 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAno-Graph: Learning Normal Scene Contextual Graphs to Detect Video Anomalies
Mar 18, 2021
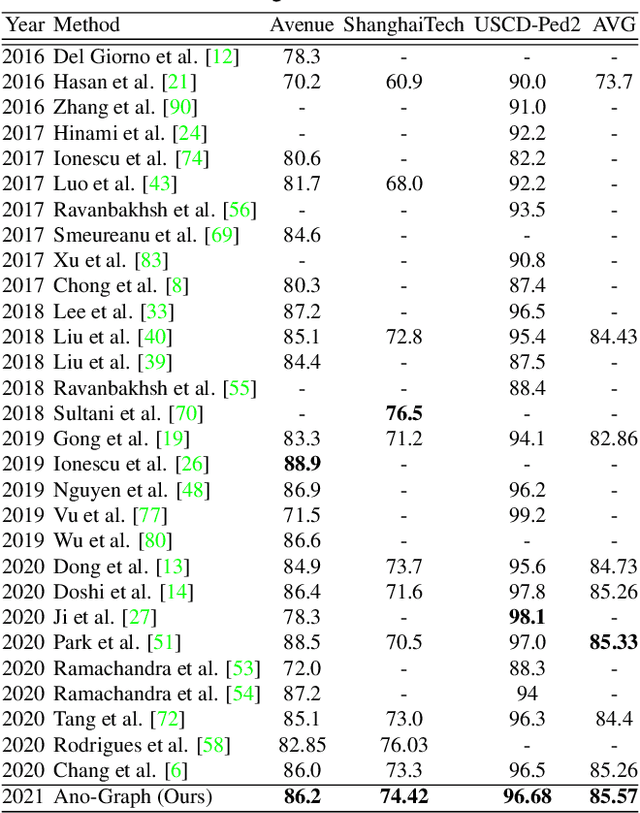
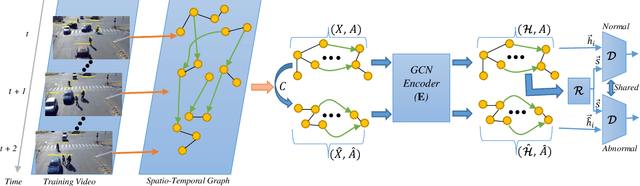
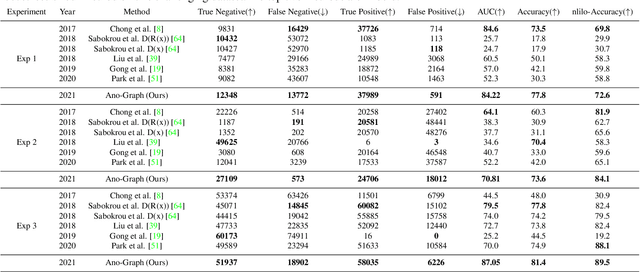
Video anomaly detection has proved to be a challenging task owing to its unsupervised training procedure and high spatio-temporal complexity existing in real-world scenarios. In the absence of anomalous training samples, state-of-the-art methods try to extract features that fully grasp normal behaviors in both space and time domains using different approaches such as autoencoders, or generative adversarial networks. However, these approaches completely ignore or, by using the ability of deep networks in the hierarchical modeling, poorly model the spatio-temporal interactions that exist between objects. To address this issue, we propose a novel yet efficient method named Ano-Graph for learning and modeling the interaction of normal objects. Towards this end, a Spatio-Temporal Graph (STG) is made by considering each node as an object's feature extracted from a real-time off-the-shelf object detector, and edges are made based on their interactions. After that, a self-supervised learning method is employed on the STG in such a way that encapsulates interactions in a semantic space. Our method is data-efficient, significantly more robust against common real-world variations such as illumination, and passes SOTA by a large margin on the challenging datasets ADOC and Street Scene while stays competitive on Avenue, ShanghaiTech, and UCSD.
