 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFFCL: Forward-Forward Net with Cortical Loops, Training and Inference on Edge Without Backpropagation
May 21, 2024



The Forward-Forward Learning (FFL) algorithm is a recently proposed solution for training neural networks without needing memory-intensive backpropagation. During training, labels accompany input data, classifying them as positive or negative inputs. Each layer learns its response to these inputs independently. In this study, we enhance the FFL with the following contributions: 1) We optimize label processing by segregating label and feature forwarding between layers, enhancing learning performance. 2) By revising label integration, we enhance the inference process, reduce computational complexity, and improve performance. 3) We introduce feedback loops akin to cortical loops in the brain, where information cycles through and returns to earlier neurons, enabling layers to combine complex features from previous layers with lower-level features, enhancing learning efficiency.
Generative AI-Based Effective Malware Detection for Embedded Computing Systems
Apr 12, 2024



One of the pivotal security threats for the embedded computing systems is malicious software a.k.a malware. With efficiency and efficacy, Machine Learning (ML) has been widely adopted for malware detection in recent times. Despite being efficient, the existing techniques require a tremendous number of benign and malware samples for training and modeling an efficient malware detector. Furthermore, such constraints limit the detection of emerging malware samples due to the lack of sufficient malware samples required for efficient training. To address such concerns, we introduce a code-aware data generation technique that generates multiple mutated samples of the limitedly seen malware by the devices. Loss minimization ensures that the generated samples closely mimic the limitedly seen malware and mitigate the impractical samples. Such developed malware is further incorporated into the training set to formulate the model that can efficiently detect the emerging malware despite having limited exposure. The experimental results demonstrates that the proposed technique achieves an accuracy of 90% in detecting limitedly seen malware, which is approximately 3x more than the accuracy attained by state-of-the-art techniques.
HW-V2W-Map: Hardware Vulnerability to Weakness Mapping Framework for Root Cause Analysis with GPT-assisted Mitigation Suggestion
Dec 21, 2023The escalating complexity of modern computing frameworks has resulted in a surge in the cybersecurity vulnerabilities reported to the National Vulnerability Database (NVD) by practitioners. Despite the fact that the stature of NVD is one of the most significant databases for the latest insights into vulnerabilities, extracting meaningful trends from such a large amount of unstructured data is still challenging without the application of suitable technological methodologies. Previous efforts have mostly concentrated on software vulnerabilities; however, a holistic strategy incorporates approaches for mitigating vulnerabilities, score prediction, and a knowledge-generating system that may extract relevant insights from the Common Weakness Enumeration (CWE) and Common Vulnerability Exchange (CVE) databases is notably absent. As the number of hardware attacks on Internet of Things (IoT) devices continues to rapidly increase, we present the Hardware Vulnerability to Weakness Mapping (HW-V2W-Map) Framework, which is a Machine Learning (ML) framework focusing on hardware vulnerabilities and IoT security. The architecture that we have proposed incorporates an Ontology-driven Storytelling framework, which automates the process of updating the ontology in order to recognize patterns and evolution of vulnerabilities over time and provides approaches for mitigating the vulnerabilities. The repercussions of vulnerabilities can be mitigated as a result of this, and conversely, future exposures can be predicted and prevented. Furthermore, our proposed framework utilized Generative Pre-trained Transformer (GPT) Large Language Models (LLMs) to provide mitigation suggestions.
SMOOT: Saliency Guided Mask Optimized Online Training
Oct 10, 2023



Deep Neural Networks are powerful tools for understanding complex patterns and making decisions. However, their black-box nature impedes a complete understanding of their inner workings. Saliency-Guided Training (SGT) methods try to highlight the prominent features in the model's training based on the output to alleviate this problem. These methods use back-propagation and modified gradients to guide the model toward the most relevant features while keeping the impact on the prediction accuracy negligible. SGT makes the model's final result more interpretable by masking input partially. In this way, considering the model's output, we can infer how each segment of the input affects the output. In the particular case of image as the input, masking is applied to the input pixels. However, the masking strategy and number of pixels which we mask, are considered as a hyperparameter. Appropriate setting of masking strategy can directly affect the model's training. In this paper, we focus on this issue and present our contribution. We propose a novel method to determine the optimal number of masked images based on input, accuracy, and model loss during the training. The strategy prevents information loss which leads to better accuracy values. Also, by integrating the model's performance in the strategy formula, we show that our model represents the salient features more meaningful. Our experimental results demonstrate a substantial improvement in both model accuracy and the prominence of saliency, thereby affirming the effectiveness of our proposed solution.
