 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Large Language Models Efficient Dense Retrievers
Dec 23, 2025Recent work has shown that directly fine-tuning large language models (LLMs) for dense retrieval yields strong performance, but their substantial parameter counts make them computationally inefficient. While prior studies have revealed significant layer redundancy in LLMs for generative tasks, it remains unclear whether similar redundancy exists when these models are adapted for retrieval tasks, which require encoding entire sequences into fixed representations rather than generating tokens iteratively. To this end, we conduct a comprehensive analysis of layer redundancy in LLM-based dense retrievers. We find that, in contrast to generative settings, MLP layers are substantially more prunable, while attention layers remain critical for semantic aggregation. Building on this insight, we propose EffiR, a framework for developing efficient retrievers that performs large-scale MLP compression through a coarse-to-fine strategy (coarse-grained depth reduction followed by fine-grained width reduction), combined with retrieval-specific fine-tuning. Across diverse BEIR datasets and LLM backbones, EffiR achieves substantial reductions in model size and inference cost while preserving the performance of full-size models.
Milco: Learned Sparse Retrieval Across Languages via a Multilingual Connector
Oct 01, 2025Learned Sparse Retrieval (LSR) combines the efficiency of bi-encoders with the transparency of lexical matching, but existing approaches struggle to scale beyond English. We introduce MILCO, an LSR architecture that maps queries and documents from different languages into a shared English lexical space via a multilingual connector. MILCO is trained with a specialized two-stage regime that combines Sparse Alignment Pretraining with contrastive training to provide representation transparency and effectiveness while mitigating semantic collapse. Motivated by the observation that uncommon entities are often lost when projected into English, we propose a new LexEcho head, which enhances robustness by augmenting the English lexical representation with a source-language view obtained through a special [ECHO] token. MILCO achieves state-of-the-art multilingual and cross-lingual LSR performance, outperforming leading dense, sparse, and multi-vector baselines such as BGE-M3 and Qwen3-Embed on standard multilingual benchmarks, while supporting dynamic efficiency through post-hoc pruning. Notably, when using mass-based pruning to reduce document representations to only 30 active dimensions on average, MILCO 560M outperforms the similarly-sized Qwen3-Embed 0.6B with 1024 dimensions.
SERVAL: Surprisingly Effective Zero-Shot Visual Document Retrieval Powered by Large Vision and Language Models
Sep 18, 2025Visual Document Retrieval (VDR) typically operates as text-to-image retrieval using specialized bi-encoders trained to directly embed document images. We revisit a zero-shot generate-and-encode pipeline: a vision-language model first produces a detailed textual description of each document image, which is then embedded by a standard text encoder. On the ViDoRe-v2 benchmark, the method reaches 63.4% nDCG@5, surpassing the strongest specialised multi-vector visual document encoder. It also scales better to large collections and offers broader multilingual coverage. Analysis shows that modern vision-language models capture complex textual and visual cues with sufficient granularity to act as a reusable semantic proxy. By offloading modality alignment to pretrained vision-language models, our approach removes the need for computationally intensive text-image contrastive training and establishes a strong zero-shot baseline for future VDR systems.
* Accepted
ThinkQE: Query Expansion via an Evolving Thinking Process
Jun 10, 2025Effective query expansion for web search benefits from promoting both exploration and result diversity to capture multiple interpretations and facets of a query. While recent LLM-based methods have improved retrieval performance and demonstrate strong domain generalization without additional training, they often generate narrowly focused expansions that overlook these desiderata. We propose ThinkQE, a test-time query expansion framework addressing this limitation through two key components: a thinking-based expansion process that encourages deeper and comprehensive semantic exploration, and a corpus-interaction strategy that iteratively refines expansions using retrieval feedback from the corpus. Experiments on diverse web search benchmarks (DL19, DL20, and BRIGHT) show ThinkQE consistently outperforms prior approaches, including training-intensive dense retrievers and rerankers.
What Does Neuro Mean to Cardio? Investigating the Role of Clinical Specialty Data in Medical LLMs
May 15, 2025In this paper, we introduce S-MedQA, an English medical question-answering (QA) dataset for benchmarking large language models in fine-grained clinical specialties. We use S-MedQA to check the applicability of a popular hypothesis related to knowledge injection in the knowledge-intense scenario of medical QA, and show that: 1) training on data from a speciality does not necessarily lead to best performance on that specialty and 2) regardless of the specialty fine-tuned on, token probabilities of clinically relevant terms for all specialties increase consistently. Thus, we believe improvement gains come mostly from domain shifting (e.g., general to medical) rather than knowledge injection and suggest rethinking the role of fine-tuning data in the medical domain. We release S-MedQA and all code needed to reproduce all our experiments to the research community.
