 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Anomaly Detection Generalization through Knowledge Exposure: The Dual Effects of Augmentation
Jun 15, 2024



Anomaly detection involves identifying instances within a dataset that deviate from the norm and occur infrequently. Current benchmarks tend to favor methods biased towards low diversity in normal data, which does not align with real-world scenarios. Despite advancements in these benchmarks, contemporary anomaly detection methods often struggle with out-of-distribution generalization, particularly in classifying samples with subtle transformations during testing. These methods typically assume that normal samples during test time have distributions very similar to those in the training set, while anomalies are distributed much further away. However, real-world test samples often exhibit various levels of distribution shift while maintaining semantic consistency. Therefore, effectively generalizing to samples that have undergone semantic-preserving transformations, while accurately detecting normal samples whose semantic meaning has changed after transformation as anomalies, is crucial for the trustworthiness and reliability of a model. For example, although it is clear that rotation shifts the meaning for a car in the context of anomaly detection but preserves the meaning for a bird, current methods are likely to detect both as abnormal. This complexity underscores the necessity for dynamic learning procedures rooted in the intrinsic concept of outliers. To address this issue, we propose new testing protocols and a novel method called Knowledge Exposure (KE), which integrates external knowledge to comprehend concept dynamics and differentiate transformations that induce semantic shifts. This approach enhances generalization by utilizing insights from a pre-trained CLIP model to evaluate the significance of anomalies for each concept. Evaluation on CIFAR-10, CIFAR-100, and SVHN with the new protocols demonstrates superior performance compared to previous methods.
Layer-wise Regularized Adversarial Training using Layers Sustainability Analysis (LSA) framework
Feb 15, 2022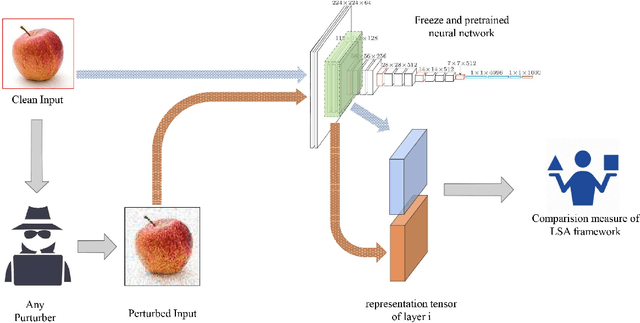


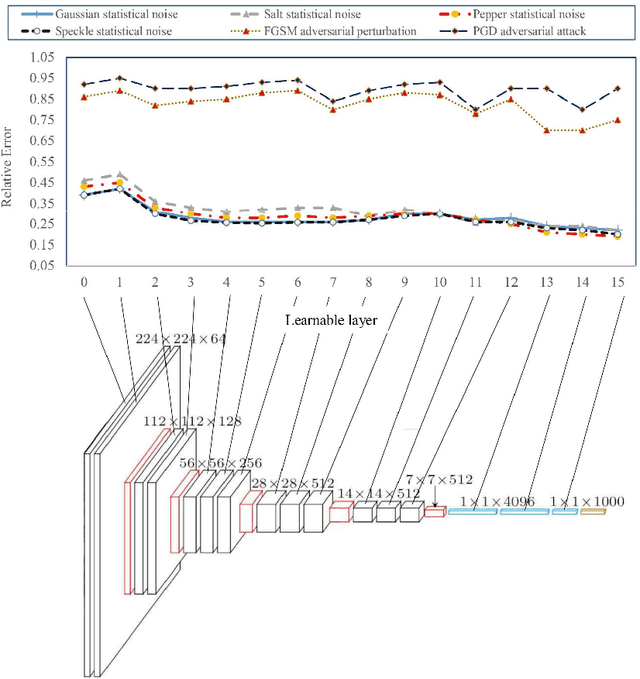
Deep neural network models are used today in various applications of artificial intelligence, the strengthening of which, in the face of adversarial attacks is of particular importance. An appropriate solution to adversarial attacks is adversarial training, which reaches a trade-off between robustness and generalization. This paper introduces a novel framework (Layer Sustainability Analysis (LSA)) for the analysis of layer vulnerability in an arbitrary neural network in the scenario of adversarial attacks. LSA can be a helpful toolkit to assess deep neural networks and to extend the adversarial training approaches towards improving the sustainability of model layers via layer monitoring and analysis. The LSA framework identifies a list of Most Vulnerable Layers (MVL list) of the given network. The relative error, as a comparison measure, is used to evaluate representation sustainability of each layer against adversarial inputs. The proposed approach for obtaining robust neural networks to fend off adversarial attacks is based on a layer-wise regularization (LR) over LSA proposal(s) for adversarial training (AT); i.e. the AT-LR procedure. AT-LR could be used with any benchmark adversarial attack to reduce the vulnerability of network layers and to improve conventional adversarial training approaches. The proposed idea performs well theoretically and experimentally for state-of-the-art multilayer perceptron and convolutional neural network architectures. Compared with the AT-LR and its corresponding base adversarial training, the classification accuracy of more significant perturbations increased by 16.35%, 21.79%, and 10.730% on Moon, MNIST, and CIFAR-10 benchmark datasets, respectively. The LSA framework is available and published at https://github.com/khalooei/LSA.
