 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBUSTED at AraGenEval Shared Task: A Comparative Study of Transformer-Based Models for Arabic AI-Generated Text Detection
Oct 23, 2025This paper details our submission to the Ara- GenEval Shared Task on Arabic AI-generated text detection, where our team, BUSTED, se- cured 5th place. We investigated the effec- tiveness of three pre-trained transformer mod- els: AraELECTRA, CAMeLBERT, and XLM- RoBERTa. Our approach involved fine-tuning each model on the provided dataset for a binary classification task. Our findings revealed a sur- prising result: the multilingual XLM-RoBERTa model achieved the highest performance with an F1 score of 0.7701, outperforming the spe- cialized Arabic models. This work underscores the complexities of AI-generated text detection and highlights the strong generalization capa- bilities of multilingual models.
Textual analysis of End User License Agreement for red-flagging potentially malicious software
Mar 11, 2024New software and updates are downloaded by end users every day. Each dowloaded software has associated with it an End Users License Agreements (EULA), but this is rarely read. An EULA includes information to avoid legal repercussions. However,this proposes a host of potential problems such as spyware or producing an unwanted affect in the target system. End users do not read these EULA's because of length of the document and users find it extremely difficult to understand. Text summarization is one of the relevant solution to these kind of problems. This require a solution which can summarize the EULA and classify the EULA as "Benign" or "Malicious". We propose a solution in which we have summarize the EULA and classify the EULA as "Benign" or "Malicious". We extract EULA text of different sofware's then we classify the text using eight different supervised classifiers. we use ensemble learning to classify the EULA as benign or malicious using five different text summarization methods. An accuracy of $95.8$\% shows the effectiveness of the presented approach.
Accuracy and Fidelity Comparison of Luna and DALL-E 2 Diffusion-Based Image Generation Systems
Jan 05, 2023



We qualitatively examine the accuracy and fideltiy between two diffusion-based image generation systems, namely DALL-E 2 and Luna, which have massive differences in training datasets, algorithmic approaches, prompt resolvement, and output upscaling. In our research we conclude that DALL-E 2 significantly edges Luna in both alignment and fidelity comparisons
Artificial Interrogation for Attributing Language Models
Nov 20, 2022
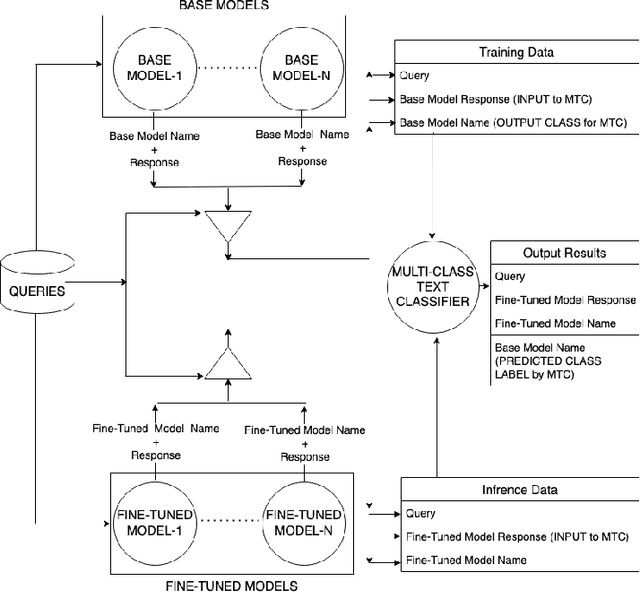
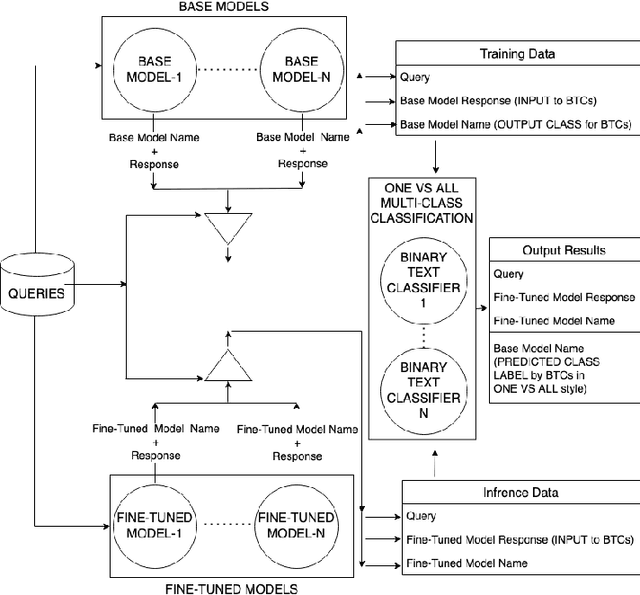

