 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbodiment-Induced Coordination Regimes in Tabular Multi-Agent Q-Learning
Jan 24, 2026Centralized value learning is often assumed to improve coordination and stability in multi-agent reinforcement learning, yet this assumption is rarely tested under controlled conditions. We directly evaluate it in a fully tabular predator-prey gridworld by comparing independent and centralized Q-learning under explicit embodiment constraints on agent speed and stamina. Across multiple kinematic regimes and asymmetric agent roles, centralized learning fails to provide a consistent advantage and is frequently outperformed by fully independent learning, even under full observability and exact value estimation. Moreover, asymmetric centralized-independent configurations induce persistent coordination breakdowns rather than transient learning instability. By eliminating confounding effects from function approximation and representation learning, our tabular analysis isolates coordination structure as the primary driver of these effects. The results show that increased coordination can become a liability under embodiment constraints, and that the effectiveness of centralized learning is fundamentally regime and role dependent rather than universal.
A comparison of SVM and RVM for Document Classification
Jan 13, 2013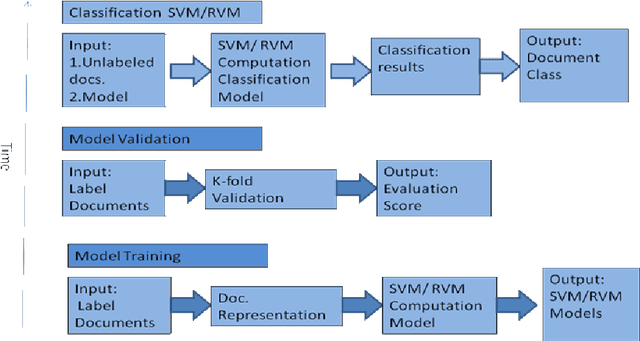
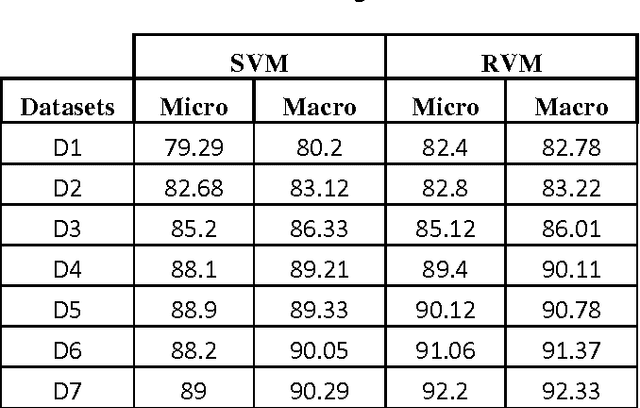
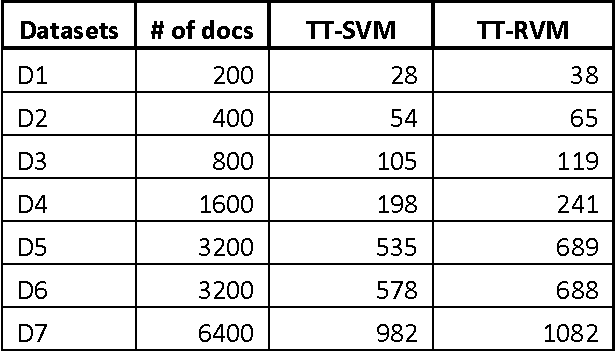
Document classification is a task of assigning a new unclassified document to one of the predefined set of classes. The content based document classification uses the content of the document with some weighting criteria to assign it to one of the predefined classes. It is a major task in library science, electronic document management systems and information sciences. This paper investigates document classification by using two different classification techniques (1) Support Vector Machine (SVM) and (2) Relevance Vector Machine (RVM). SVM is a supervised machine learning technique that can be used for classification task. In its basic form, SVM represents the instances of the data into space and tries to separate the distinct classes by a maximum possible wide gap (hyper plane) that separates the classes. On the other hand RVM uses probabilistic measure to define this separation space. RVM uses Bayesian inference to obtain succinct solution, thus RVM uses significantly fewer basis functions. Experimental studies on three standard text classification datasets reveal that although RVM takes more training time, its classification is much better as compared to SVM.
