 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive-Gravity: A Defense Against Adversarial Samples
Apr 07, 2022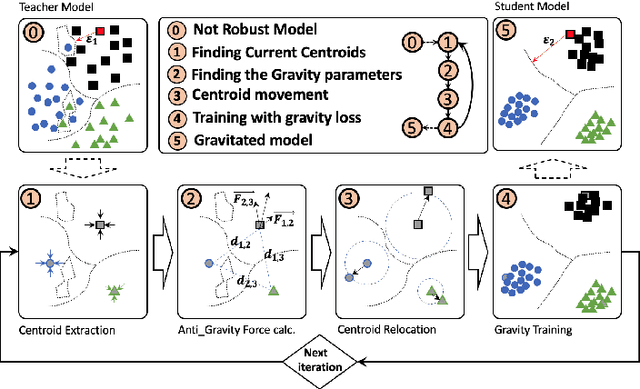
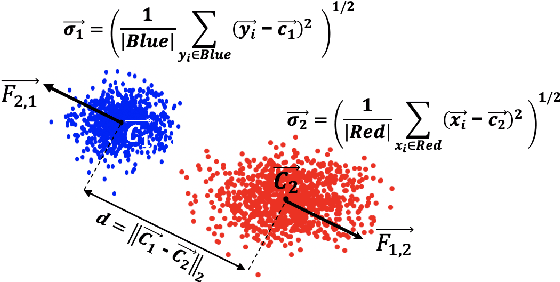
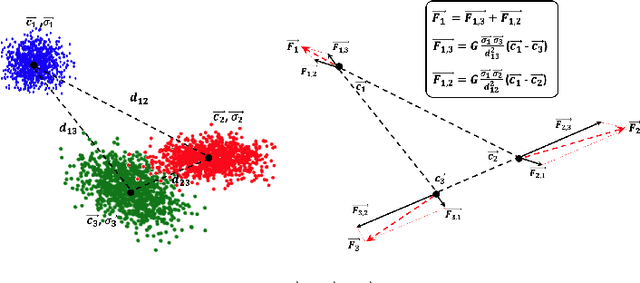
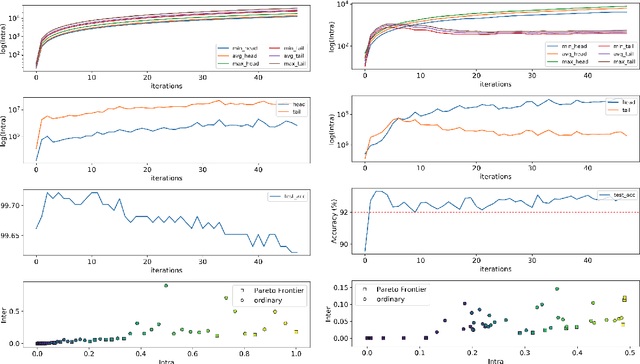
This paper presents a novel model training solution, denoted as Adaptive-Gravity, for enhancing the robustness of deep neural network classifiers against adversarial examples. We conceptualize the model parameters/features associated with each class as a mass characterized by its centroid location and the spread (standard deviation of the distance) of features around the centroid. We use the centroid associated with each cluster to derive an anti-gravity force that pushes the centroids of different classes away from one another during network training. Then we customized an objective function that aims to concentrate each class's features toward their corresponding new centroid, which has been obtained by anti-gravity force. This methodology results in a larger separation between different masses and reduces the spread of features around each centroid. As a result, the samples are pushed away from the space that adversarial examples could be mapped to, effectively increasing the degree of perturbation needed for making an adversarial example. We have implemented this training solution as an iterative method consisting of four steps at each iteration: 1) centroid extraction, 2) anti-gravity force calculation, 3) centroid relocation, and 4) gravity training. Gravity's efficiency is evaluated by measuring the corresponding fooling rates against various attack models, including FGSM, MIM, BIM, and PGD using LeNet and ResNet110 networks, benchmarked against MNIST and CIFAR10 classification problems. Test results show that Gravity not only functions as a powerful instrument to robustify a model against state-of-the-art adversarial attacks but also effectively improves the model training accuracy.
