 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Augmentation with Summarization Refinement (IASR) Evaluation for Unstructured Survey data Modeling and Analysis
Jul 16, 2025Text data augmentation is a widely used strategy for mitigating data sparsity in natural language processing (NLP), particularly in low-resource settings where limited samples hinder effective semantic modeling. While augmentation can improve input diversity and downstream interpretability, existing techniques often lack mechanisms to ensure semantic preservation during large-scale or iterative generation, leading to redundancy and instability. This work introduces a principled evaluation framework for large language model (LLM) based text augmentation, comprising two components: (1) Scalability Analysis, which measures semantic consistency as augmentation volume increases, and (2) Iterative Augmentation with Summarization Refinement (IASR), which evaluates semantic drift across recursive paraphrasing cycles. Empirical evaluations across state-of-the-art LLMs show that GPT-3.5 Turbo achieved the best balance of semantic fidelity, diversity, and generation efficiency. Applied to a real-world topic modeling task using BERTopic with GPT-enhanced few-shot labeling, the proposed approach results in a 400% increase in topic granularity and complete elimination of topic overlaps. These findings validated the utility of the proposed frameworks for structured evaluation of LLM-based augmentation in practical NLP pipelines.
Generative AI-Based Effective Malware Detection for Embedded Computing Systems
Apr 12, 2024



One of the pivotal security threats for the embedded computing systems is malicious software a.k.a malware. With efficiency and efficacy, Machine Learning (ML) has been widely adopted for malware detection in recent times. Despite being efficient, the existing techniques require a tremendous number of benign and malware samples for training and modeling an efficient malware detector. Furthermore, such constraints limit the detection of emerging malware samples due to the lack of sufficient malware samples required for efficient training. To address such concerns, we introduce a code-aware data generation technique that generates multiple mutated samples of the limitedly seen malware by the devices. Loss minimization ensures that the generated samples closely mimic the limitedly seen malware and mitigate the impractical samples. Such developed malware is further incorporated into the training set to formulate the model that can efficiently detect the emerging malware despite having limited exposure. The experimental results demonstrates that the proposed technique achieves an accuracy of 90% in detecting limitedly seen malware, which is approximately 3x more than the accuracy attained by state-of-the-art techniques.
A Neural Network-based SAT-Resilient Obfuscation Towards Enhanced Logic Locking
Sep 13, 2022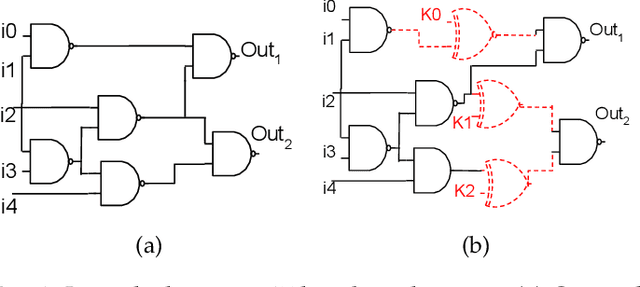