Content-based Text Categorization using Wikitology
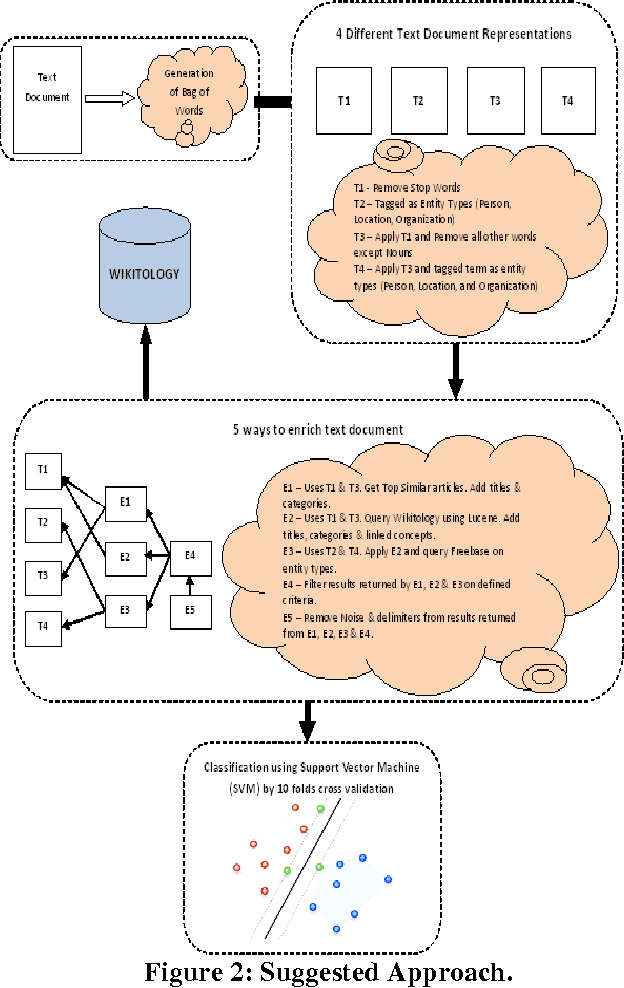
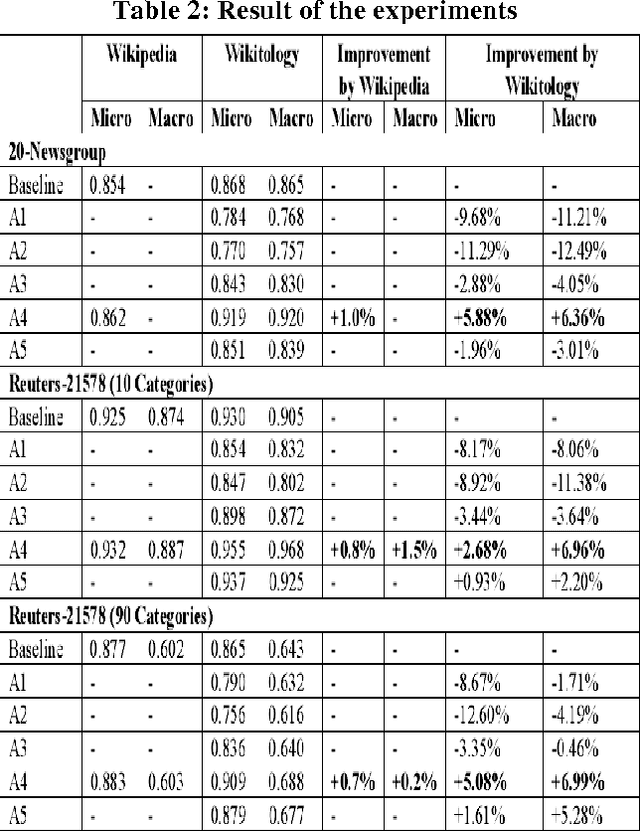
Aug 17, 2012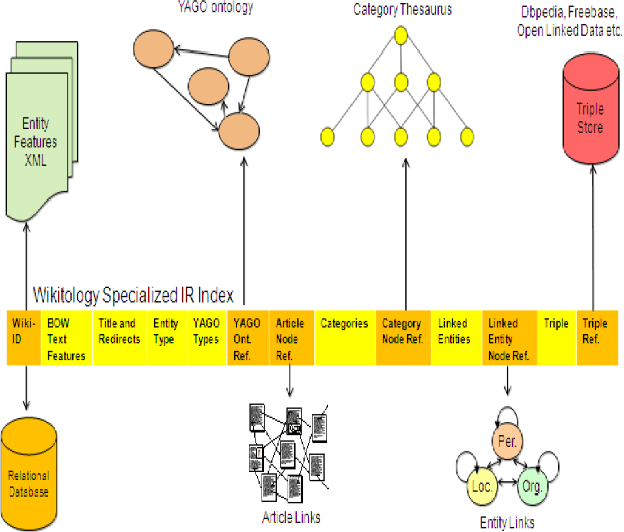

A major computational burden, while performing document clustering, is the calculation of similarity measure between a pair of documents. Similarity measure is a function that assign a real number between 0 and 1 to a pair of documents, depending upon the degree of similarity between them. A value of zero means that the documents are completely dissimilar whereas a value of one indicates that the documents are practically identical. Traditionally, vector-based models have been used for computing the document similarity. The vector-based models represent several features present in documents. These approaches to similarity measures, in general, cannot account for the semantics of the document. Documents written in human languages contain contexts and the words used to describe these contexts are generally semantically related. Motivated by this fact, many researchers have proposed semantic-based similarity measures by utilizing text annotation through external thesauruses like WordNet (a lexical database). In this paper, we define a semantic similarity measure based on documents represented in topic maps. Topic maps are rapidly becoming an industrial standard for knowledge representation with a focus for later search and extraction. The documents are transformed into a topic map based coded knowledge and the similarity between a pair of documents is represented as a correlation between the common patterns. The experimental studies on the text mining datasets reveal that this new similarity measure is more effective as compared to commonly used similarity measures in text clustering.