 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Dense, Not Long: Dynamic Decoupled Conditional Advantage for Efficient Reasoning
Feb 02, 2026Reinforcement Learning with Verifiable Rewards (RLVR) can elicit strong multi-step reasoning, yet it often encourages overly verbose traces. Moreover, naive length penalties in group-relative optimization can severely hurt accuracy. We attribute this failure to two structural issues: (i) Dilution of Length Baseline, where incorrect responses (with zero length reward) depress the group baseline and over-penalize correct solutions; and (ii) Difficulty-Penalty Mismatch, where a static penalty cannot adapt to problem difficulty, suppressing necessary reasoning on hard instances while leaving redundancy on easy ones. We propose Dynamic Decoupled Conditional Advantage (DDCA) to decouple efficiency optimization from correctness. DDCA computes length advantages conditionally within the correct-response cluster to eliminate baseline dilution, and dynamically scales the penalty strength using the group pass rate as a proxy for difficulty. Experiments on GSM8K, MATH500, AMC23, and AIME25 show that DDCA consistently improves the efficiency--accuracy trade-off relative to adaptive baselines, reducing generated tokens by approximately 60% on simpler tasks (e.g., GSM8K) versus over 20% on harder benchmarks (e.g., AIME25), thereby maintaining or improving accuracy. Code is available at https://github.com/alphadl/DDCA.
Revisiting Overthinking in Long Chain-of-Thought from the Perspective of Self-Doubt
May 29, 2025


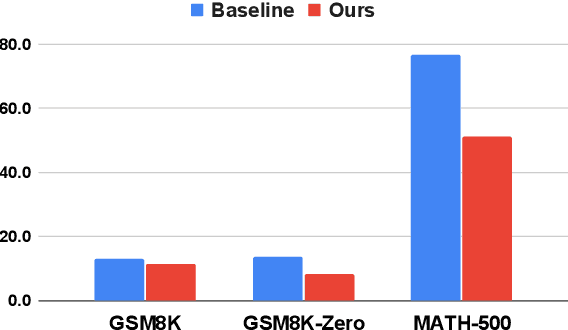
Reasoning Large Language Models (RLLMs) have demonstrated impressive performance on complex tasks, largely due to the adoption of Long Chain-of-Thought (Long CoT) reasoning. However, they often exhibit overthinking -- performing unnecessary reasoning steps even after arriving at the correct answer. Prior work has largely focused on qualitative analyses of overthinking through sample-based observations of long CoTs. In contrast, we present a quantitative analysis of overthinking from the perspective of self-doubt, characterized by excessive token usage devoted to re-verifying already-correct answer. We find that self-doubt significantly contributes to overthinking. In response, we introduce a simple and effective prompting method to reduce the model's over-reliance on input questions, thereby avoiding self-doubt. Specifically, we first prompt the model to question the validity of the input question, and then respond concisely based on the outcome of that evaluation. Experiments on three mathematical reasoning tasks and four datasets with missing premises demonstrate that our method substantially reduces answer length and yields significant improvements across nearly all datasets upon 4 widely-used RLLMs. Further analysis demonstrates that our method effectively minimizes the number of reasoning steps and reduces self-doubt.
Enhancing Input-Label Mapping in In-Context Learning with Contrastive Decoding
Feb 19, 2025



Large language models (LLMs) excel at a range of tasks through in-context learning (ICL), where only a few task examples guide their predictions. However, prior research highlights that LLMs often overlook input-label mapping information in ICL, relying more on their pre-trained knowledge. To address this issue, we introduce In-Context Contrastive Decoding (ICCD), a novel method that emphasizes input-label mapping by contrasting the output distributions between positive and negative in-context examples. Experiments on 7 natural language understanding (NLU) tasks show that our ICCD method brings consistent and significant improvement (up to +2.1 improvement on average) upon 6 different scales of LLMs without requiring additional training. Our approach is versatile, enhancing performance with various demonstration selection methods, demonstrating its broad applicability and effectiveness. The code and scripts will be publicly released.