Adaptive-Gravity: A Defense Against Adversarial Samples
Apr 07, 2022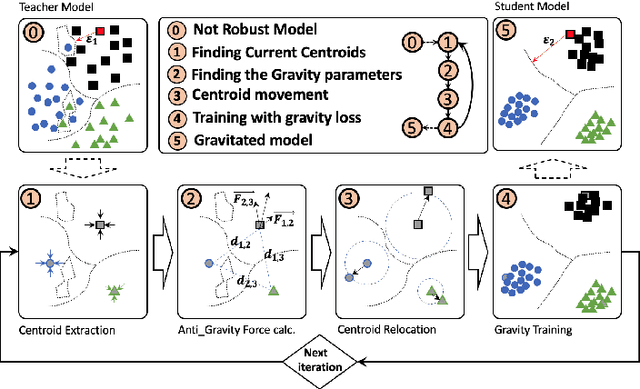
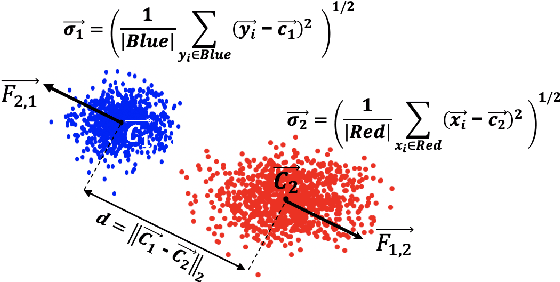
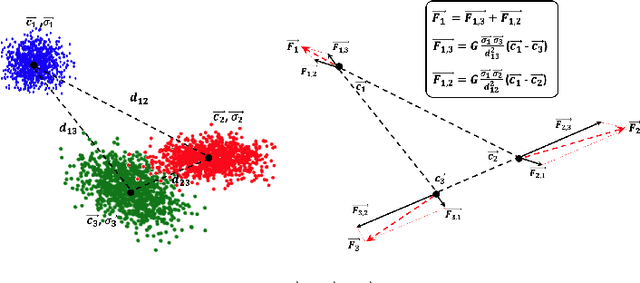
This paper presents a novel model training solution, denoted as Adaptive-Gravity, for enhancing the robustness of deep neural network classifiers against adversarial examples. We conceptualize the model parameters/features associated with each class as a mass characterized by its centroid location and the spread (standard deviation of the distance) of features around the centroid. We use the centroid associated with each cluster to derive an anti-gravity force that pushes the centroids of different classes away from one another during network training. Then we customized an objective function that aims to concentrate each class's features toward their corresponding new centroid, which has been obtained by anti-gravity force. This methodology results in a larger separation between different masses and reduces the spread of features around each centroid. As a result, the samples are pushed away from the space that adversarial examples could be mapped to, effectively increasing the degree of perturbation needed for making an adversarial example. We have implemented this training solution as an iterative method consisting of four steps at each iteration: 1) centroid extraction, 2) anti-gravity force calculation, 3) centroid relocation, and 4) gravity training. Gravity's efficiency is evaluated by measuring the corresponding fooling rates against various attack models, including FGSM, MIM, BIM, and PGD using LeNet and ResNet110 networks, benchmarked against MNIST and CIFAR10 classification problems. Test results show that Gravity not only functions as a powerful instrument to robustify a model against state-of-the-art adversarial attacks but also effectively improves the model training accuracy.