This paper presents solutions to the Machine Learning Model Attribution challenge (MLMAC) collectively organized by MITRE, Microsoft, Schmidt-Futures, Robust-Intelligence, Lincoln-Network, and Huggingface community. The challenge provides twelve open-sourced base versions of popular language models developed by well-known organizations and twelve fine-tuned language models for text generation. The names and architecture details of fine-tuned models were kept hidden, and participants can access these models only through the rest APIs developed by the organizers. Given these constraints, the goal of the contest is to identify which fine-tuned models originated from which base model. To solve this challenge, we have assumed that fine-tuned models and their corresponding base versions must share a similar vocabulary set with a matching syntactical writing style that resonates in their generated outputs. Our strategy is to develop a set of queries to interrogate base and fine-tuned models. And then perform one-to-many pairing between them based on similarities in their generated responses, where more than one fine-tuned model can pair with a base model but not vice-versa. We have employed four distinct approaches for measuring the resemblance between the responses generated from the models of both sets. The first approach uses evaluation metrics of the machine translation, and the second uses a vector space model. The third approach uses state-of-the-art multi-class text classification, Transformer models. Lastly, the fourth approach uses a set of Transformer based binary text classifiers, one for each provided base model, to perform multi-class text classification in a one-vs-all fashion. This paper reports implementation details, comparison, and experimental studies, of these approaches along with the final obtained results.
Guiding Attention using Partial-Order Relationships for Image Captioning
Apr 15, 2022
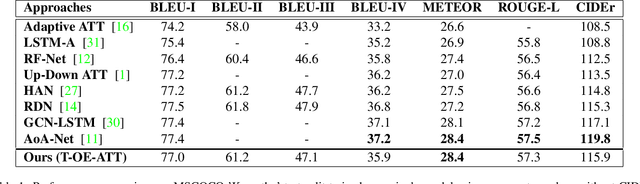
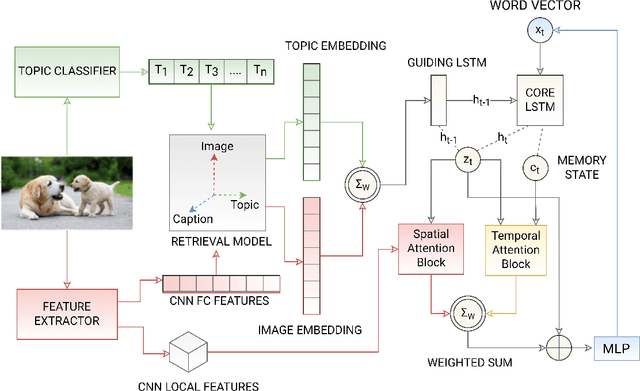
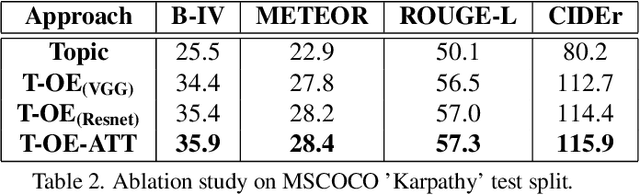
The use of attention models for automated image captioning has enabled many systems to produce accurate and meaningful descriptions for images. Over the years, many novel approaches have been proposed to enhance the attention process using different feature representations. In this paper, we extend this approach by creating a guided attention network mechanism, that exploits the relationship between the visual scene and text-descriptions using spatial features from the image, high-level information from the topics, and temporal context from caption generation, which are embedded together in an ordered embedding space. A pairwise ranking objective is used for training this embedding space which allows similar images, topics and captions in the shared semantic space to maintain a partial order in the visual-semantic hierarchy and hence, helps the model to produce more visually accurate captions. The experimental results based on MSCOCO dataset shows the competitiveness of our approach, with many state-of-the-art models on various evaluation metrics.