Learning Diverse Latent Representations for Improving the Resilience to Adversarial Attacks
Jul 12, 2020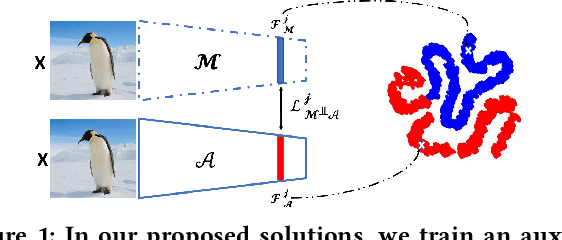
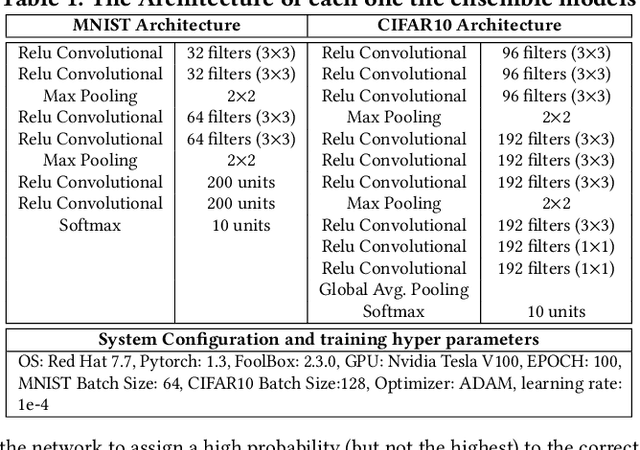
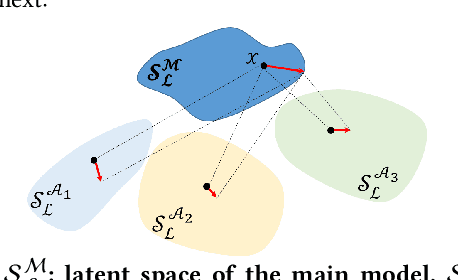
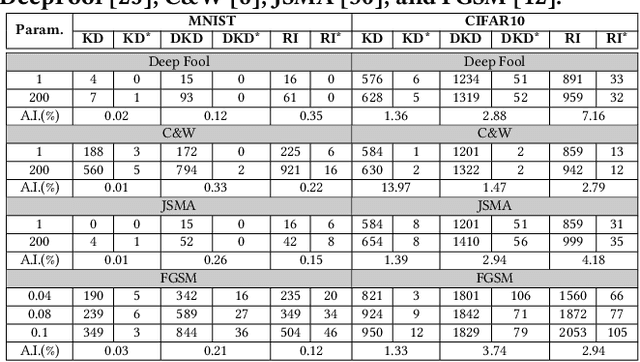
This paper proposes an ensemble learning model that is resistant to adversarial learning attacks. To build resilience, we proposed a training process where each member learns a radically different latent space. Member models are added one at a time to the ensemble. Each model is trained on data set to improve accuracy, while the loss function is regulated by a reverse knowledge distillation, forcing the new member to learn new features and map to a latent space safely distanced from those of existing members. We have evaluated the reliability and performance of the proposed solution on image classification tasks using CIFAR10 and MNIST datasets and show improved performance compared to the state of the art defense methods
Cluster-Based Partitioning of Convolutional Neural Networks, A Solution for Computational Energy and Complexity Reduction
Jul 12, 2020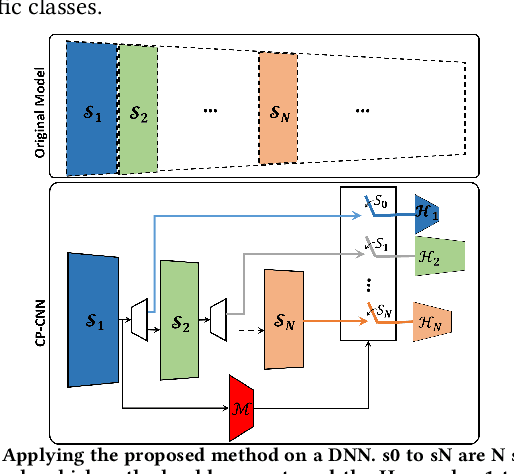
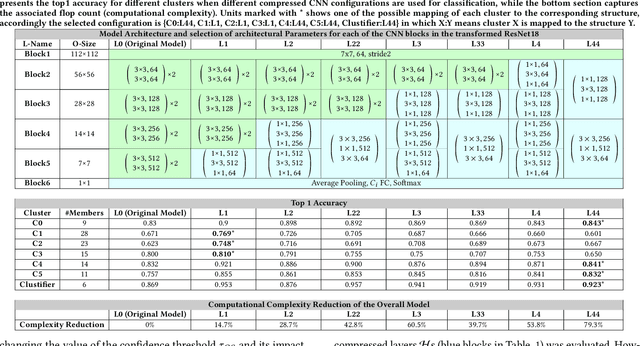
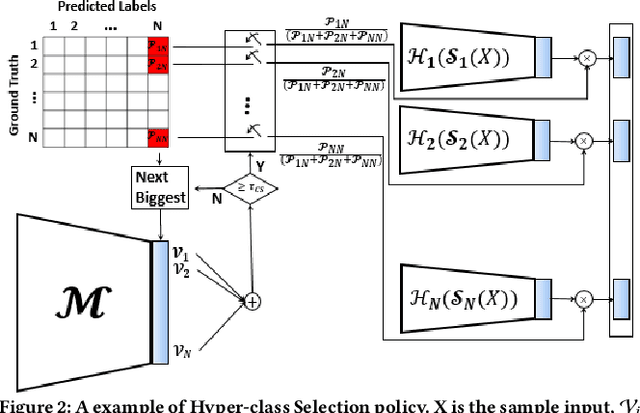
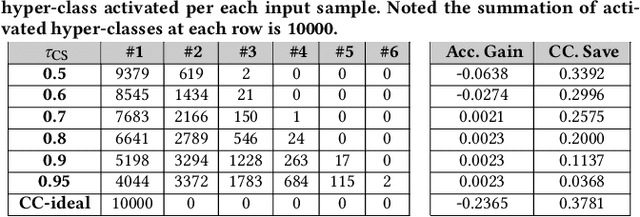
