 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoving Object Segmentation in 3D LiDAR Data: A Learning-based Approach Exploiting Sequential Data
May 19, 2021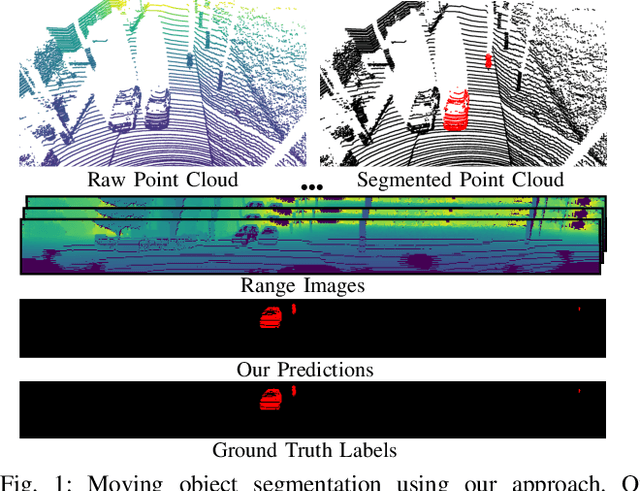
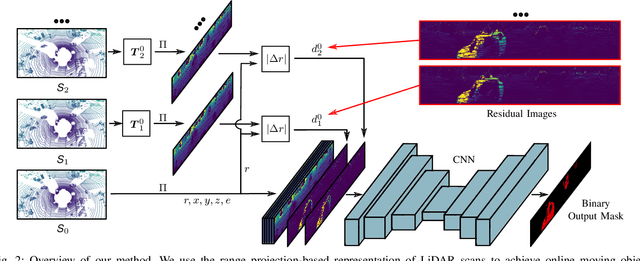

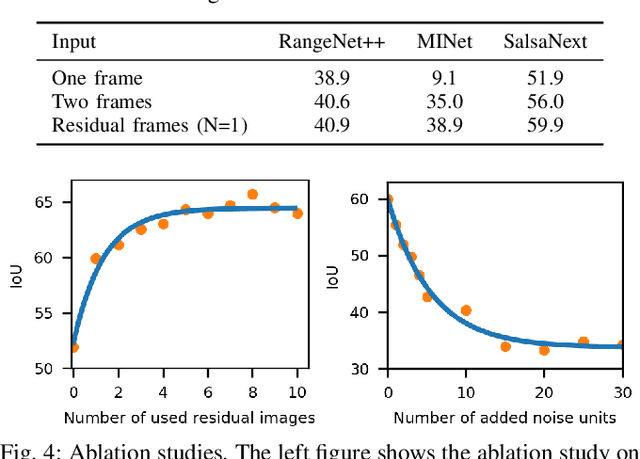
The ability to detect and segment moving objects in a scene is essential for building consistent maps, making future state predictions, avoiding collisions, and planning. In this paper, we address the problem of moving object segmentation from 3D LiDAR scans. We propose a novel approach that pushes the current state of the art in LiDAR-only moving object segmentation forward to provide relevant information for autonomous robots and other vehicles. Instead of segmenting the point cloud semantically, i.e., predicting the semantic classes such as vehicles, pedestrians, buildings, roads, etc., our approach accurately segments the scene into moving and static objects, i.e., distinguishing between moving cars vs. parked cars. Our proposed approach exploits sequential range images from a rotating 3D LiDAR sensor as an intermediate representation combined with a convolutional neural network and runs faster than the frame rate of the sensor. We compare our approach to several other state-of-the-art methods showing superior segmentation quality in urban environments. Additionally, we created a new benchmark for LiDAR-based moving object segmentation based on SemanticKITTI. We publish it to allow other researchers to compare their approaches transparently and we will publish our code.
AVID: Adversarial Visual Irregularity Detection
Jul 17, 2018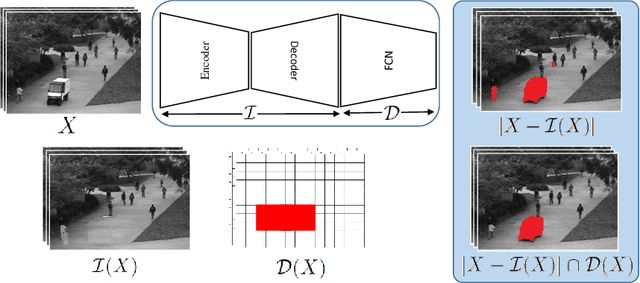
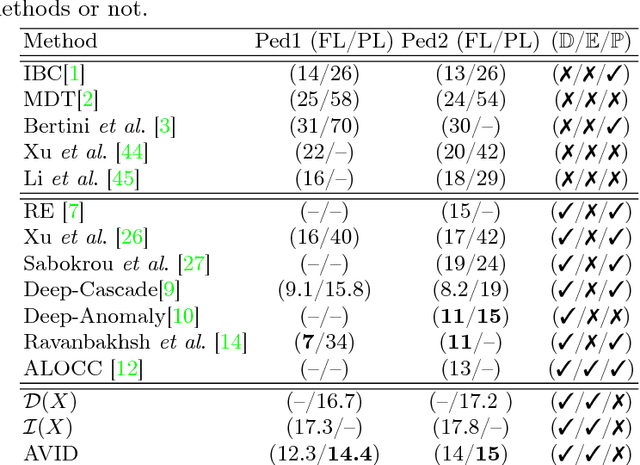
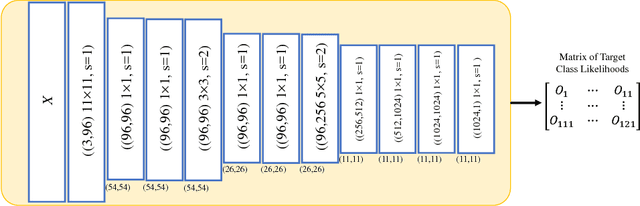

Real-time detection of irregularities in visual data is very invaluable and useful in many prospective applications including surveillance, patient monitoring systems, etc. With the surge of deep learning methods in the recent years, researchers have tried a wide spectrum of methods for different applications. However, for the case of irregularity or anomaly detection in videos, training an end-to-end model is still an open challenge, since often irregularity is not well-defined and there are not enough irregular samples to use during training. In this paper, inspired by the success of generative adversarial networks (GANs) for training deep models in unsupervised or self-supervised settings, we propose an end-to-end deep network for detection and fine localization of irregularities in videos (and images). Our proposed architecture is composed of two networks, which are trained in competing with each other while collaborating to find the irregularity. One network works as a pixel-level irregularity Inpainter, and the other works as a patch-level Detector. After an adversarial self-supervised training, in which I tries to fool D into accepting its inpainted output as regular (normal), the two networks collaborate to detect and fine-segment the irregularity in any given testing video. Our results on three different datasets show that our method can outperform the state-of-the-art and fine-segment the irregularity.