An Intelligent and Time-Efficient DDoS Identification Framework for Real-Time Enterprise Networks SAD-F: Spark Based Anomaly Detection Framework
Feb 14, 2020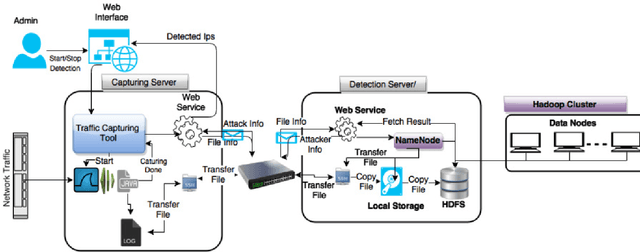
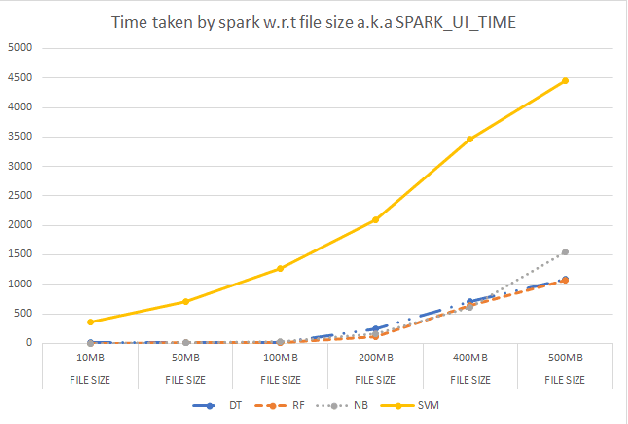
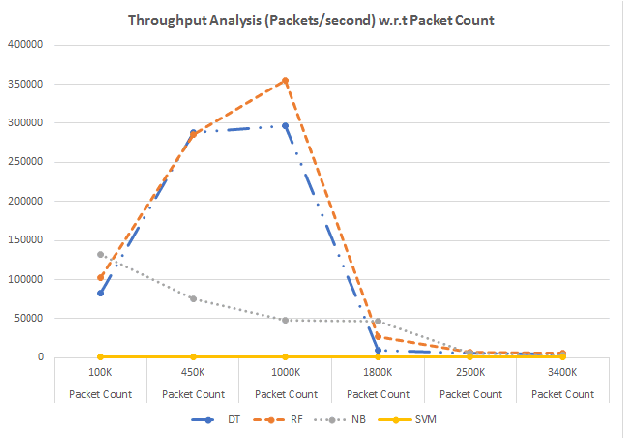
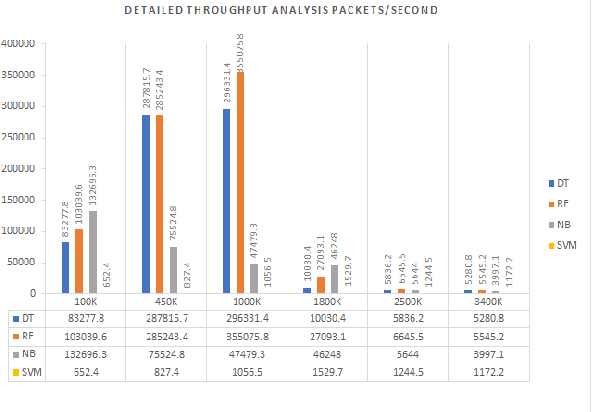
Anomaly detection is a crucial step for preventing malicious activities in the network and keeping resources available all the time for legitimate users. It is noticed from various studies that classical anomaly detectors work well with small and sampled data, but the chances of failures increase with real-time (non-sampled data) traffic data. In this paper, we will be exploring security analytic techniques for DDoS anomaly detection using different machine learning techniques. In this paper, we are proposing a novel approach which deals with real traffic as input to the system. Further, we study and compare the performance factor of our proposed framework on three different testbeds including normal commodity hardware, low-end system, and high-end system. Hardware details of testbeds are discussed in the respective section. Further in this paper, we investigate the performance of the classifiers in (near) real-time detection of anomalies attacks. This study also focused on the feature selection process that is as important for the anomaly detection process as it is for general modeling problems. Several techniques have been studied for feature selection and it is observed that proper feature selection can increase performance in terms of model's execution time - which totally depends upon the traffic file or traffic capturing process.