In this paper, we propose a novel solution to reduce the computational complexity of convolutional neural network models used for many class image classification. Our proposed model breaks the classification task into three stages: 1) general feature extraction, 2) Mid-level clustering, and 3) hyper-class classification. Steps 1 and 2 could be repeated to build larger hierarchical models. We illustrate that our proposed classifier can reach the level of accuracy reported by the best in class classification models with far less computational complexity (Flop Count) by only activating parts of the model that are needed for the image classification.
Code-Bridged Classifier : A Low or Negative Overhead Defense for Making a CNN Classifier Robust Against Adversarial Attacks
Jan 16, 2020
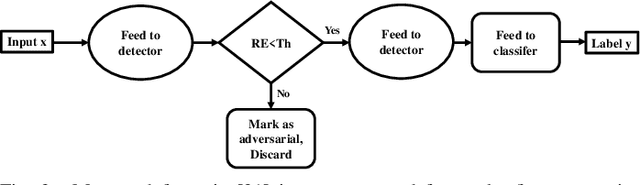
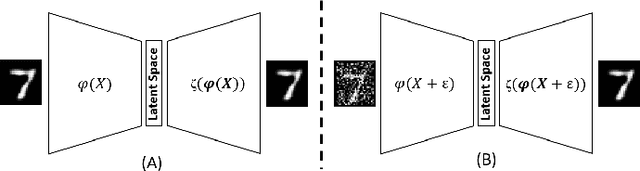
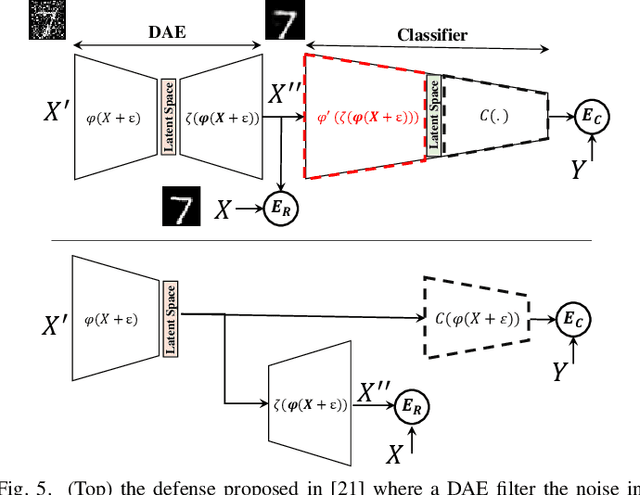
In this paper, we propose Code-Bridged Classifier (CBC), a framework for making a Convolutional Neural Network (CNNs) robust against adversarial attacks without increasing or even by decreasing the overall models' computational complexity. More specifically, we propose a stacked encoder-convolutional model, in which the input image is first encoded by the encoder module of a denoising auto-encoder, and then