Learning Diverse Latent Representations for Improving the Resilience to Adversarial Attacks
Jul 12, 2020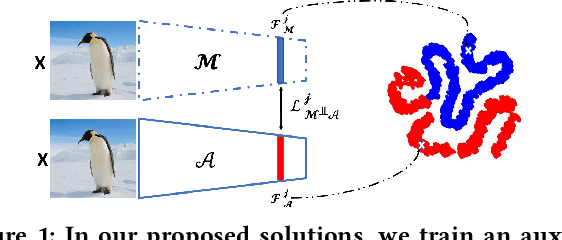
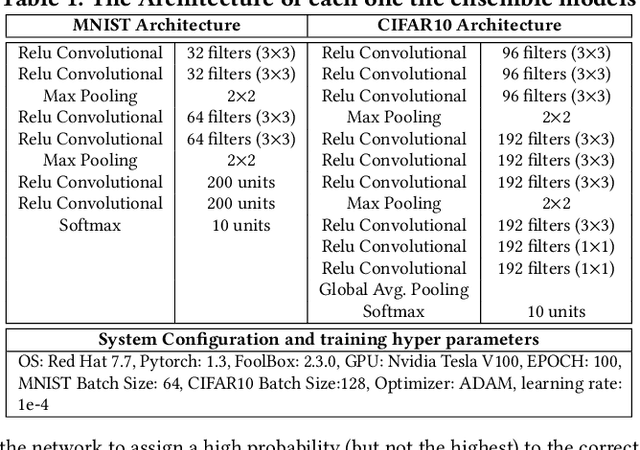
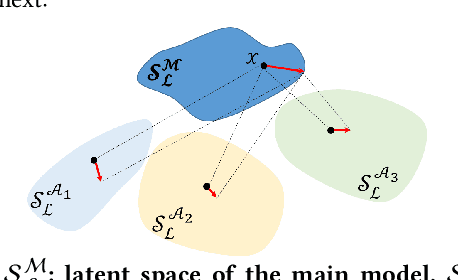
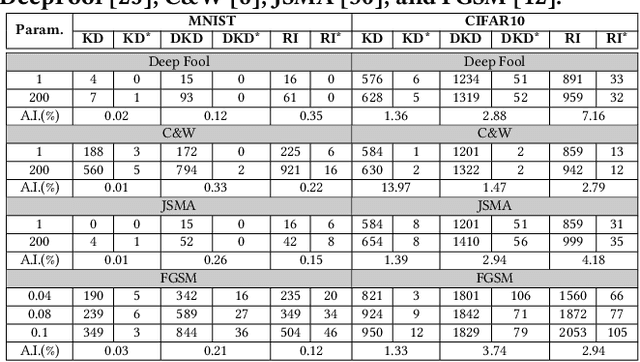
This paper proposes an ensemble learning model that is resistant to adversarial learning attacks. To build resilience, we proposed a training process where each member learns a radically different latent space. Member models are added one at a time to the ensemble. Each model is trained on data set to improve accuracy, while the loss function is regulated by a reverse knowledge distillation, forcing the new member to learn new features and map to a latent space safely distanced from those of existing members. We have evaluated the reliability and performance of the proposed solution on image classification tasks using CIFAR10 and MNIST datasets and show improved performance compared to the state of the art defense methods
Cluster-Based Partitioning of Convolutional Neural Networks, A Solution for Computational Energy and Complexity Reduction
Jul 12, 2020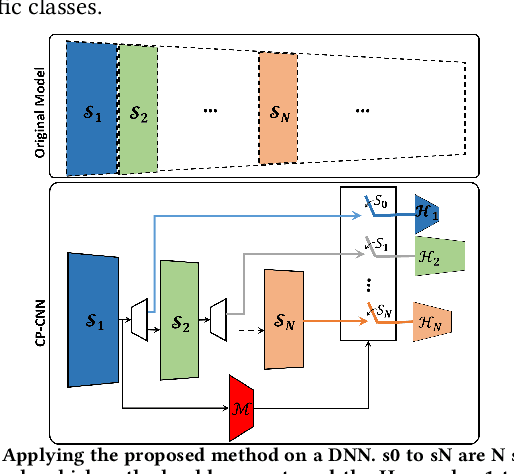
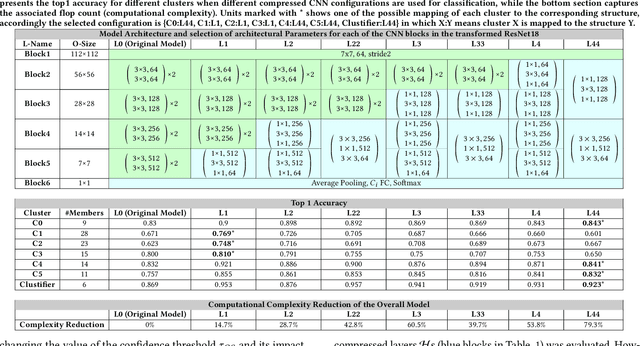
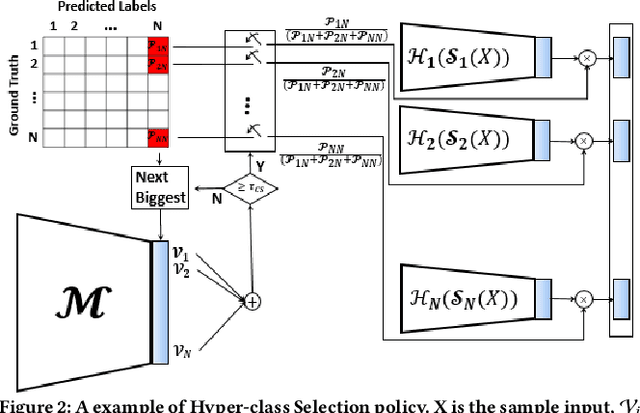
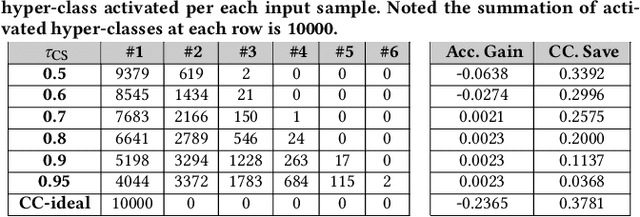