A comparison of SVM and RVM for Document Classification
Jan 13, 2013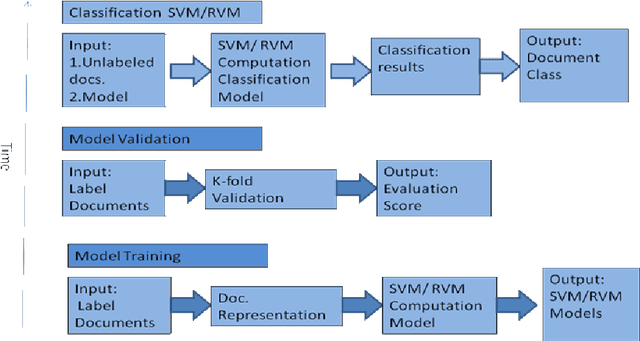
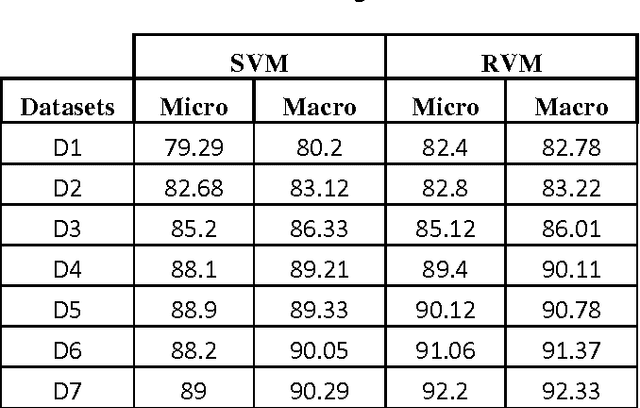
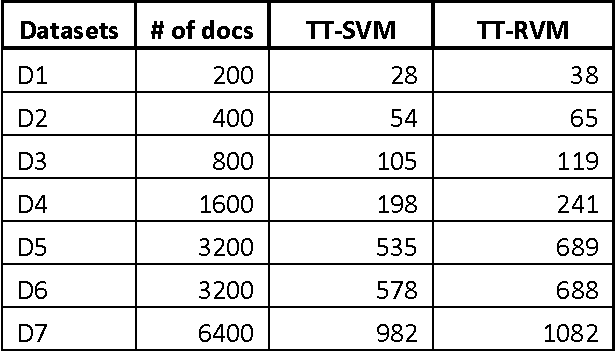
Document classification is a task of assigning a new unclassified document to one of the predefined set of classes. The content based document classification uses the content of the document with some weighting criteria to assign it to one of the predefined classes. It is a major task in library science, electronic document management systems and information sciences. This paper investigates document classification by using two different classification techniques (1) Support Vector Machine (SVM) and (2) Relevance Vector Machine (RVM). SVM is a supervised machine learning technique that can be used for classification task. In its basic form, SVM represents the instances of the data into space and tries to separate the distinct classes by a maximum possible wide gap (hyper plane) that separates the classes. On the other hand RVM uses probabilistic measure to define this separation space. RVM uses Bayesian inference to obtain succinct solution, thus RVM uses significantly fewer basis functions. Experimental studies on three standard text classification datasets reveal that although RVM takes more training time, its classification is much better as compared to SVM.