the resulting latent representation (without being decoded) is fed to a reduced complexity CNN for image classification. We illustrate that this network not only is more robust to adversarial examples but also has a significantly lower computational complexity when compared to the prior art defenses.
TCD-NPE: A Re-configurable and Efficient Neural Processing Engine, Powered by Novel Temporal-Carry-deferring MACs
Oct 14, 2019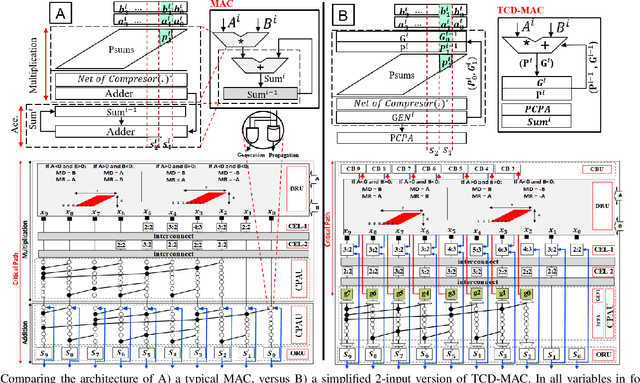
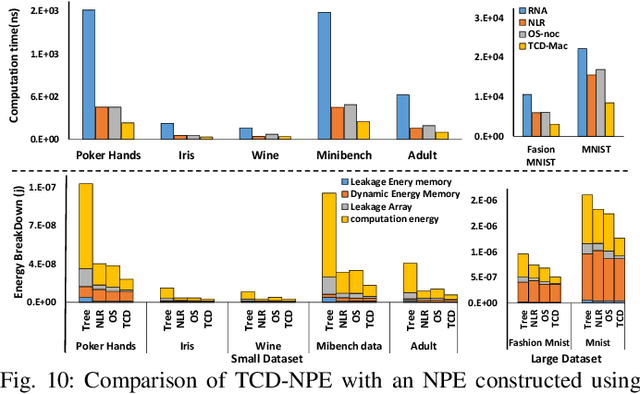
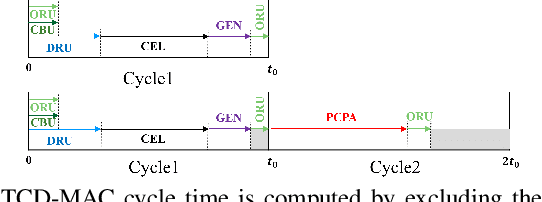
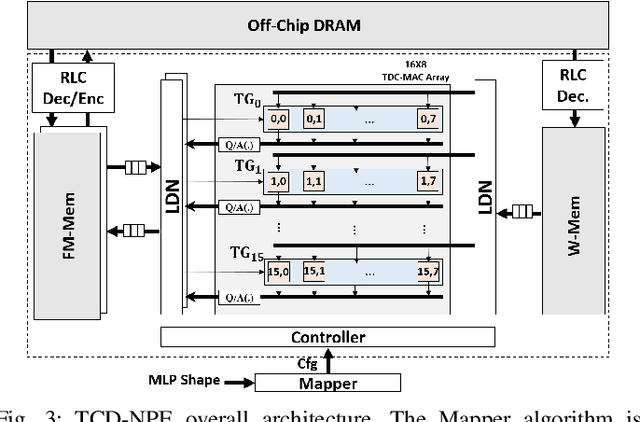
In this paper, we first propose the design of Temporal-Carry-deferring MAC (TCD-MAC) and illustrate how our proposed solution can gain significant energy and performance benefit when utilized to process a stream of input data. We then propose using the TCD-MAC to build a reconfigurable, high speed, and low power Neural Processing Engine (TCD-NPE). We, further, propose a novel scheduler that lists the sequence of needed processing events to process an MLP model in the least number of computational rounds in our proposed TCD-NPE. We illustrate that our proposed TCD-NPE significantly outperform similar neural processing solutions that use conventional MACs in terms of both energy consumption and execution time.