In this paper, we propose a novel solution to reduce the computational complexity of convolutional neural network models used for many class image classification. Our proposed model breaks the classification task into three stages: 1) general feature extraction, 2) Mid-level clustering, and 3) hyper-class classification. Steps 1 and 2 could be repeated to build larger hierarchical models. We illustrate that our proposed classifier can reach the level of accuracy reported by the best in class classification models with far less computational complexity (Flop Count) by only activating parts of the model that are needed for the image classification.
Code-Bridged Classifier : A Low or Negative Overhead Defense for Making a CNN Classifier Robust Against Adversarial Attacks
Jan 16, 2020
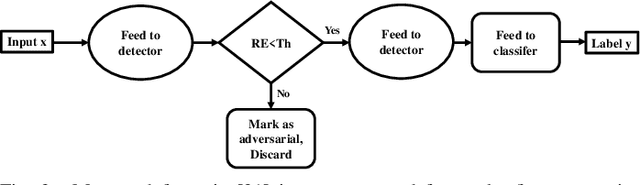
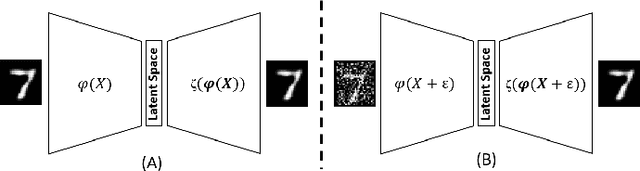
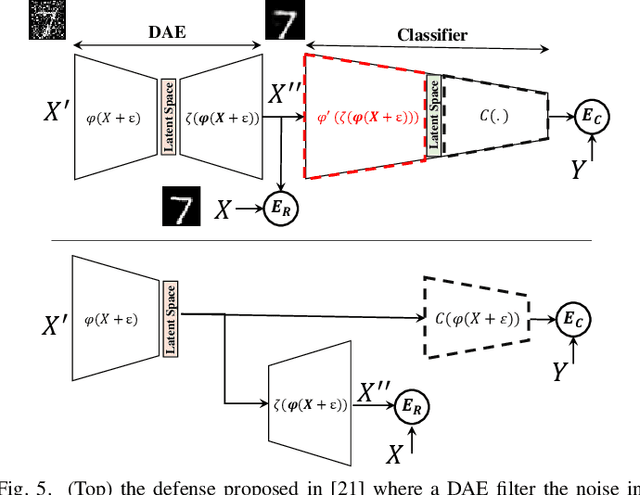
In this paper, we propose Code-Bridged Classifier (CBC), a framework for making a Convolutional Neural Network (CNNs) robust against adversarial attacks without increasing or even by decreasing the overall models' computational complexity. More specifically, we propose a stacked encoder-convolutional model, in which the input image is first encoded by the encoder module of a denoising auto-encoder, and then