 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Neural Machine Translation by Denoising Training
Paper and Code

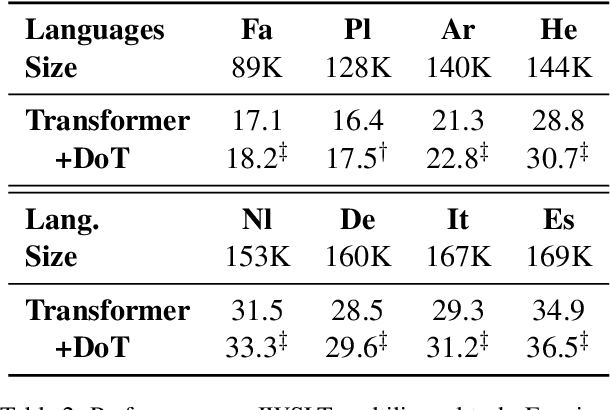


We present a simple and effective pretraining strategy {D}en{o}ising {T}raining DoT for neural machine translation. Specifically, we update the model parameters with source- and target-side denoising tasks at the early stage and then tune the model normally. Notably, our approach does not increase any parameters or training steps, requiring the parallel data merely. Experiments show that DoT consistently improves the neural machine translation performance across 12 bilingual and 16 multilingual directions (data size ranges from 80K to 20M). In addition, we show that DoT can complement existing data manipulation strategies, i.e. curriculum learning, knowledge distillation, data diversification, bidirectional training, and back-translation. Encouragingly, we found that DoT outperforms costly pretrained model mBART in high-resource settings. Analyses show DoT is a novel in-domain cross-lingual pretraining strategy and could offer further improvements with task-relevant self-supervisions.