Cluster-Based Partitioning of Convolutional Neural Networks, A Solution for Computational Energy and Complexity Reduction
Jul 12, 2020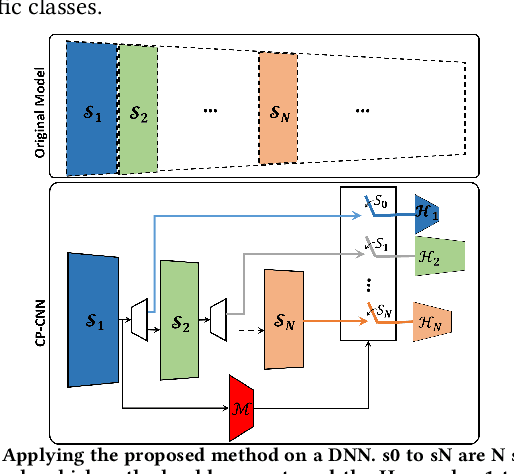
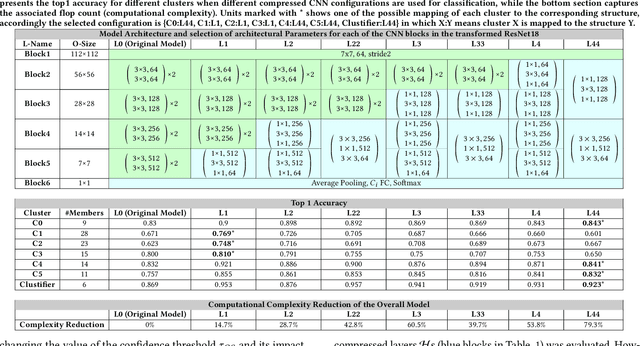
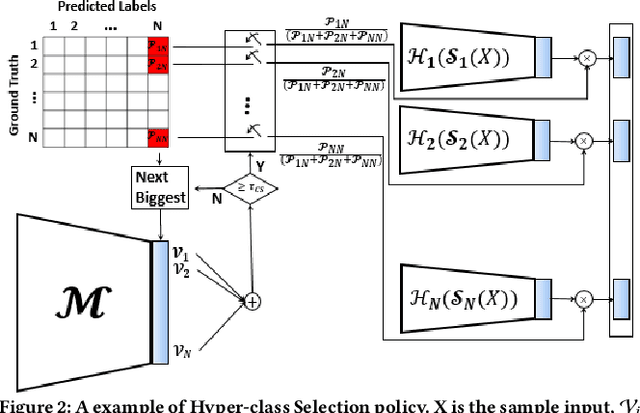
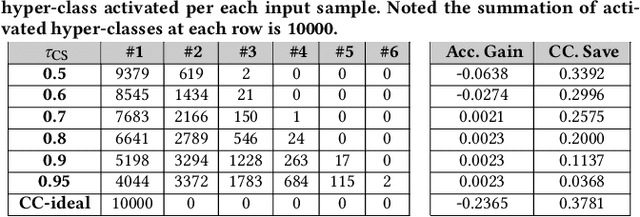
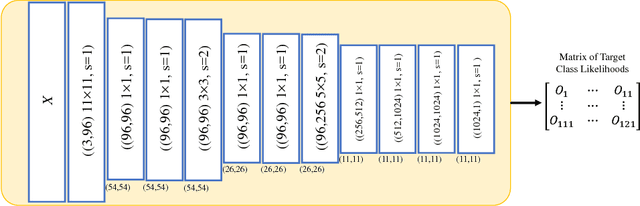
In this paper, we propose a novel solution to reduce the computational complexity of convolutional neural network models used for many class image classification. Our proposed model breaks the classification task into three stages: 1) general feature extraction, 2) Mid-level clustering, and 3) hyper-class classification. Steps 1 and 2 could be repeated to build larger hierarchical models. We illustrate that our proposed classifier can reach the level of accuracy reported by the best in class classification models with far less computational complexity (Flop Count) by only activating parts of the model that are needed for the image classification.