NESTA: Hamming Weight Compression-Based Neural Proc. Engine
Oct 01, 2019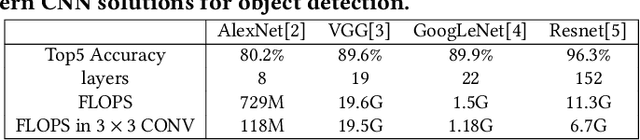
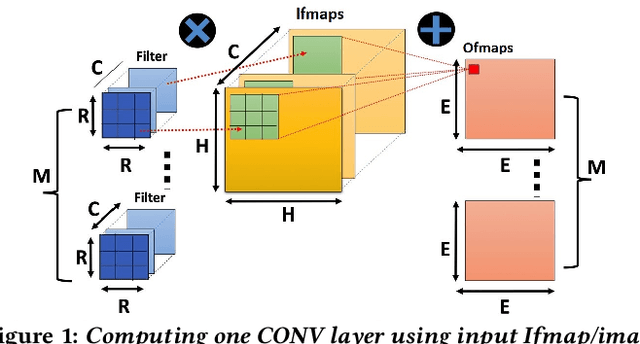
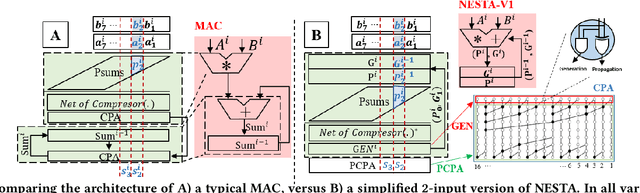
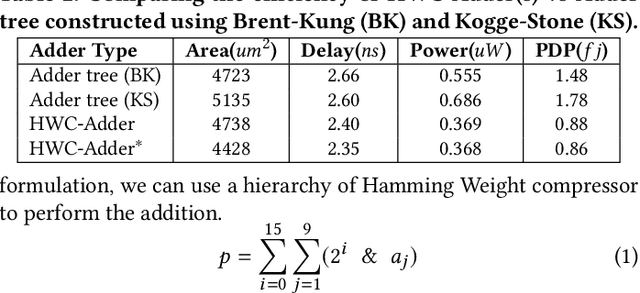
In this paper, we present NESTA, a specialized Neural engine that significantly accelerates the computation of convolution layers in a deep convolutional neural network, while reducing the computational energy. NESTA reformats Convolutions into $3 \times 3$ batches and uses a hierarchy of Hamming Weight Compressors to process each batch. Besides, when processing the convolution across multiple channels, NESTA, rather than computing the precise result of a convolution per channel, quickly computes an approximation of its partial sum, and a residual value such that if added to the approximate partial sum, generates the accurate output. Then, instead of immediately adding the residual, it uses (consumes) the residual when processing the next batch in the hamming weight compressors with available capacity. This mechanism shortens the critical path by avoiding the need to propagate carry signals during each round of computation and speeds up the convolution of each channel. In the last stage of computation, when the partial sum of the last channel is computed, NESTA terminates by adding the residual bits to the approximate output to generate a correct result.