Calibrating Translation Decoding with Quality Estimation on LLMs
Apr 26, 2025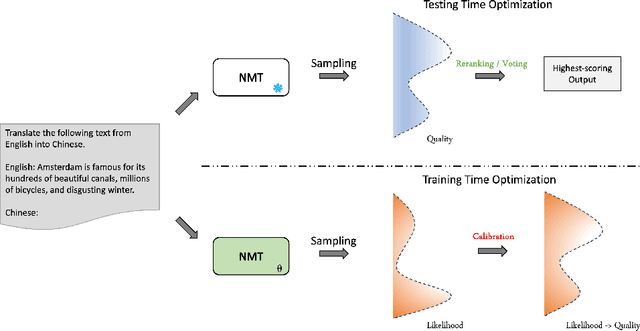
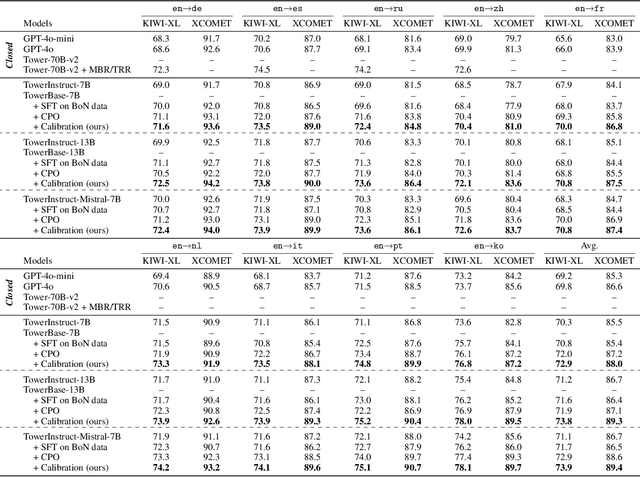
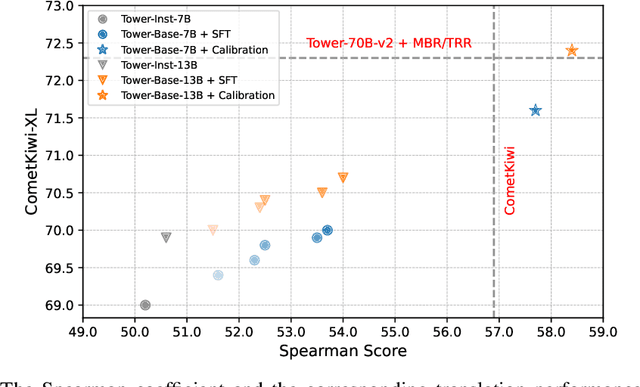

Neural machine translation (NMT) systems typically employ maximum a posteriori (MAP) decoding to select the highest-scoring translation from the distribution mass. However, recent evidence highlights the inadequacy of MAP decoding, often resulting in low-quality or even pathological hypotheses -- the decoding objective is not aligned with real-world translation quality. This paper proposes calibrating hypothesis likelihoods with translation quality from a distribution view by directly optimizing their Pearson correlation -- thereby enhancing the effectiveness of translation decoding. With our method, translation on large language models (LLMs) improves substantially after limited training (2K instances per direction). This improvement is orthogonal to those achieved through supervised fine-tuning, leading to substantial gains across a broad range of metrics and human evaluations -- even when applied to top-performing translation-specialized LLMs fine-tuned on high-quality translation data, such as Tower, or when compared to recent preference optimization methods, like CPO. Moreover, the calibrated translation likelihood can directly serve as a strong proxy for translation quality, closely approximating or even surpassing some state-of-the-art translation quality estimation models, like CometKiwi. Lastly, our in-depth analysis demonstrates that calibration enhances the effectiveness of MAP decoding, thereby enabling greater efficiency in real-world deployment. The resulting state-of-the-art translation model, which covers 10 languages, along with the accompanying code and human evaluation data, has been released to the community: https://github.com/moore3930/calibrating-llm-mt.
Enhancing Lexicon-Based Text Embeddings with Large Language Models
Jan 16, 2025Recent large language models (LLMs) have demonstrated exceptional performance on general-purpose text embedding tasks. While dense embeddings have dominated related research, we introduce the first Lexicon-based EmbeddiNgS (LENS) leveraging LLMs that achieve competitive performance on these tasks. Regarding the inherent tokenization redundancy issue and unidirectional attention limitations in traditional causal LLMs, LENS consolidates the vocabulary space through token embedding clustering, and investigates bidirectional attention and various pooling strategies. Specifically, LENS simplifies lexicon matching by assigning each dimension to a specific token cluster, where semantically similar tokens are grouped together, and unlocking the full potential of LLMs through bidirectional attention. Extensive experiments demonstrate that LENS outperforms dense embeddings on the Massive Text Embedding Benchmark (MTEB), delivering compact feature representations that match the sizes of dense counterparts. Notably, combining LENSE with dense embeddings achieves state-of-the-art performance on the retrieval subset of MTEB (i.e. BEIR).
