 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Mamba Reliable for Medical Imaging?
Feb 16, 2026State-space models like Mamba offer linear-time sequence processing and low memory, making them attractive for medical imaging. However, their robustness under realistic software and hardware threat models remains underexplored. This paper evaluates Mamba on multiple MedM-NIST classification benchmarks under input-level attacks, including white-box adversarial perturbations (FGSM/PGD), occlusion-based PatchDrop, and common acquisition corruptions (Gaussian noise and defocus blur) as well as hardware-inspired fault attacks emulated in software via targeted and random bit-flip injections into weights and activations. We profile vulnerabilities and quantify impacts on accuracy indicating that defenses are needed for deployment.
Self-Supervised and Topological Signal-Quality Assessment for Any PPG Device
Sep 15, 2025Wearable photoplethysmography (PPG) is embedded in billions of devices, yet its optical waveform is easily corrupted by motion, perfusion loss, and ambient light, jeopardizing downstream cardiometric analytics. Existing signal-quality assessment (SQA) methods rely either on brittle heuristics or on data-hungry supervised models. We introduce the first fully unsupervised SQA pipeline for wrist PPG. Stage 1 trains a contrastive 1-D ResNet-18 on 276 h of raw, unlabeled data from heterogeneous sources (varying in device and sampling frequency), yielding optical-emitter- and motion-invariant embeddings (i.e., the learned representation is stable across differences in LED wavelength, drive intensity, and device optics, as well as wrist motion). Stage 2 converts each 512-D encoder embedding into a 4-D topological signature via persistent homology (PH) and clusters these signatures with HDBSCAN. To produce a binary signal-quality index (SQI), the acceptable PPG signals are represented by the densest cluster while the remaining clusters are assumed to mainly contain poor-quality PPG signals. Without re-tuning, the SQI attains Silhouette, Davies-Bouldin, and Calinski-Harabasz scores of 0.72, 0.34, and 6173, respectively, on a stratified sample of 10,000 windows. In this study, we propose a hybrid self-supervised-learning--topological-data-analysis (SSL--TDA) framework that offers a drop-in, scalable, cross-device quality gate for PPG signals.
Rapid Adaptation of SpO2 Estimation to Wearable Devices via Transfer Learning on Low-Sampling-Rate PPG
Sep 15, 2025Blood oxygen saturation (SpO2) is a vital marker for healthcare monitoring. Traditional SpO2 estimation methods often rely on complex clinical calibration, making them unsuitable for low-power, wearable applications. In this paper, we propose a transfer learning-based framework for the rapid adaptation of SpO2 estimation to energy-efficient wearable devices using low-sampling-rate (25Hz) dual-channel photoplethysmography (PPG). We first pretrain a bidirectional Long Short-Term Memory (BiLSTM) model with self-attention on a public clinical dataset, then fine-tune it using data collected from our wearable We-Be band and an FDA-approved reference pulse oximeter. Experimental results show that our approach achieves a mean absolute error (MAE) of 2.967% on the public dataset and 2.624% on the private dataset, significantly outperforming traditional calibration and non-transferred machine learning baselines. Moreover, using 25Hz PPG reduces power consumption by 40% compared to 100Hz, excluding baseline draw. Our method also attains an MAE of 3.284% in instantaneous SpO2 prediction, effectively capturing rapid fluctuations. These results demonstrate the rapid adaptation of accurate, low-power SpO2 monitoring on wearable devices without the need for clinical calibration.
Generalizable Blood Pressure Estimation from Multi-Wavelength PPG Using Curriculum-Adversarial Learning
Sep 15, 2025Accurate and generalizable blood pressure (BP) estimation is vital for the early detection and management of cardiovascular diseases. In this study, we enforce subject-level data splitting on a public multi-wavelength photoplethysmography (PPG) dataset and propose a generalizable BP estimation framework based on curriculum-adversarial learning. Our approach combines curriculum learning, which transitions from hypertension classification to BP regression, with domain-adversarial training that confuses subject identity to encourage the learning of subject-invariant features. Experiments show that multi-channel fusion consistently outperforms single-channel models. On the four-wavelength PPG dataset, our method achieves strong performance under strict subject-level splitting, with mean absolute errors (MAE) of 14.2mmHg for systolic blood pressure (SBP) and 6.4mmHg for diastolic blood pressure (DBP). Additionally, ablation studies validate the effectiveness of both the curriculum and adversarial components. These results highlight the potential of leveraging complementary information in multi-wavelength PPG and curriculum-adversarial strategies for accurate and robust BP estimation.
Machine Learning Reviews Composition Dependent Thermal Stability in Halide Perovskites
Apr 05, 2025