Learning Diverse Latent Representations for Improving the Resilience to Adversarial Attacks
Jul 12, 2020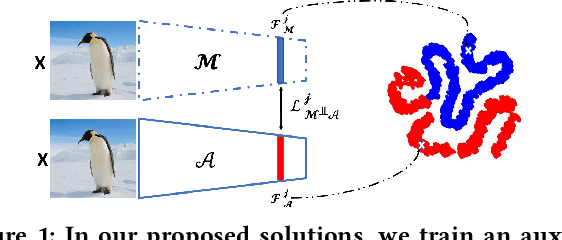
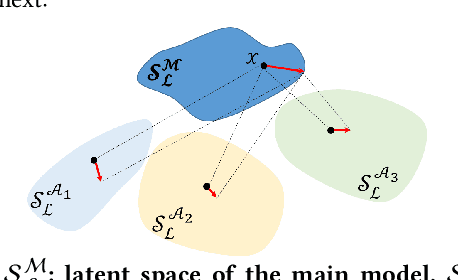
This paper proposes an ensemble learning model that is resistant to adversarial learning attacks. To build resilience, we proposed a training process where each member learns a radically different latent space. Member models are added one at a time to the ensemble. Each model is trained on data set to improve accuracy, while the loss function is regulated by a reverse knowledge distillation, forcing the new member to learn new features and map to a latent space safely distanced from those of existing members. We have evaluated the reliability and performance of the proposed solution on image classification tasks using CIFAR10 and MNIST datasets and show improved performance compared to the state of the art defense methods
Self-Supervised Representation Learning via Neighborhood-Relational Encoding
Aug 27, 2019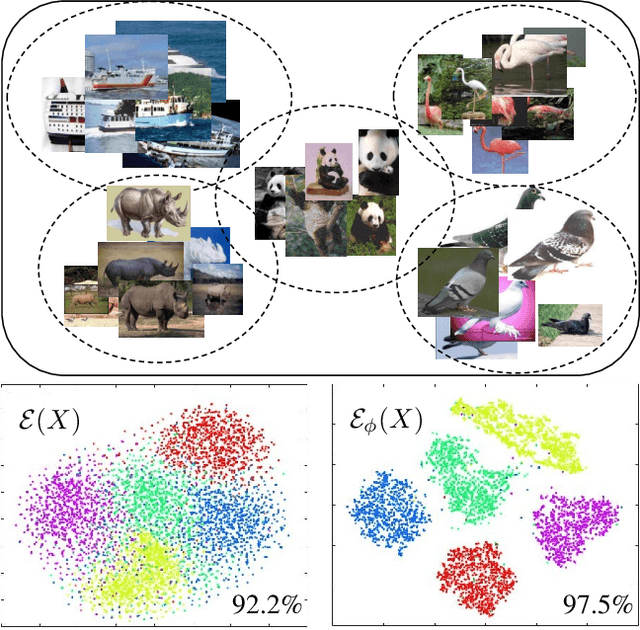

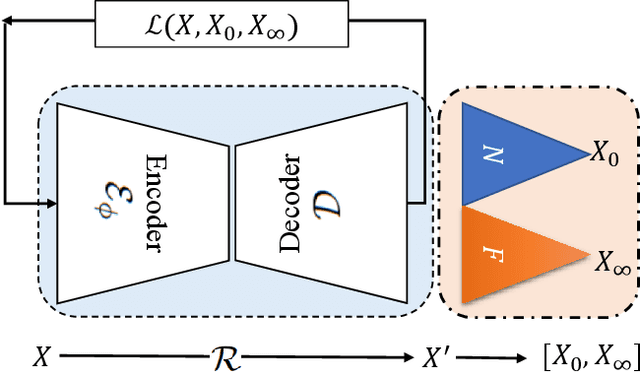

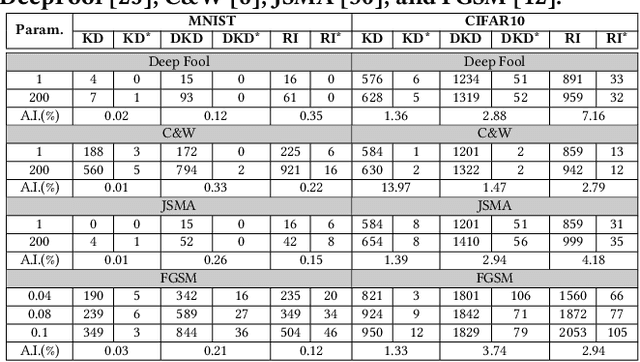
In this paper, we propose a novel self-supervised representation learning by taking advantage of a neighborhood-relational encoding (NRE) among the training data. Conventional unsupervised learning methods only focused on training deep networks to understand the primitive characteristics of the visual data, mainly to be able to reconstruct the data from a latent space. They often neglected the relation among the samples, which can serve as an important metric for self-supervision. Different from the previous work, NRE aims at preserving the local neighborhood structure on the data manifold. Therefore, it is less sensitive to outliers. We integrate our NRE component with an encoder-decoder structure for learning to represent samples considering their local neighborhood information. Such discriminative and unsupervised representation learning scheme is adaptable to different computer vision tasks due to its independence from intense annotation requirements. We evaluate our proposed method for different tasks, including classification, detection, and segmentation based on the learned latent representations. In addition, we adopt the auto-encoding capability of our proposed method for applications like defense against adversarial example attacks and video anomaly detection. Results confirm the performance of our method is better or at least comparable with the state-of-the-art for each specific application, but with a generic and self-supervised approach.
