 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTailored-LLaMA: Optimizing Few-Shot Learning in Pruned LLaMA Models with Task-Specific Prompts
Oct 24, 2024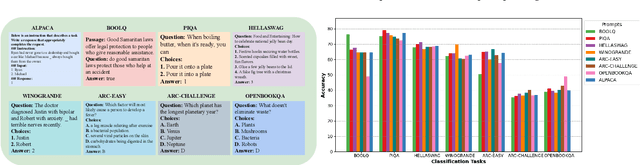



Large language models demonstrate impressive proficiency in language understanding and generation. Nonetheless, training these models from scratch, even the least complex billion-parameter variant demands significant computational resources rendering it economically impractical for many organizations. With large language models functioning as general-purpose task solvers, this paper investigates their task-specific fine-tuning. We employ task-specific datasets and prompts to fine-tune two pruned LLaMA models having 5 billion and 4 billion parameters. This process utilizes the pre-trained weights and focuses on a subset of weights using the LoRA method. One challenge in fine-tuning the LLaMA model is crafting a precise prompt tailored to the specific task. To address this, we propose a novel approach to fine-tune the LLaMA model under two primary constraints: task specificity and prompt effectiveness. Our approach, Tailored LLaMA initially employs structural pruning to reduce the model sizes from 7B to 5B and 4B parameters. Subsequently, it applies a carefully designed prompt specific to the task and utilizes the LoRA method to accelerate the fine-tuning process. Moreover, fine-tuning a model pruned by 50\% for less than one hour restores the mean accuracy of classification tasks to 95.68\% at a 20\% compression ratio and to 86.54\% at a 50\% compression ratio through few-shot learning with 50 shots. Our validation of Tailored LLaMA on these two pruned variants demonstrates that even when compressed to 50\%, the models maintain over 65\% of the baseline model accuracy in few-shot classification and generation tasks. These findings highlight the efficacy of our tailored approach in maintaining high performance with significantly reduced model sizes.
Brain Tumor Synthetic Data Generation with Adaptive StyleGANs
Dec 04, 2022Generative models have been very successful over the years and have received significant attention for synthetic data generation. As deep learning models are getting more and more complex, they require large amounts of data to perform accurately. In medical image analysis, such generative models play a crucial role as the available data is limited due to challenges related to data privacy, lack of data diversity, or uneven data distributions. In this paper, we present a method to generate brain tumor MRI images using generative adversarial networks. We have utilized StyleGAN2 with ADA methodology to generate high-quality brain MRI with tumors while using a significantly smaller amount of training data when compared to the existing approaches. We use three pre-trained models for transfer learning. Results demonstrate that the proposed method can learn the distributions of brain tumors. Furthermore, the model can generate high-quality synthetic brain MRI with a tumor that can limit the small sample size issues. The approach can addresses the limited data availability by generating realistic-looking brain MRI with tumors. The code is available at: ~\url{https://github.com/rizwanqureshi123/Brain-Tumor-Synthetic-Data}.