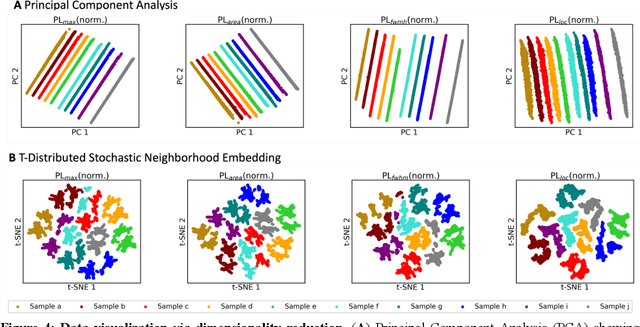
Halide perovskites exhibit unpredictable properties in response to environmental stressors, due to several composition-dependent degradation mechanisms. In this work, we apply data visualization and machine learning (ML) techniques to reveal unexpected correlations between composition, temperature, and material properties while using high throughput, in situ environmental photoluminescence (PL) experiments. Correlation heatmaps show the strong influence of Cs content on film degradation, and dimensionality reduction visualization methods uncover clear composition-based data clusters. An extreme gradient boosting algorithm (XGBoost) effectively forecasts PL features for ten perovskite films with both composition-agnostic (>85% accuracy) and composition-dependent (>75% accuracy) model approaches, while elucidating the relative feature importance of composition (up to 99%). This model validates a previously unseen anti-correlation between Cs content and material thermal stability. Our ML-based framework can be expanded to any perovskite family, significantly reducing the analysis time currently employed to identify stable options for photovoltaics.
FFCL: Forward-Forward Net with Cortical Loops, Training and Inference on Edge Without Backpropagation
May 21, 2024



The Forward-Forward Learning (FFL) algorithm is a recently proposed solution for training neural networks without needing memory-intensive backpropagation. During training, labels accompany input data, classifying them as positive or negative inputs. Each layer learns its response to these inputs independently. In this study, we enhance the FFL with the following contributions: 1) We optimize label processing by segregating label and feature forwarding between layers, enhancing learning performance. 2) By revising label integration, we enhance the inference process, reduce computational complexity, and improve performance. 3) We introduce feedback loops akin to cortical loops in the brain, where information cycles through and returns to earlier neurons, enabling layers to combine complex features from previous layers with lower-level features, enhancing learning efficiency.
Generative AI-Based Effective Malware Detection for Embedded Computing Systems
Apr 12, 2024