the resulting latent representation (without being decoded) is fed to a reduced complexity CNN for image classification. We illustrate that this network not only is more robust to adversarial examples but also has a significantly lower computational complexity when compared to the prior art defenses.
TCD-NPE: A Re-configurable and Efficient Neural Processing Engine, Powered by Novel Temporal-Carry-deferring MACs
Oct 14, 2019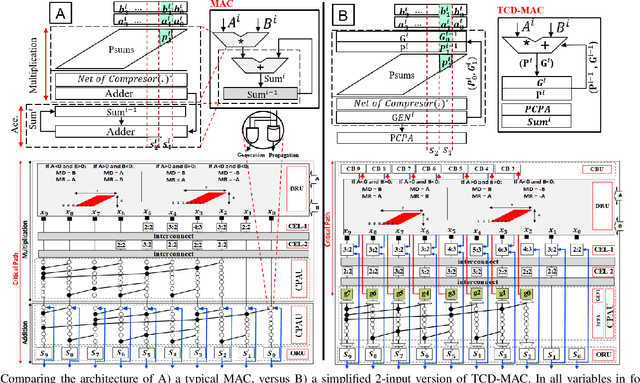
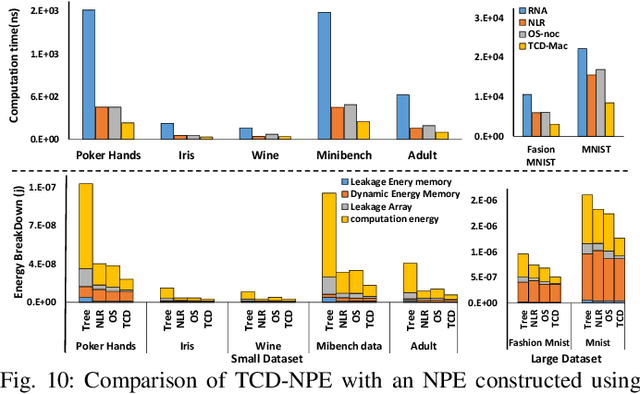
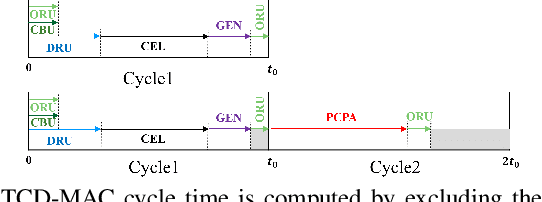
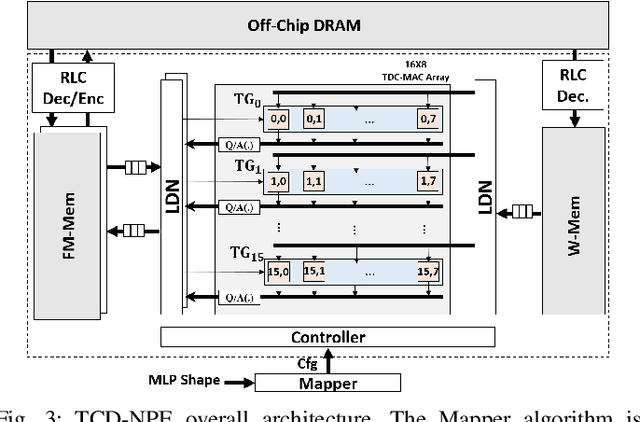
In this paper, we first propose the design of Temporal-Carry-deferring MAC (TCD-MAC) and illustrate how our proposed solution can gain significant energy and performance benefit when utilized to process a stream of input data. We then propose using the TCD-MAC to build a reconfigurable, high speed, and low power Neural Processing Engine (TCD-NPE). We, further, propose a novel scheduler that lists the sequence of needed processing events to process an MLP model in the least number of computational rounds in our proposed TCD-NPE. We illustrate that our proposed TCD-NPE significantly outperform similar neural processing solutions that use conventional MACs in terms of both energy consumption and execution time.