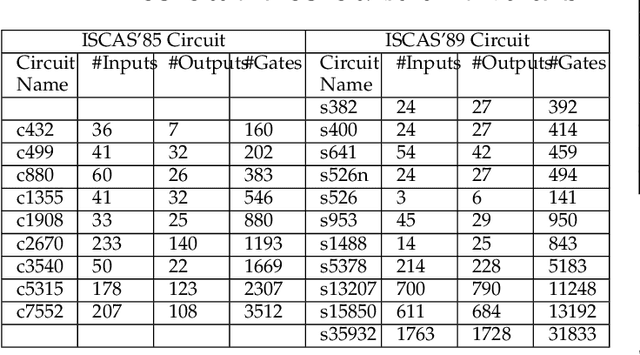
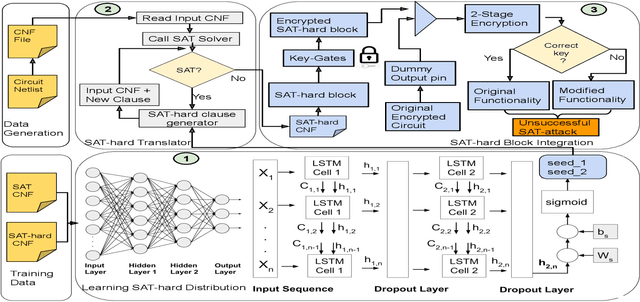
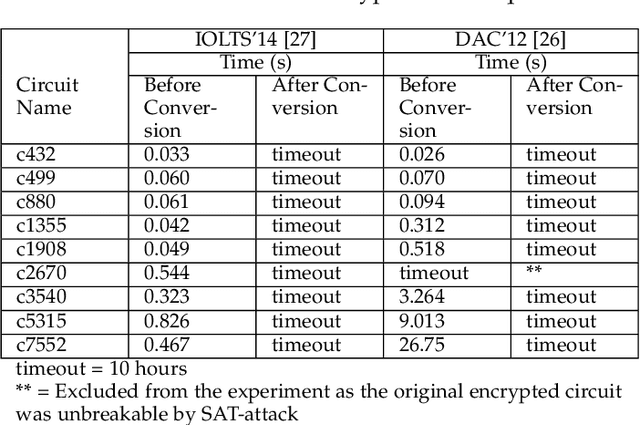
Logic obfuscation is introduced as a pivotal defense against multiple hardware threats on Integrated Circuits (ICs), including reverse engineering (RE) and intellectual property (IP) theft. The effectiveness of logic obfuscation is challenged by the recently introduced Boolean satisfiability (SAT) attack and its variants. A plethora of countermeasures has also been proposed to thwart the SAT attack. Irrespective of the implemented defense against SAT attacks, large power, performance, and area overheads are indispensable. In contrast, we propose a cognitive solution: a neural network-based unSAT clause translator, SATConda, that incurs a minimal area and power overhead while preserving the original functionality with impenetrable security. SATConda is incubated with an unSAT clause generator that translates the existing conjunctive normal form (CNF) through minimal perturbations such as the inclusion of pair of inverters or buffers or adding a new lightweight unSAT block depending on the provided CNF. For efficient unSAT clause generation, SATConda is equipped with a multi-layer neural network that first learns the dependencies of features (literals and clauses), followed by a long-short-term-memory (LSTM) network to validate and backpropagate the SAT-hardness for better learning and translation. Our proposed SATConda is evaluated on ISCAS85 and ISCAS89 benchmarks and is seen to defend against multiple state-of-the-art successfully SAT attacks devised for hardware RE. In addition, we also evaluate our proposed SATCondas empirical performance against MiniSAT, Lingeling and Glucose SAT solvers that form the base for numerous existing deobfuscation SAT attacks.
Deep Multi-attributed Graph Translation with Node-Edge Co-evolution
Mar 22, 2020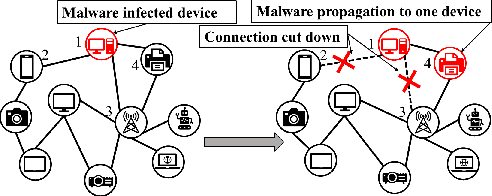
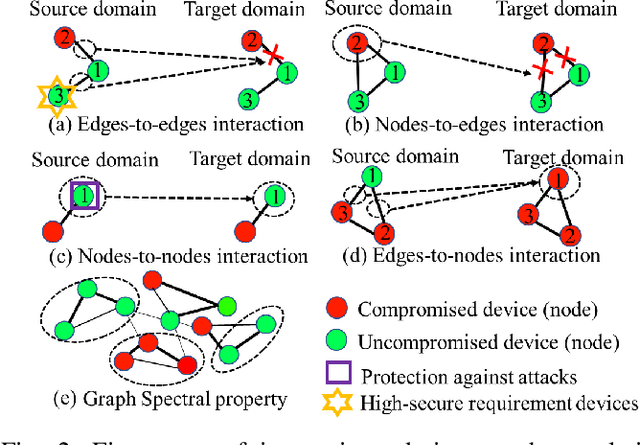
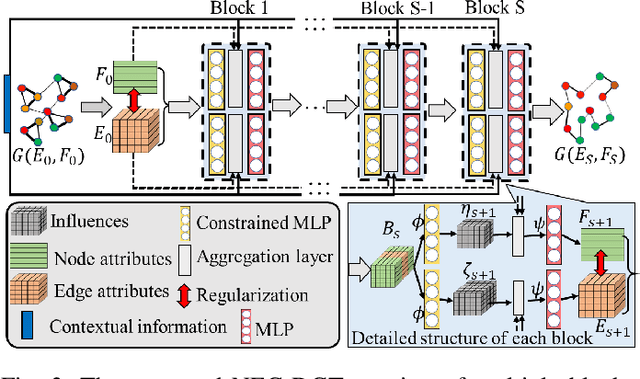
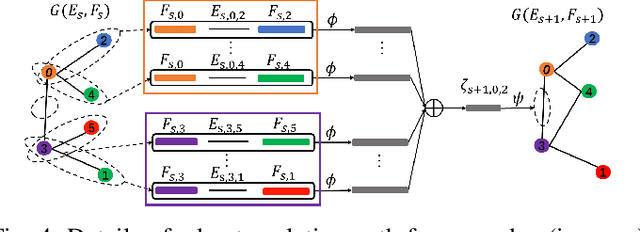
Generalized from image and language translation, graph translation aims to generate a graph in the target domain by conditioning an input graph in the source domain. This promising topic has attracted fast-increasing attention recently. Existing works are limited to either merely predicting the node attributes of graphs with fixed topology or predicting only the graph topology without considering node attributes, but cannot simultaneously predict both of them, due to substantial challenges: 1) difficulty in characterizing the interactive, iterative, and asynchronous translation process of both nodes and edges and 2) difficulty in discovering and maintaining the inherent consistency between the node and edge in predicted graphs. These challenges prevent a generic, end-to-end framework for joint node and edge attributes prediction, which is a need for real-world