 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinguaMark: Do Multimodal Models Speak Fairly? A Benchmark-Based Evaluation
Jul 09, 2025



Large Multimodal Models (LMMs) are typically trained on vast corpora of image-text data but are often limited in linguistic coverage, leading to biased and unfair outputs across languages. While prior work has explored multimodal evaluation, less emphasis has been placed on assessing multilingual capabilities. In this work, we introduce LinguaMark, a benchmark designed to evaluate state-of-the-art LMMs on a multilingual Visual Question Answering (VQA) task. Our dataset comprises 6,875 image-text pairs spanning 11 languages and five social attributes. We evaluate models using three key metrics: Bias, Answer Relevancy, and Faithfulness. Our findings reveal that closed-source models generally achieve the highest overall performance. Both closed-source (GPT-4o and Gemini2.5) and open-source models (Gemma3, Qwen2.5) perform competitively across social attributes, and Qwen2.5 demonstrates strong generalization across multiple languages. We release our benchmark and evaluation code to encourage reproducibility and further research.
HumaniBench: A Human-Centric Framework for Large Multimodal Models Evaluation
May 16, 2025



Large multimodal models (LMMs) now excel on many vision language benchmarks, however, they still struggle with human centered criteria such as fairness, ethics, empathy, and inclusivity, key to aligning with human values. We introduce HumaniBench, a holistic benchmark of 32K real-world image question pairs, annotated via a scalable GPT4o assisted pipeline and exhaustively verified by domain experts. HumaniBench evaluates seven Human Centered AI (HCAI) principles: fairness, ethics, understanding, reasoning, language inclusivity, empathy, and robustness, across seven diverse tasks, including open and closed ended visual question answering (VQA), multilingual QA, visual grounding, empathetic captioning, and robustness tests. Benchmarking 15 state of the art LMMs (open and closed source) reveals that proprietary models generally lead, though robustness and visual grounding remain weak points. Some open-source models also struggle to balance accuracy with adherence to human-aligned principles. HumaniBench is the first benchmark purpose built around HCAI principles. It provides a rigorous testbed for diagnosing alignment gaps and guiding LMMs toward behavior that is both accurate and socially responsible. Dataset, annotation prompts, and evaluation code are available at: https://vectorinstitute.github.io/HumaniBench
Advancing Medical Representation Learning Through High-Quality Data
Mar 18, 2025Despite the growing scale of medical Vision-Language datasets, the impact of dataset quality on model performance remains under-explored. We introduce Open-PMC, a high-quality medical dataset from PubMed Central, containing 2.2 million image-text pairs, enriched with image modality annotations, subfigures, and summarized in-text references. Notably, the in-text references provide richer medical context, extending beyond the abstract information typically found in captions. Through extensive experiments, we benchmark Open-PMC against larger datasets across retrieval and zero-shot classification tasks. Our results show that dataset quality-not just size-drives significant performance gains. We complement our benchmark with an in-depth analysis of feature representation. Our findings highlight the crucial role of data curation quality in advancing multimodal medical AI. We release Open-PMC, along with the trained models and our codebase.
VLDBench: Vision Language Models Disinformation Detection Benchmark
Feb 17, 2025



The rapid rise of AI-generated content has made detecting disinformation increasingly challenging. In particular, multimodal disinformation, i.e., online posts-articles that contain images and texts with fabricated information are specially designed to deceive. While existing AI safety benchmarks primarily address bias and toxicity, multimodal disinformation detection remains largely underexplored. To address this challenge, we present the Vision-Language Disinformation Detection Benchmark VLDBench, the first comprehensive benchmark for detecting disinformation across both unimodal (text-only) and multimodal (text and image) content, comprising 31,000} news article-image pairs, spanning 13 distinct categories, for robust evaluation. VLDBench features a rigorous semi-automated data curation pipeline, with 22 domain experts dedicating 300 plus hours} to annotation, achieving a strong inter-annotator agreement (Cohen kappa = 0.78). We extensively evaluate state-of-the-art Large Language Models (LLMs) and Vision-Language Models (VLMs), demonstrating that integrating textual and visual cues in multimodal news posts improves disinformation detection accuracy by 5 - 35 % compared to unimodal models. Developed in alignment with AI governance frameworks such as the EU AI Act, NIST guidelines, and the MIT AI Risk Repository 2024, VLDBench is expected to become a benchmark for detecting disinformation in online multi-modal contents. Our code and data will be publicly available.
ViLBias: A Framework for Bias Detection using Linguistic and Visual Cues
Dec 22, 2024