Take Care of Your Prompt Bias! Investigating and Mitigating Prompt Bias in Factual Knowledge Extraction
Mar 26, 2024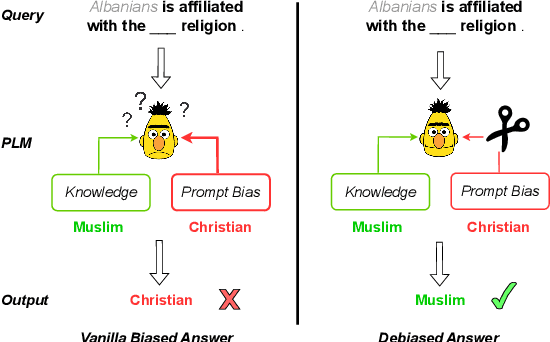
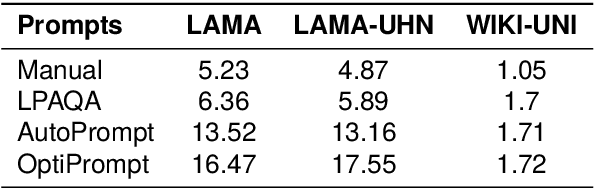
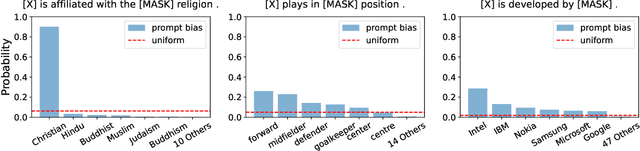
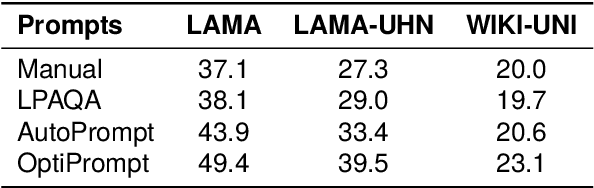
Recent research shows that pre-trained language models (PLMs) suffer from "prompt bias" in factual knowledge extraction, i.e., prompts tend to introduce biases toward specific labels. Prompt bias presents a significant challenge in assessing the factual knowledge within PLMs. Therefore, this paper aims to improve the reliability of existing benchmarks by thoroughly investigating and mitigating prompt bias. We show that: 1) all prompts in the experiments exhibit non-negligible bias, with gradient-based prompts like AutoPrompt and OptiPrompt displaying significantly higher levels of bias; 2) prompt bias can amplify benchmark accuracy unreasonably by overfitting the test datasets, especially on imbalanced datasets like LAMA. Based on these findings, we propose a representation-based approach to mitigate the prompt bias during inference time. Specifically, we first estimate the biased representation using prompt-only querying, and then remove it from the model's internal representations to generate the debiased representations, which are used to produce the final debiased outputs. Experiments across various prompts, PLMs, and benchmarks show that our approach can not only correct the overfitted performance caused by prompt bias, but also significantly improve the prompt retrieval capability (up to 10% absolute performance gain). These results indicate that our approach effectively alleviates prompt bias in knowledge evaluation, thereby enhancing the reliability of benchmark assessments. Hopefully, our plug-and-play approach can be a golden standard to strengthen PLMs toward reliable knowledge bases. Code and data are released in https://github.com/FelliYang/PromptBias.
Revisiting Demonstration Selection Strategies in In-Context Learning
Jan 22, 2024



Large language models (LLMs) have shown an impressive ability to perform a wide range of tasks using in-context learning (ICL), where a few examples are used to describe a task to the model. However, the performance of ICL varies significantly with the choice of demonstrations, and it is still unclear why this happens or what factors will influence its choice. In this work, we first revisit the factors contributing to this variance from both data and model aspects, and find that the choice of demonstration is both data- and model-dependent. We further proposed a data- and model-dependent demonstration selection method, \textbf{TopK + ConE}, based on the assumption that \textit{the performance of a demonstration positively correlates with its contribution to the model's understanding of the test samples}, resulting in a simple and effective recipe for ICL. Empirically, our method yields consistent improvements in both language understanding and generation tasks with different model scales. Further analyses confirm that, besides the generality and stability under different circumstances, our method provides a unified explanation for the effectiveness of previous methods. Code will be released.