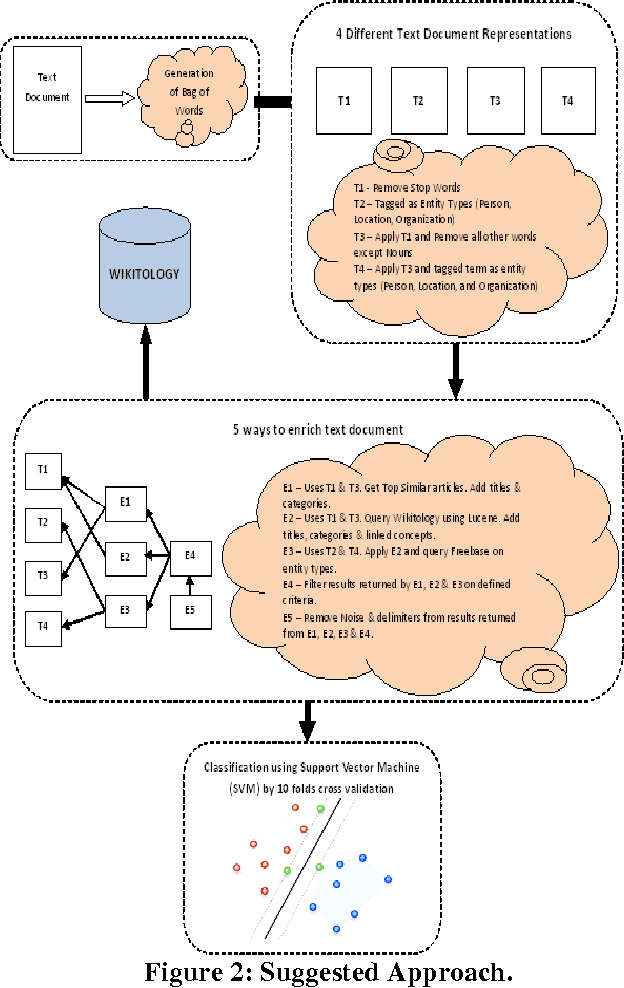
Content-based Text Categorization using Wikitology
Aug 17, 2012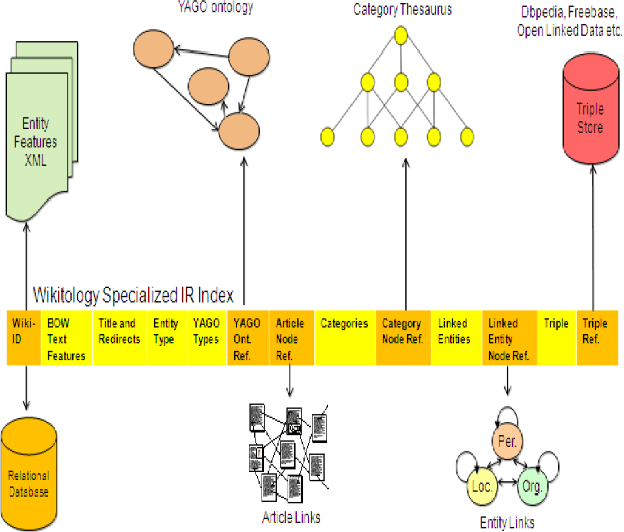

A major computational burden, while performing document clustering, is the calculation of similarity measure between a pair of documents. Similarity measure is a function that assign a real number between 0 and 1 to a pair of documents, depending upon the degree of similarity between them. A value of zero means that the documents are completely dissimilar whereas a value of one indicates that the documents are practically identical. Traditionally, vector-based models have been used for computing the document similarity. The vector-based models represent several features present in documents. These approaches to similarity measures, in general, cannot account for the semantics of the document. Documents written in human languages contain contexts and the words used to describe these contexts are generally semantically related. Motivated by this fact, many researchers have proposed semantic-based similarity measures by utilizing text annotation through external thesauruses like WordNet (a lexical database). In this paper, we define a semantic