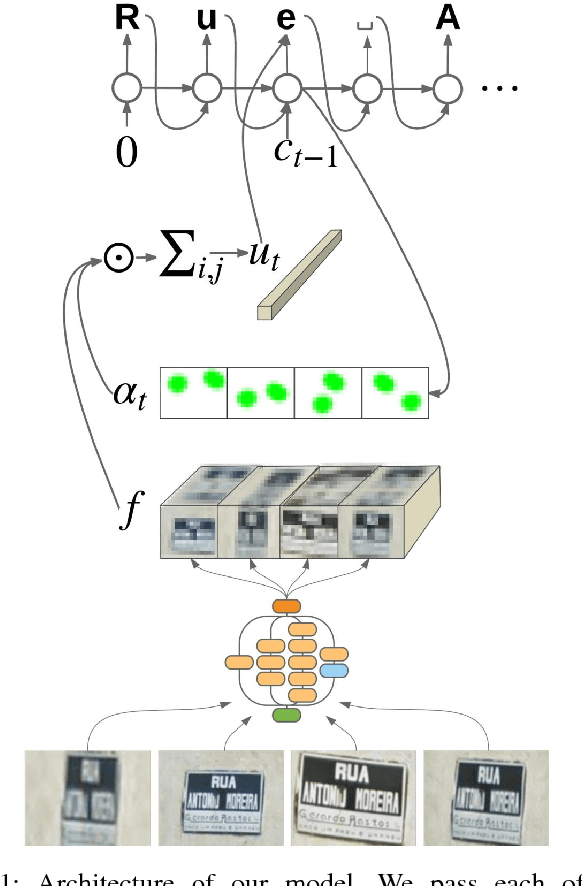
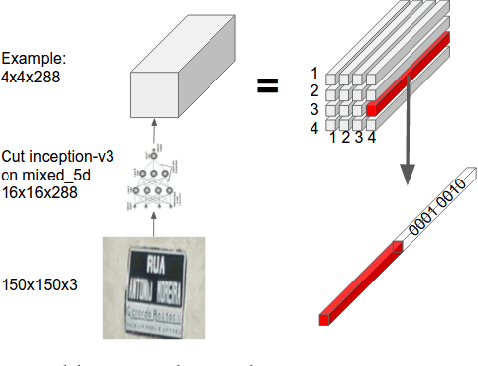


We present a neural network model - based on CNNs, RNNs and a novel attention mechanism - which achieves 84.2% accuracy on the challenging French Street Name Signs (FSNS) dataset, significantly outperforming the previous state of the art (Smith'16), which achieved 72.46%. Furthermore, our new method is much simpler and more general than the previous approach. To demonstrate the generality of our model, we show that it also performs well on an even more challenging dataset derived from Google Street View, in which the goal is to extract business names from store fronts. Finally, we study the speed/accuracy tradeoff that results from using CNN feature extractors of different depths. Surprisingly, we find that deeper is not always better (in terms of accuracy, as well as speed). Our resulting model is simple, accurate and fast, allowing it to be used at scale on a variety of challenging real-world text extraction problems.
End-to-End Interpretation of the French Street Name Signs Dataset
Feb 13, 2017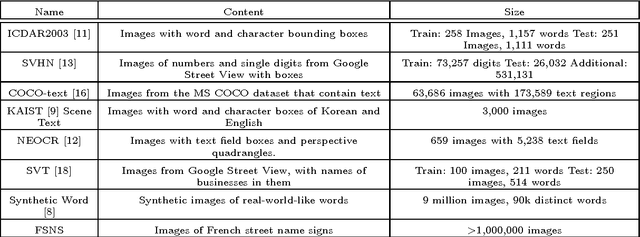


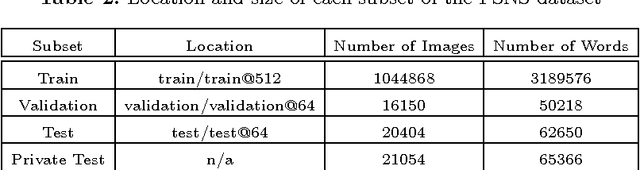
We introduce the French Street Name Signs (FSNS) Dataset consisting of more than a million images of street name signs cropped from Google Street View images of France. Each image contains several views of the same street name sign. Every image has normalized, title case folded ground-truth text as it would appear on a map. We believe that the FSNS dataset is large and complex enough to train a deep network of significant complexity to solve the street name extraction problem "end-to-end" or to explore the design trade-offs between a single complex engineered network and multiple sub-networks designed and trained to solve sub-problems. We present such an "end-to-end" network/graph for Tensor Flow and its results on the FSNS dataset.
* Presented at the IWRR workshop at ECCV 2016