Diversifying the Mixture-of-Experts Representation for Language Models with Orthogonal Optimizer
Oct 15, 2023The Mixture of Experts (MoE) has emerged as a highly successful technique in deep learning, based on the principle of divide-and-conquer to maximize model capacity without significant additional computational cost. Even in the era of large-scale language models (LLMs), MoE continues to play a crucial role, as some researchers have indicated that GPT-4 adopts the MoE structure to ensure diverse inference results. However, MoE is susceptible to performance degeneracy, particularly evident in the issues of imbalance and homogeneous representation among experts. While previous studies have extensively addressed the problem of imbalance, the challenge of homogeneous representation remains unresolved. In this study, we shed light on the homogeneous representation problem, wherein experts in the MoE fail to specialize and lack diversity, leading to frustratingly high similarities in their representations (up to 99% in a well-performed MoE model). This problem restricts the expressive power of the MoE and, we argue, contradicts its original intention. To tackle this issue, we propose a straightforward yet highly effective solution: OMoE, an orthogonal expert optimizer. Additionally, we introduce an alternating training strategy that encourages each expert to update in a direction orthogonal to the subspace spanned by other experts. Our algorithm facilitates MoE training in two key ways: firstly, it explicitly enhances representation diversity, and secondly, it implicitly fosters interaction between experts during orthogonal weights computation. Through extensive experiments, we demonstrate that our proposed optimization algorithm significantly improves the performance of fine-tuning the MoE model on the GLUE benchmark, SuperGLUE benchmark, question-answering task, and name entity recognition tasks.
Towards Making the Most of ChatGPT for Machine Translation
Mar 24, 2023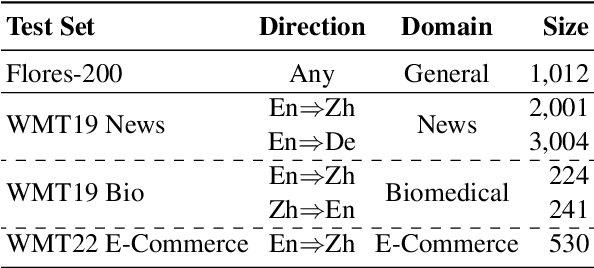
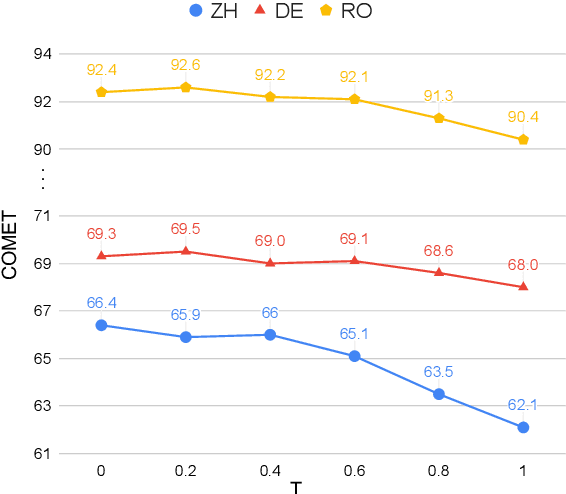

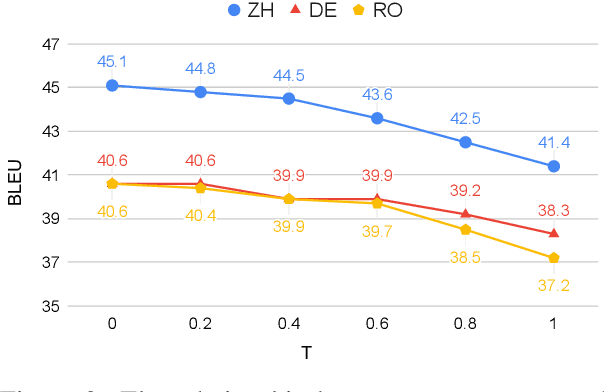
ChatGPT shows remarkable capabilities for machine translation (MT). Several prior studies have shown that it achieves comparable results to commercial systems for high-resource languages, but lags behind in complex tasks, e.g, low-resource and distant-language-pairs translation. However, they usually adopt simple prompts which can not fully elicit the capability of ChatGPT. In this report, we aim to further mine ChatGPT's translation ability by revisiting several aspects: temperature, task information, and domain information, and correspondingly propose two (simple but effective) prompts: Task-Specific Prompts (TSP) and Domain-Specific Prompts (DSP). We show that: 1) The performance of ChatGPT depends largely on temperature, and a lower temperature usually can achieve better performance; 2) Emphasizing the task information further improves ChatGPT's performance, particularly in complex MT tasks; 3) Introducing domain information can elicit ChatGPT's generalization ability and improve its performance in the specific domain; 4) ChatGPT tends to generate hallucinations for non-English-centric MT tasks, which can be partially addressed by our proposed prompts but still need to be highlighted for the MT/NLP community. We also explore the effects of advanced in-context learning strategies and find a (negative but interesting) observation: the powerful chain-of-thought prompt leads to word-by-word translation behavior, thus bringing significant translation degradation.