G2D: Generate to Detect Anomaly
Jun 27, 2020

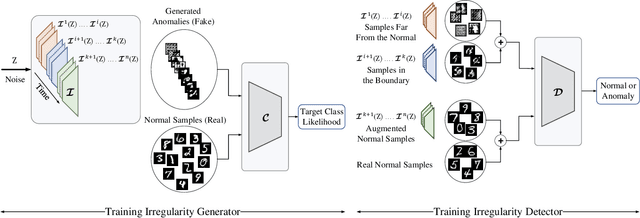
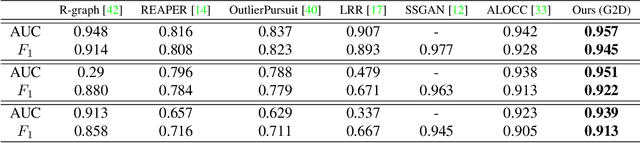
In this paper, we propose a novel method for irregularity detection. Previous researches solve this problem as a One-Class Classification (OCC) task where they train a reference model on all of the available samples. Then, they consider a test sample as an anomaly if it has a diversion from the reference model. Generative Adversarial Networks (GANs) have achieved the most promising results for OCC while implementing and training such networks, especially for the OCC task, is a cumbersome and computationally expensive procedure. To cope with the mentioned challenges, we present a simple but effective method to solve the irregularity detection as a binary classification task in order to make the implementation easier along with improving the detection performance. We learn two deep neural networks (generator and discriminator) in a GAN-style setting on merely the normal samples. During training, the generator gradually becomes an expert to generate samples which are similar to the normal ones. In the training phase, when the generator fails to produce normal data (in the early stages of learning and also prior to the complete convergence), it can be considered as an irregularity generator. In this way, we simultaneously generate the irregular samples. Afterward, we train a binary classifier on the generated anomalous samples along with the normal instances in order to be capable of detecting irregularities. The proposed framework applies to different related applications of outlier and anomaly detection in images and videos, respectively. The results confirm that our proposed method is superior to the baseline and state-of-the-art solutions.
Deep-HR: Fast Heart Rate Estimation from Face Video Under Realistic Conditions
Feb 12, 2020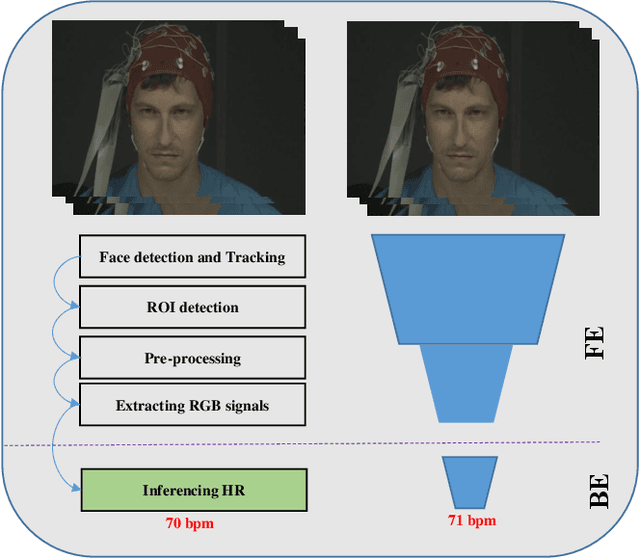
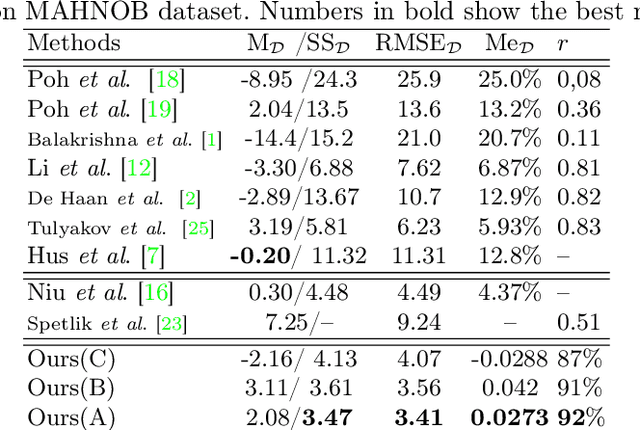
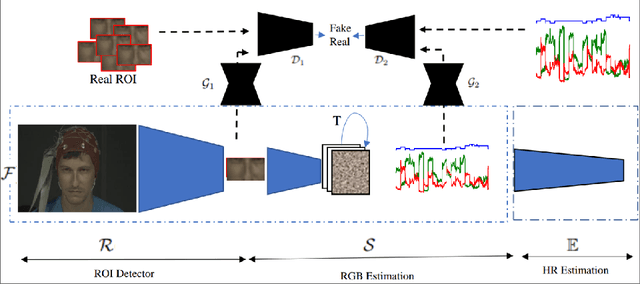
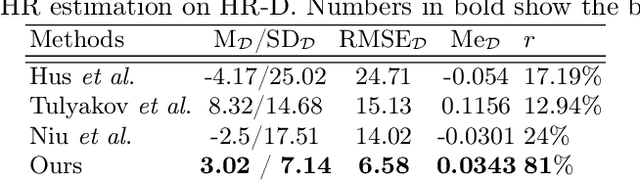
This paper presents a novel method for remote heart rate (HR) estimation. Recent studies have proved that blood pumping by the heart is highly correlated to the intense color of face pixels, and surprisingly can be utilized for remote HR estimation. Researchers successfully proposed several methods for this task, but making it work in realistic situations is still a challenging problem in computer vision community. Furthermore, learning to solve such a complex task on a dataset with very limited annotated samples is not reasonable. Consequently, researchers do not prefer to use