applications such as malware confinement in IoT networks and structural-to-functional network translation. These real-world applications highly depend on hand-crafting and ad-hoc heuristic models, but cannot sufficiently utilize massive historical data. In this paper, we termed this generic problem "multi-attributed graph translation" and developed a novel framework integrating both node and edge translations seamlessly. The novel edge translation path is generic, which is proven to be a generalization of the existing topology translation models. Then, a spectral graph regularization based on our non-parametric graph Laplacian is proposed in order to learn and maintain the consistency of the predicted nodes and edges. Finally, extensive experiments on both synthetic and real-world application data demonstrated the effectiveness of the proposed method.
* This paper has been accepted by International Conference on Data Mining (ICDM), Beijing, China, 2019
Pyramid: Machine Learning Framework to Estimate the Optimal Timing and Resource Usage of a High-Level Synthesis Design
Jul 29, 2019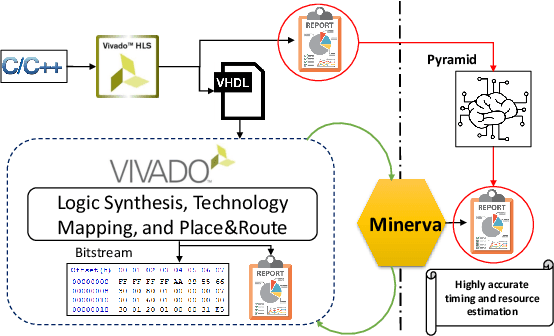
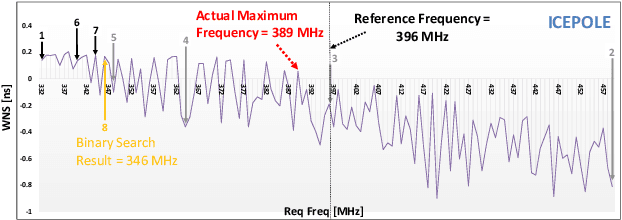

The emergence of High-Level Synthesis (HLS) tools shifted the paradigm of hardware design by making the process of mapping high-level programming languages to hardware design such as C to VHDL/Verilog feasible. HLS tools offer a plethora of techniques to optimize designs for both area and performance, but resource usage and timing reports of HLS tools mostly deviate from the post-implementation results. In addition, to evaluate a hardware design performance, it is critical to determine the maximum achievable clock frequency. Obtaining such information using static timing analysis provided by CAD tools is difficult, due to the multitude of tool options. Moreover, a binary search to find the maximum frequency is tedious, time-consuming, and often does not obtain the optimal result. To address these challenges, we propose a framework, called Pyramid, that uses machine learning to accurately estimate the optimal performance and resource utilization of an HLS design. For this purpose, we first create a database of C-to-FPGA results from a diverse set of benchmarks. To find the achievable maximum clock frequency, we use Minerva, which is an automated hardware optimization tool. Minerva determines the close-to-optimal settings of tools, using static timing analysis and a heuristic algorithm, and targets either optimal throughput or throughput-to-area. Pyramid uses the database to train an ensemble machine learning model to map the HLS-reported features to the results of Minerva. To this end, Pyramid re-calibrates the results of HLS to bridge the accuracy gap and enable developers to estimate the throughput or throughput-to-area of hardware design with more than 95% accuracy and alleviates the need to perform actual implementation for estimation.