NESTA: Hamming Weight Compression-Based Neural Proc. Engine
Oct 01, 2019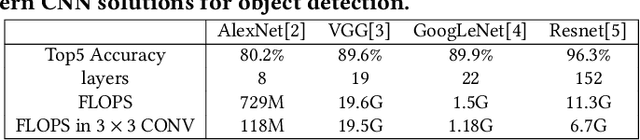
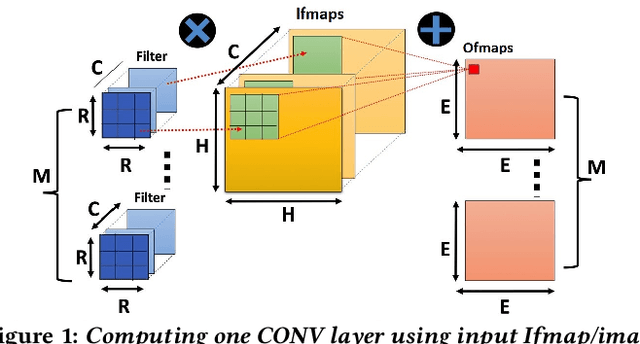
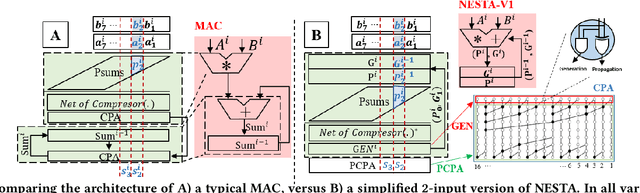
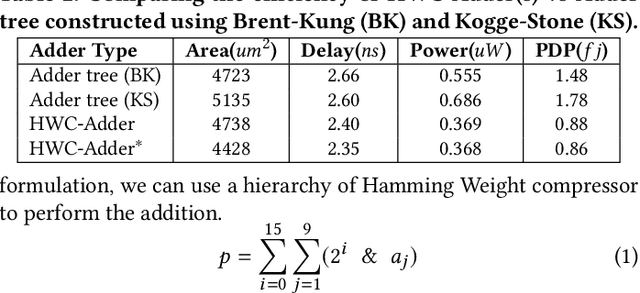
In this paper, we present NESTA, a specialized Neural engine that significantly accelerates the computation of convolution layers in a deep convolutional neural network, while reducing the computational energy. NESTA reformats Convolutions into $3 \times 3$ batches and uses a hierarchy of Hamming Weight Compressors to process each batch. Besides, when processing the convolution across multiple channels, NESTA, rather than computing the precise result of a convolution per channel, quickly computes an approximation of its partial sum, and a residual value such that if added to the approximate partial sum, generates the accurate output. Then, instead of immediately adding the residual, it uses (consumes) the residual when processing the next batch in the hamming weight compressors with available capacity. This mechanism shortens the critical path by avoiding the need to propagate carry signals during each round of computation and speeds up the convolution of each channel. In the last stage of computation, when the partial sum of the last channel is computed, NESTA terminates by adding the residual bits to the approximate output to generate a correct result.