Bag of Tricks for Effective Language Model Pretraining and Downstream Adaptation: A Case Study on GLUE
Feb 18, 2023



This technical report briefly describes our JDExplore d-team's submission Vega v1 on the General Language Understanding Evaluation (GLUE) leaderboard, where GLUE is a collection of nine natural language understanding tasks, including question answering, linguistic acceptability, sentiment analysis, text similarity, paraphrase detection, and natural language inference. [Method] We investigate several effective strategies and choose their best combination setting as the training recipes. As for model structure, we employ the vanilla Transformer with disentangled attention as the basic block encoder. For self-supervised training, we employ the representative denoising objective (i.e., replaced token detection) in phase 1 and combine the contrastive objective (i.e., sentence embedding contrastive learning) with it in phase 2. During fine-tuning, several advanced techniques such as transductive fine-tuning, self-calibrated fine-tuning, and adversarial fine-tuning are adopted. [Results] According to our submission record (Jan. 2022), with our optimized pretraining and fine-tuning strategies, our 1.3 billion model sets new state-of-the-art on 4/9 tasks, achieving the best average score of 91.3. Encouragingly, our Vega v1 is the first to exceed powerful human performance on the two challenging tasks, i.e., SST-2 and WNLI. We believe our empirically successful recipe with a bag of tricks could shed new light on developing efficient discriminative large language models.
Vega-MT: The JD Explore Academy Translation System for WMT22
Sep 21, 2022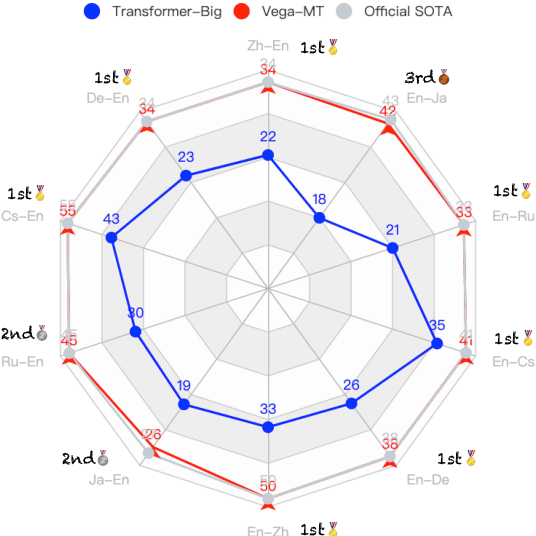
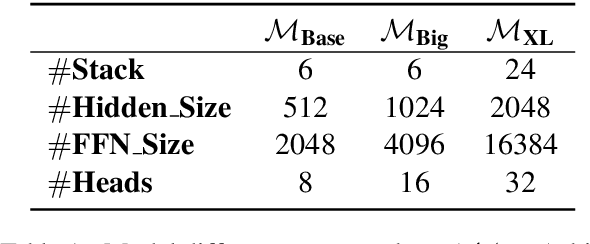
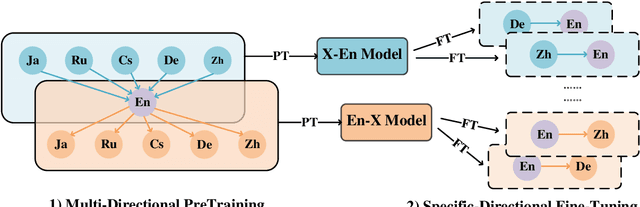

We describe the JD Explore Academy's submission of the WMT 2022 shared general translation task. We participated in all high-resource tracks and one medium-resource track, including Chinese-English, German-English, Czech-English, Russian-English, and Japanese-English. We push the limit of our previous work -- bidirectional training for translation by scaling up two main factors, i.e. language pairs and model sizes, namely the \textbf{Vega-MT} system. As for language pairs, we scale the "bidirectional" up to the "multidirectional" settings, covering all