 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlikelihood Tuning on Negative Samples Amazingly Improves Zero-Shot Translation
Paper and Code
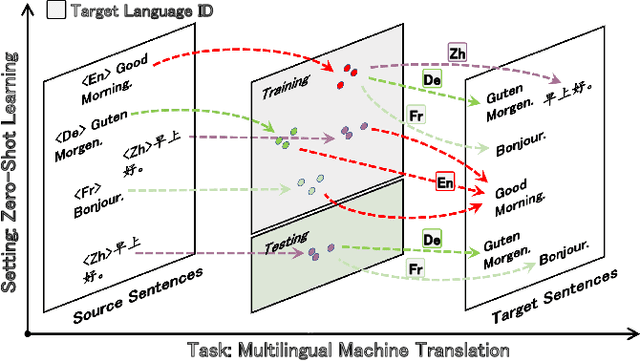
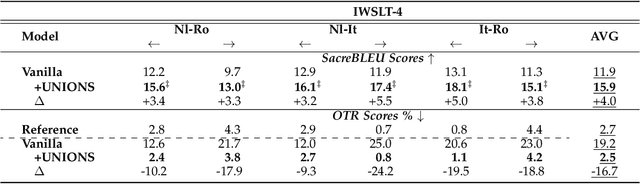
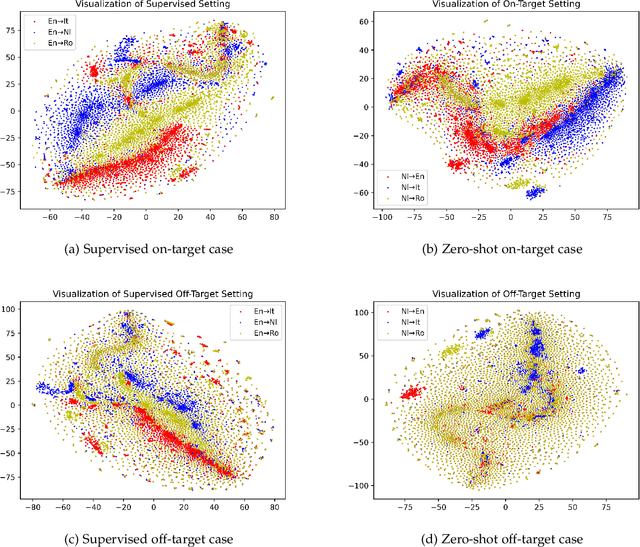
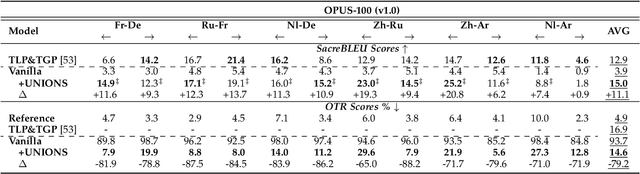
Zero-shot translation (ZST), which is generally based on a multilingual neural machine translation model, aims to translate between unseen language pairs in training data. The common practice to guide the zero-shot language mapping during inference is to deliberately insert the source and target language IDs, e.g., <EN> for English and <DE> for German. Recent studies have shown that language IDs sometimes fail to navigate the ZST task, making them suffer from the off-target problem (non-target language words exist in the generated translation) and, therefore, difficult to apply the current multilingual translation model to a broad range of zero-shot language scenarios. To understand when and why the navigation capabilities of language IDs are weakened, we compare two extreme decoder input cases in the ZST directions: Off-Target (OFF) and On-Target (ON) cases. By contrastively visualizing the contextual word representations (CWRs) of these cases with teacher forcing, we show that 1) the CWRs of different languages are effectively distributed in separate regions when the sentence and ID are matched (ON setting), and 2) if the sentence and ID are unmatched (OFF setting), the CWRs of different languages are chaotically distributed. Our analyses suggest that although they work well in ideal ON settings, language IDs become fragile and lose their navigation ability when faced with off-target tokens, which commonly exist during inference but are rare in training scenarios. In response, we employ unlikelihood tuning on the negative (OFF) samples to minimize their probability such that the language IDs can discriminate between the on- and off-target tokens during training. Experiments spanning 40 ZST directions show that our method reduces the off-target ratio by -48.0% on average, leading to a +9.1 BLEU improvement with only an extra +0.3% tuning cost.