similarity measure based on documents represented in topic maps. Topic maps are rapidly becoming an industrial standard for knowledge representation with a focus for later search and extraction. The documents are transformed into a topic map based coded knowledge and the similarity between a pair of documents is represented as a correlation between the common patterns. The experimental studies on the text mining datasets reveal that this new similarity measure is more effective as compared to commonly used similarity measures in text clustering.
Comparing SVM and Naive Bayes classifiers for text categorization with Wikitology as knowledge enrichment
Feb 18, 2012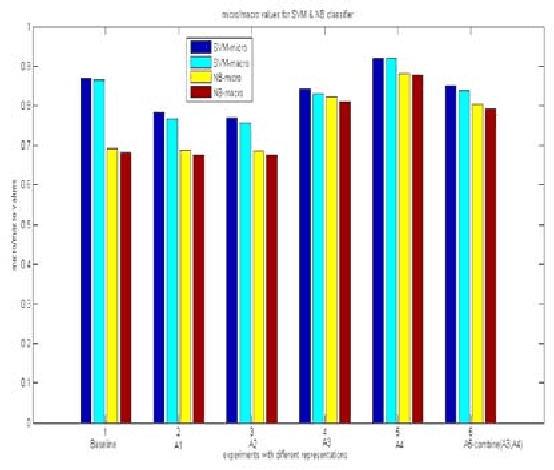
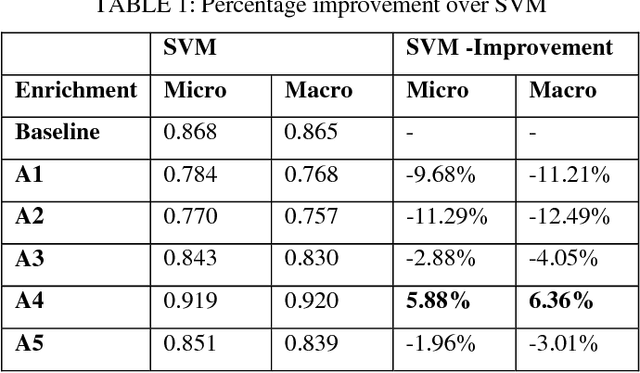
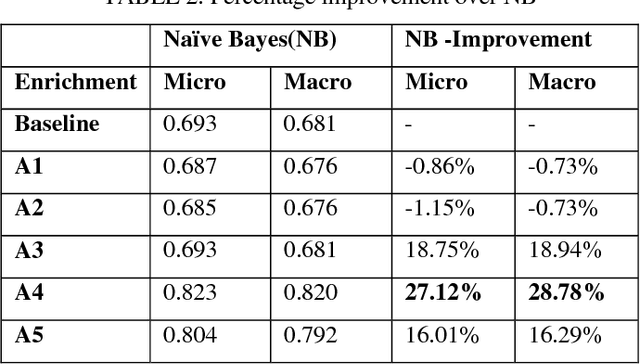
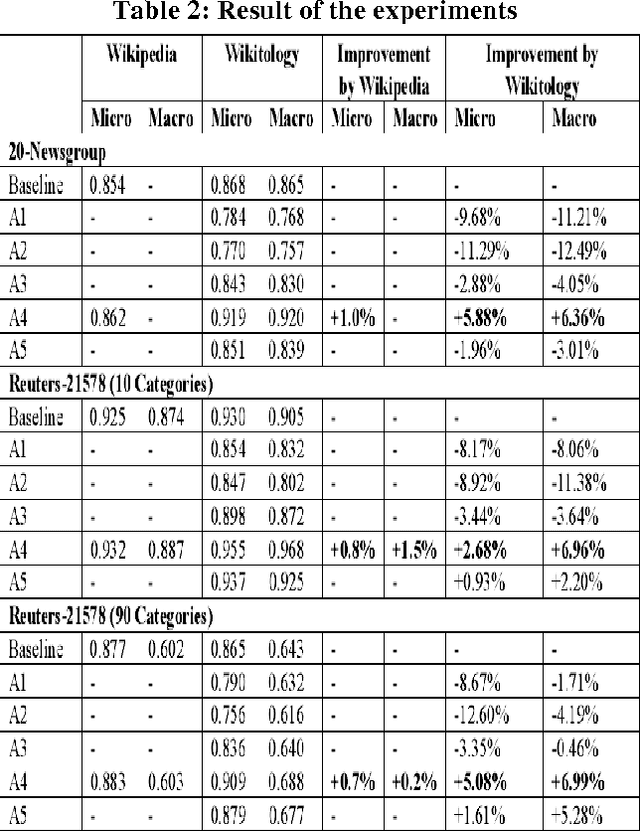
The activity of labeling of documents according to their content is known as text categorization. Many experiments have been carried out to enhance text categorization by adding background knowledge to the document using knowledge repositories like Word Net, Open Project Directory (OPD), Wikipedia and Wikitology. In our previous work, we have carried out intensive