participating languages, to exploit the common knowledge across languages, and transfer them to the downstream bilingual tasks. As for model sizes, we scale the Transformer-Big up to the extremely large model that owns nearly 4.7 Billion parameters, to fully enhance the model capacity for our Vega-MT. Also, we adopt the data augmentation strategies, e.g. cycle translation for monolingual data, and bidirectional self-training for bilingual and monolingual data, to comprehensively exploit the bilingual and monolingual data. To adapt our Vega-MT to the general domain test set, generalization tuning is designed. Based on the official automatic scores of constrained systems, in terms of the sacreBLEU shown in Figure-1, we got the 1st place on {Zh-En (33.5), En-Zh (49.7), De-En (33.7), En-De (37.8), Cs-En (54.9), En-Cs (41.4) and En-Ru (32.7)}, 2nd place on {Ru-En (45.1) and Ja-En (25.6)}, and 3rd place on {En-Ja(41.5)}, respectively; W.R.T the COMET, we got the 1st place on {Zh-En (45.1), En-Zh (61.7), De-En (58.0), En-De (63.2), Cs-En (74.7), Ru-En (64.9), En-Ru (69.6) and En-Ja (65.1)}, 2nd place on {En-Cs (95.3) and Ja-En (40.6)}, respectively. Models will be released to facilitate the MT community through GitHub and OmniForce Platform.
Improving Neural Machine Translation by Denoising Training
Jan 20, 2022
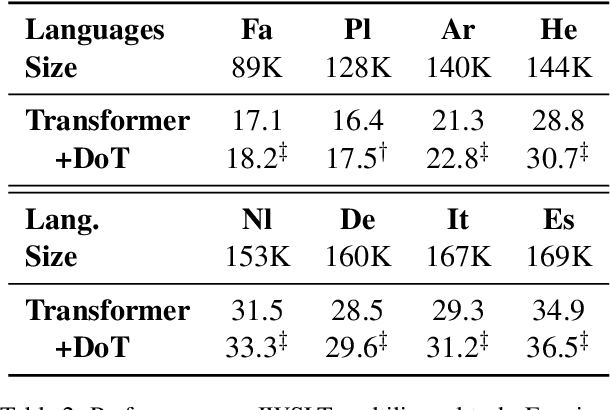


We present a simple and effective pretraining strategy {D}en{o}ising {T}raining DoT for neural machine translation. Specifically, we update the model parameters with source- and target-side denoising tasks at the early stage and then tune the model normally. Notably, our approach does not increase any parameters or training steps, requiring the parallel data merely. Experiments show that DoT consistently improves the neural machine translation performance across 12 bilingual and 16 multilingual directions (data size ranges from 80K to 20M). In addition, we show that DoT can complement existing data manipulation strategies, i.e. curriculum learning, knowledge distillation, data diversification, bidirectional training, and back-translation. Encouragingly, we found that DoT outperforms costly pretrained model mBART in high-resource settings. Analyses show DoT is a novel in-domain cross-lingual pretraining strategy and could offer further improvements with task-relevant self-supervisions.