the deep learning approaches for this problem. In this paper, we propose a simple yet efficient approach to benefit the advantages of the Deep Neural Network (DNN) by simplifying HR estimation from a complex task to learning from very correlated representation to HR. Inspired by previous work, we learn a component called Front-End (FE) to provide a discriminative representation of face videos, afterward a light deep regression auto-encoder as Back-End (BE) is learned to map the FE representation to HR. Regression task on the informative representation is simple and could be learned efficiently on limited training samples. Beside of this, to be more accurate and work well on low-quality videos, two deep encoder-decoder networks are trained to refine the output of FE. We also introduce a challenging dataset (HR-D) to show that our method can efficiently work in realistic conditions. Experimental results on HR-D and MAHNOB datasets confirm that our method could run as a real-time method and estimate the average HR better than state-of-the-art ones.
AVID: Adversarial Visual Irregularity Detection
Jul 17, 2018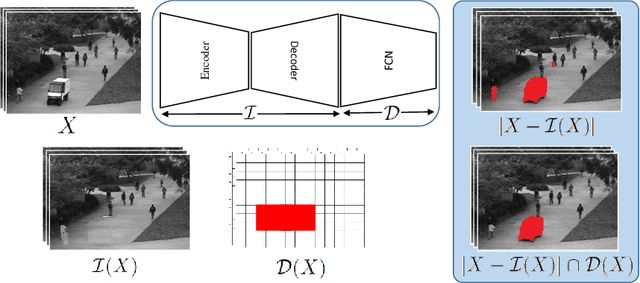
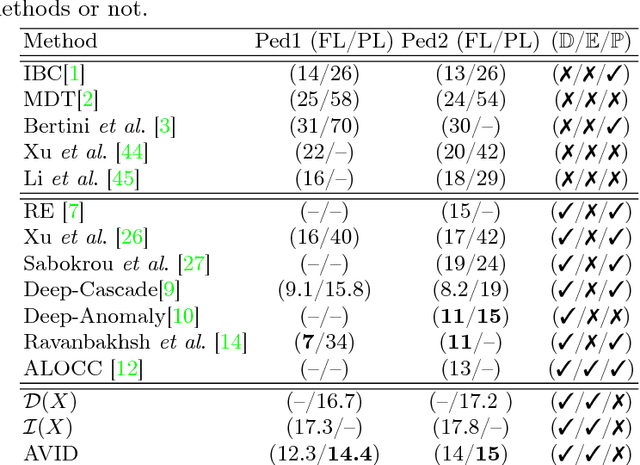

Real-time detection of irregularities in visual data is very invaluable and useful in many prospective applications including surveillance, patient monitoring systems, etc. With the surge of deep learning methods in the recent years, researchers have tried a wide spectrum of methods for different applications. However, for the case of irregularity or anomaly detection in videos, training an end-to-end model is still an open challenge, since often irregularity is not well-defined and there are not enough irregular samples to use during training. In this paper, inspired by the success of generative adversarial networks (GANs) for training deep models in unsupervised or self-supervised settings, we propose an end-to-end deep network for detection and fine localization of irregularities in videos (and images). Our proposed architecture is composed of two networks, which are trained in competing with each other while collaborating to find the irregularity. One network works as a pixel-level irregularity Inpainter, and the other works as a patch-level Detector. After an adversarial self-supervised training, in which I tries to fool D into accepting its inpainted output as regular (normal), the two networks collaborate to detect and fine-segment the irregularity in any given testing video. Our results on three different datasets show that our method can outperform the state-of-the-art and fine-segment the irregularity.