The integration of Large Language Models (LLMs) and Vision-Language Models (VLMs) opens new avenues for addressing complex challenges in multimodal content analysis, particularly in biased news detection. This study introduces ViLBias, a framework that leverages state of the art LLMs and VLMs to detect linguistic and visual biases in news content, addressing the limitations of traditional text-only approaches. Our contributions include a novel dataset pairing textual content with accompanying visuals from diverse news sources and a hybrid annotation framework, combining LLM-based annotations with human review to enhance quality while reducing costs and improving scalability. We evaluate the efficacy of LLMs and VLMs in identifying biases, revealing their strengths in detecting subtle framing and text-visual inconsistencies. Empirical analysis demonstrates that incorporating visual cues alongside text enhances bias detection accuracy by 3 to 5 %, showcasing the complementary strengths of LLMs in generative reasoning and Small Language Models (SLMs) in classification. This study offers a comprehensive exploration of LLMs and VLMs as tools for detecting multimodal biases in news content, highlighting both their potential and limitations. Our research paves the way for more robust, scalable, and nuanced approaches to media bias detection, contributing to the broader field of natural language processing and multimodal analysis. (The data and code will be made available for research purposes).
Enhancing Anomaly Detection Generalization through Knowledge Exposure: The Dual Effects of Augmentation
Jun 15, 2024



Anomaly detection involves identifying instances within a dataset that deviate from the norm and occur infrequently. Current benchmarks tend to favor methods biased towards low diversity in normal data, which does not align with real-world scenarios. Despite advancements in these benchmarks, contemporary anomaly detection methods often struggle with out-of-distribution generalization, particularly in classifying samples with subtle transformations during testing. These methods typically assume that normal samples during test time have distributions very similar to those in the training set, while anomalies are distributed much further away. However, real-world test samples often exhibit various levels of distribution shift while maintaining semantic consistency. Therefore, effectively generalizing to samples that have undergone semantic-preserving transformations, while accurately detecting normal samples whose semantic meaning has changed after transformation as anomalies, is crucial for the trustworthiness and reliability of a model. For example, although it is clear that rotation shifts the meaning for a car in the context of anomaly detection but preserves the meaning for a bird, current methods are likely to detect both as abnormal. This complexity underscores the necessity for dynamic learning procedures rooted in the intrinsic concept of outliers. To address this issue, we propose new testing protocols and a novel method called Knowledge Exposure (KE), which integrates external knowledge to comprehend concept dynamics and differentiate transformations that induce semantic shifts. This approach enhances generalization by utilizing insights from a pre-trained CLIP model to evaluate the significance of anomalies for each concept. Evaluation on CIFAR-10, CIFAR-100, and SVHN with the new protocols demonstrates superior performance compared to previous methods.
Benchmarking Vision-Language Contrastive Methods for Medical Representation Learning
Jun 11, 2024



We perform a comprehensive benchmarking of contrastive frameworks for learning multimodal representations in the medical domain. Through this study, we aim to answer the following research questions: (i) How transferable are general-domain representations to the medical domain? (ii) Is multimodal contrastive training sufficient, or does it benefit from unimodal training as well? (iii) What is the impact of feature granularity on the effectiveness of multimodal medical representation learning? To answer these questions, we investigate eight contrastive learning approaches under identical training setups, and train them on 2.8 million image-text pairs from four datasets, and evaluate them on 25 downstream tasks, including classification (zero-shot and linear probing), image-to-text and text-to-image retrieval, and visual question-answering. Our findings suggest a positive answer to the first question, a negative answer to the second question, and the benefit of learning fine-grained features. Finally, we make our code publicly available.
Can Generative Models Improve Self-Supervised Representation Learning?
Mar 09, 2024



The rapid advancement in self-supervised learning (SSL) has highlighted its potential to leverage unlabeled data for learning powerful visual representations. However, existing SSL approaches, particularly those employing different views of the same image, often rely on a limited set of predefined data augmentations. This constrains the diversity and quality of transformations, which leads to sub-optimal representations. In this paper, we introduce a novel framework that enriches the SSL paradigm by utilizing generative models to produce semantically consistent image augmentations. By directly conditioning generative models on a source image representation, our method enables the generation of diverse augmentations while maintaining the semantics of the source image, thus offering a richer set of data for self-supervised learning. Our experimental results demonstrate that our framework significantly enhances the quality of learned visual representations. This research demonstrates that incorporating generative models into the SSL workflow opens new avenues for exploring the potential of unlabeled visual data. This development paves the way for more robust and versatile representation learning techniques.
Are Out-of-Distribution Detection Methods Reliable?
Nov 20, 2022