experiments by extracting knowledge from Wikitology and evaluating the experiment on Support Vector Machine with 10- fold cross-validations. The results clearly indicate Wikitology is far better than other knowledge bases. In this paper we are comparing Support Vector Machine (SVM) and Na\"ive Bayes (NB) classifiers under text enrichment through Wikitology. We validated results with 10-fold cross validation and shown that NB gives an improvement of +28.78%, on the other hand SVM gives an improvement of +6.36% when compared with baseline results. Na\"ive Bayes classifier is better choice when external enriching is used through any external knowledge base.
* 5 pages
A comparison of two suffix tree-based document clustering algorithms
Jan 10, 2012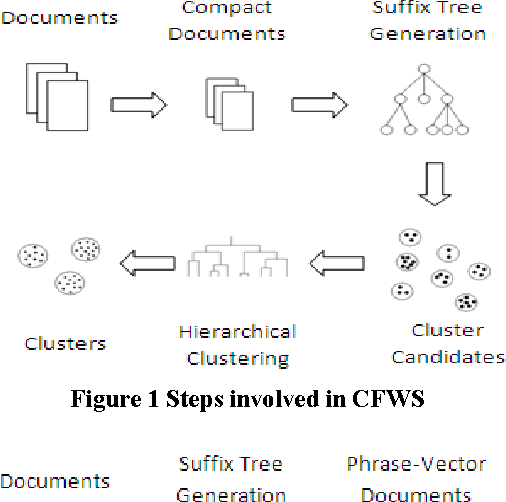
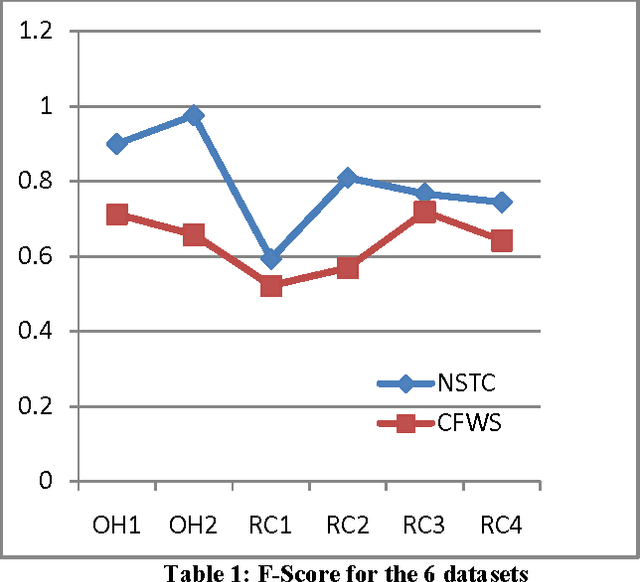
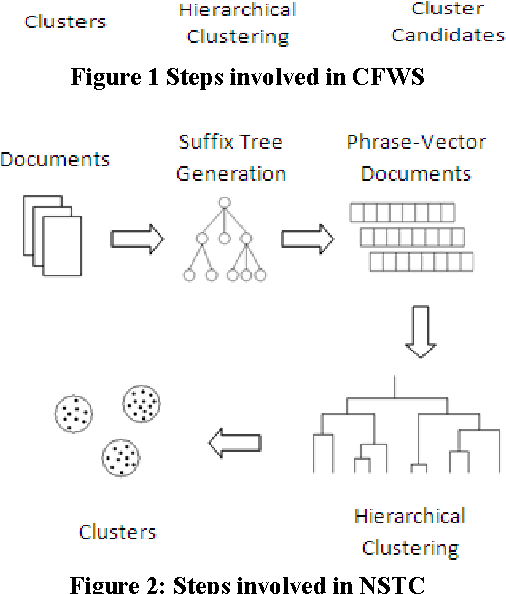
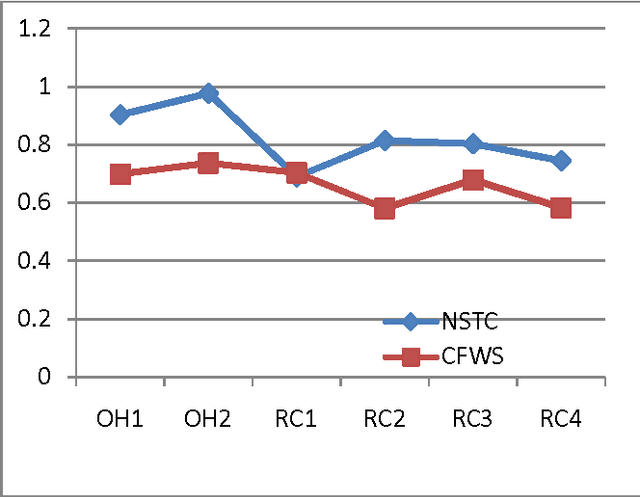
Document clustering as an unsupervised approach extensively used to navigate, filter, summarize and manage large collection of document repositories like the World Wide Web (WWW). Recently, focuses in this domain shifted from traditional vector based document similarity for clustering to suffix tree based document similarity, as it offers more semantic representation of the text present in the document. In this paper, we compare and contrast two recently introduced approaches to document clustering based on suffix tree data model. The first is an Efficient Phrase based document clustering, which extracts phrases from documents to form compact document representation and uses a similarity measure based on common suffix tree to cluster the documents. The second approach is a frequent word/word meaning sequence based document clustering, it similarly extracts the common word sequence from the document and uses the common sequence/ common word meaning sequence to perform the compact representation, and finally, it uses document clustering approach to cluster the compact documents. These algorithms are using agglomerative hierarchical document clustering to perform the actual clustering step, the difference in these approaches are mainly based on extraction of phrases, model representation as a compact document, and the similarity measures used for clustering. This paper investigates the computational aspect of the two algorithms, and the quality of results they produced.