One of the pivotal security threats for the embedded computing systems is malicious software a.k.a malware. With efficiency and efficacy, Machine Learning (ML) has been widely adopted for malware detection in recent times. Despite being efficient, the existing techniques require a tremendous number of benign and malware samples for training and modeling an efficient malware detector. Furthermore, such constraints limit the detection of emerging malware samples due to the lack of sufficient malware samples required for efficient training. To address such concerns, we introduce a code-aware data generation technique that generates multiple mutated samples of the limitedly seen malware by the devices. Loss minimization ensures that the generated samples closely mimic the limitedly seen malware and mitigate the impractical samples. Such developed malware is further incorporated into the training set to formulate the model that can efficiently detect the emerging malware despite having limited exposure. The experimental results demonstrates that the proposed technique achieves an accuracy of 90% in detecting limitedly seen malware, which is approximately 3x more than the accuracy attained by state-of-the-art techniques.
HW-V2W-Map: Hardware Vulnerability to Weakness Mapping Framework for Root Cause Analysis with GPT-assisted Mitigation Suggestion
Dec 21, 2023The escalating complexity of modern computing frameworks has resulted in a surge in the cybersecurity vulnerabilities reported to the National Vulnerability Database (NVD) by practitioners. Despite the fact that the stature of NVD is one of the most significant databases for the latest insights into vulnerabilities, extracting meaningful trends from such a large amount of unstructured data is still challenging without the application of suitable technological methodologies. Previous efforts have mostly concentrated on software vulnerabilities; however, a holistic strategy incorporates approaches for mitigating vulnerabilities, score prediction, and a knowledge-generating system that may extract relevant insights from the Common Weakness Enumeration (CWE) and Common Vulnerability Exchange (CVE) databases is notably absent. As the number of hardware attacks on Internet of Things (IoT) devices continues to rapidly increase, we present the Hardware Vulnerability to Weakness Mapping (HW-V2W-Map) Framework, which is a Machine Learning (ML) framework focusing on hardware vulnerabilities and IoT security. The architecture that we have proposed incorporates an Ontology-driven Storytelling framework, which automates the process of updating the ontology in order to recognize patterns and evolution of vulnerabilities over time and provides approaches for mitigating the vulnerabilities. The repercussions of vulnerabilities can be mitigated as a result of this, and conversely, future exposures can be predicted and prevented. Furthermore, our proposed framework utilized Generative Pre-trained Transformer (GPT) Large Language Models (LLMs) to provide mitigation suggestions.
SMOOT: Saliency Guided Mask Optimized Online Training
Oct 10, 2023



Deep Neural Networks are powerful tools for understanding complex patterns and making decisions. However, their black-box nature impedes a complete understanding of their inner workings. Saliency-Guided Training (SGT) methods try to highlight the prominent features in the model's training based on the output to alleviate this problem. These methods use back-propagation and modified gradients to guide the model toward the most relevant features while keeping the impact on the prediction accuracy negligible. SGT makes the model's final result more interpretable by masking input partially. In this way, considering the model's output, we can infer how each segment of the input affects the output. In the particular case of image as the input, masking is applied to the input pixels. However, the masking strategy and number of pixels which we mask, are considered as a hyperparameter. Appropriate setting of masking strategy can directly affect the model's training. In this paper, we focus on this issue and present our contribution. We propose a novel method to determine the optimal number of masked images based on input, accuracy, and model loss during the training. The strategy prevents information loss which leads to better accuracy values. Also, by integrating the model's performance in the strategy formula, we show that our model represents the salient features more meaningful. Our experimental results demonstrate a substantial improvement in both model accuracy and the prominence of saliency, thereby affirming the effectiveness of our proposed solution.
Side Channel-Assisted Inference Leakage from Machine Learning-based ECG Classification
Apr 04, 2023



The Electrocardiogram (ECG) measures the electrical cardiac activity generated by the heart to detect abnormal heartbeat and heart attack. However, the irregular occurrence of the abnormalities demands continuous monitoring of heartbeats. Machine learning techniques are leveraged to automate the task to reduce labor work needed during monitoring. In recent years, many companies have launched products with ECG monitoring and irregular heartbeat alert. Among all classification algorithms, the time series-based algorithm dynamic time warping (DTW) is widely adopted to undertake the ECG classification task. Though progress has been achieved, the DTW-based ECG classification also brings a new attacking vector of leaking the patients' diagnosis results. This paper shows that the ECG input samples' labels can be stolen via a side-channel attack, Flush+Reload. In particular, we first identify the vulnerability of DTW for ECG classification, i.e., the correlation between warping path choice and prediction results. Then we implement an attack that leverages Flush+Reload to monitor the warping path selection with known ECG data and then build a predictor for constructing the relation between warping path selection and labels of input ECG samples. Based on experiments, we find that the Flush+Reload-based inference leakage can achieve an 84.0\% attacking success rate to identify the labels of the two samples in DTW.