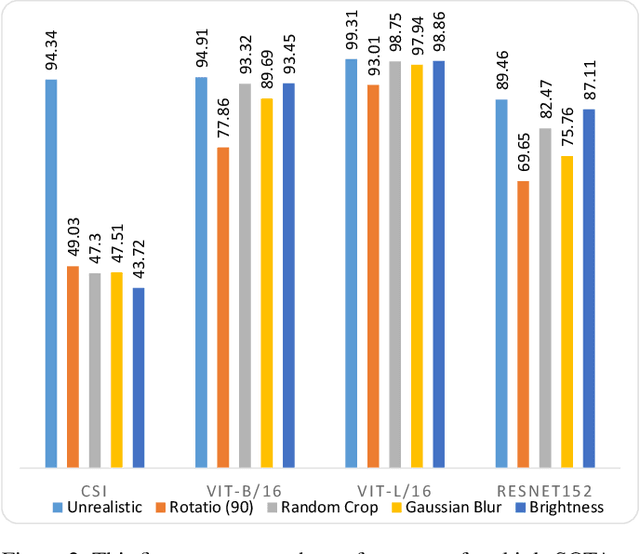

This paper establishes a novel evaluation framework for assessing the performance of out-of-distribution (OOD) detection in realistic settings. Our goal is to expose the shortcomings of existing OOD detection benchmarks and encourage a necessary research direction shift toward satisfying the requirements of real-world applications. We expand OOD detection research by introducing new OOD test datasets CIFAR-10-R, CIFAR-100-R, and MVTec-R, which allow researchers to benchmark OOD detection performance under realistic distribution shifts. We also introduce a generalizability score to measure a method's ability to generalize from standard OOD detection test datasets to a realistic setting. Contrary to existing OOD detection research, we demonstrate that further performance improvements on standard benchmark datasets do not increase the usability of such models in the real world. State-of-the-art (SOTA) methods tested on our realistic distributionally-shifted datasets drop in performance for up to 45%. This setting is critical for evaluating the reliability of OOD models before they are deployed in real-world environments.
Augment to Detect Anomalies with Continuous Labelling
Jul 03, 2022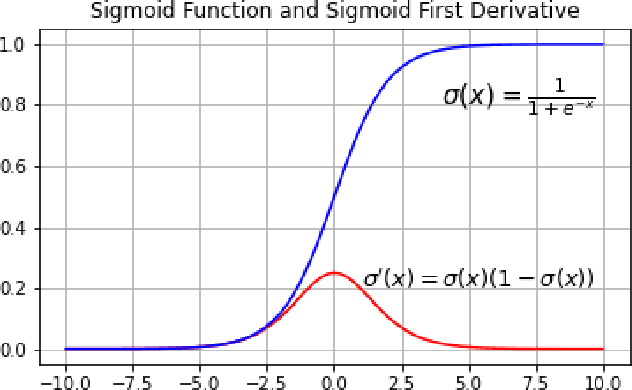
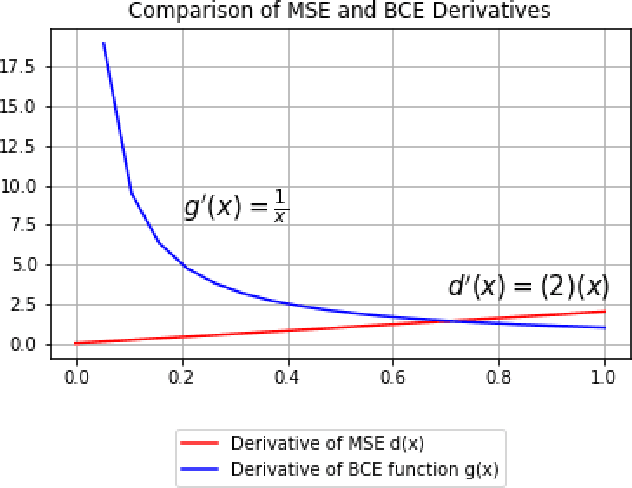

Anomaly detection is to recognize samples that differ in some respect from the training observations. These samples which do not conform to the distribution of normal data are called outliers or anomalies. In real-world anomaly detection problems, the outliers are absent, not well defined, or have a very limited number of instances. Recent state-of-the-art deep learning-based anomaly detection methods suffer from high computational cost, complexity, unstable training procedures, and non-trivial implementation, making them difficult to deploy in real-world applications. To combat this problem, we leverage a simple learning procedure that trains a lightweight convolutional neural network, reaching state-of-the-art performance in anomaly detection. In this paper, we propose to solve anomaly detection as a supervised regression problem. We label normal and anomalous data using two separable distributions of continuous values. To compensate for the unavailability of anomalous samples during training time, we utilize straightforward image augmentation techniques to create a distinct set of samples as anomalies. The distribution of the augmented set is similar but slightly deviated from the normal data, whereas real anomalies are expected to have an even further distribution. Therefore, training a regressor on these augmented samples will result in more separable distributions of labels for normal and real anomalous data points. Anomaly detection experiments on image and video datasets show the superiority of the proposed method over the state-of-the-art approaches.