Adversarially Learned One-Class Classifier for Novelty Detection
May 24, 2018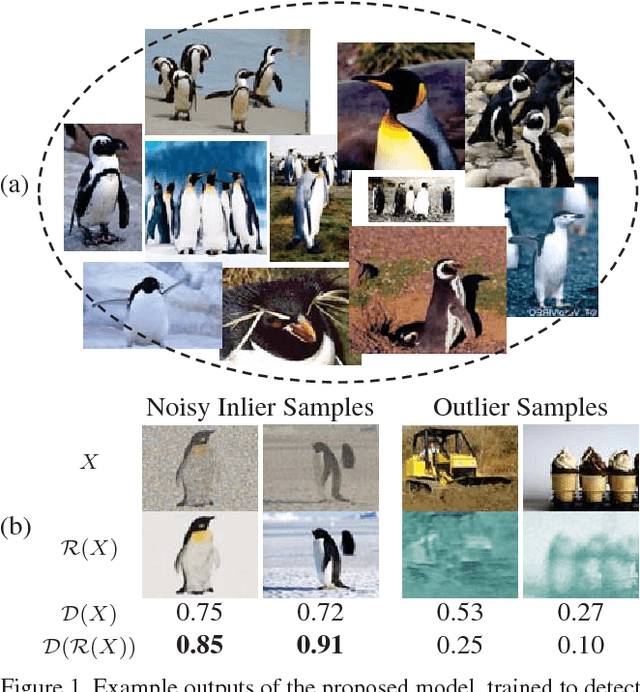
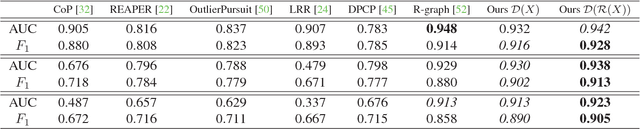
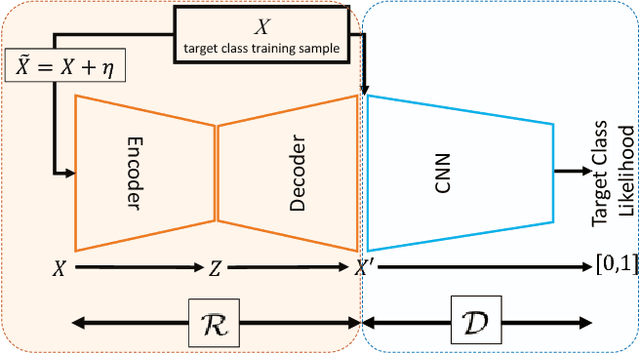
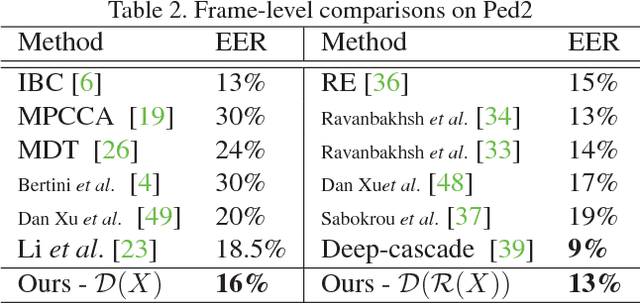
Novelty detection is the process of identifying the observation(s) that differ in some respect from the training observations (the target class). In reality, the novelty class is often absent during training, poorly sampled or not well defined. Therefore, one-class classifiers can efficiently model such problems. However, due to the unavailability of data from the novelty class, training an end-to-end deep network is a cumbersome task. In this paper, inspired by the success of generative adversarial networks for training deep models in unsupervised and semi-supervised settings, we propose an end-to-end architecture for one-class classification. Our architecture is composed of two deep networks, each of which trained by competing with each other while collaborating to understand the underlying concept in the target class, and then classify the testing samples. One network works as the novelty detector, while the other supports it by enhancing the inlier samples and distorting the outliers. The intuition is that the separability of the enhanced inliers and distorted outliers is much better than deciding on the original samples. The proposed framework applies to different related applications of anomaly and outlier detection in images and videos. The results on MNIST and Caltech-256 image datasets, along with the challenging UCSD Ped2 dataset for video anomaly detection illustrate that our proposed method learns the target class effectively and is superior to the baseline and state-of-the-art methods.