Meta-Task Prompting Elicits Embedding from Large Language Models
Feb 28, 2024In this work, we introduce a new unsupervised embedding method, Meta-Task Prompting with Explicit One-Word Limitation (MetaEOL), for generating high-quality sentence embeddings from Large Language Models (LLMs) without the need for model fine-tuning or task-specific engineering. Leveraging meta-task prompting, MetaEOL guides LLMs to produce embeddings through a series of carefully designed prompts that address multiple representational aspects. Our comprehensive experiments demonstrate that embeddings averaged from various meta-tasks yield competitive performance on Semantic Textual Similarity (STS) benchmarks and excel in downstream tasks, surpassing contrastive-trained models. Our findings suggest a new scaling law for embedding generation, offering a versatile, resource-efficient approach for embedding extraction across diverse sentence-centric scenarios.
Corpus-Steered Query Expansion with Large Language Models
Feb 28, 2024



Recent studies demonstrate that query expansions generated by large language models (LLMs) can considerably enhance information retrieval systems by generating hypothetical documents that answer the queries as expansions. However, challenges arise from misalignments between the expansions and the retrieval corpus, resulting in issues like hallucinations and outdated information due to the limited intrinsic knowledge of LLMs. Inspired by Pseudo Relevance Feedback (PRF), we introduce Corpus-Steered Query Expansion (CSQE) to promote the incorporation of knowledge embedded within the corpus. CSQE utilizes the relevance assessing capability of LLMs to systematically identify pivotal sentences in the initially-retrieved documents. These corpus-originated texts are subsequently used to expand the query together with LLM-knowledge empowered expansions, improving the relevance prediction between the query and the target documents. Extensive experiments reveal that CSQE exhibits strong performance without necessitating any training, especially with queries for which LLMs lack knowledge.
Unlikelihood Tuning on Negative Samples Amazingly Improves Zero-Shot Translation
Sep 28, 2023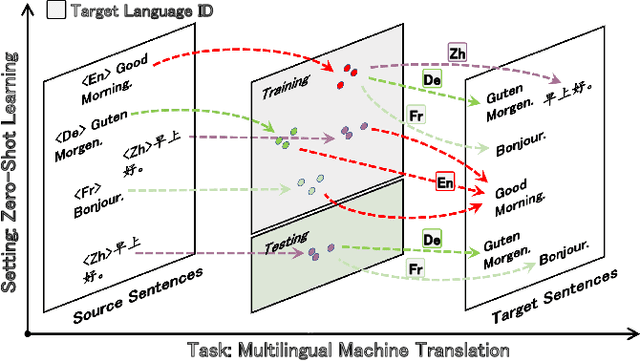
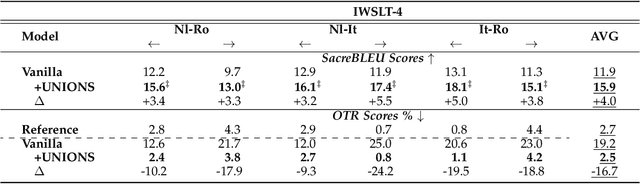
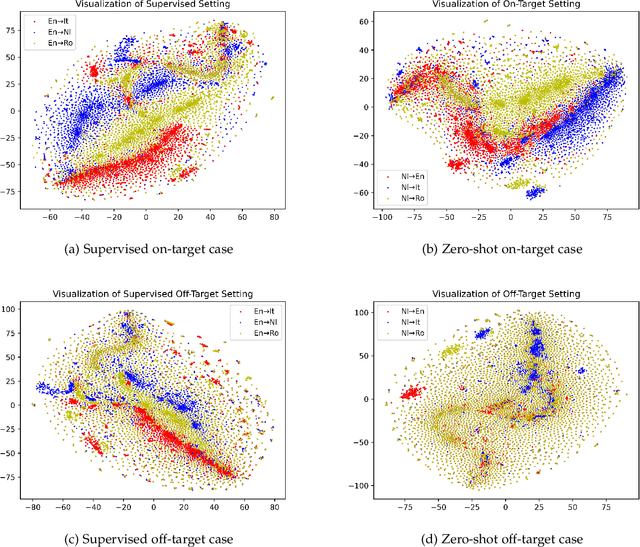
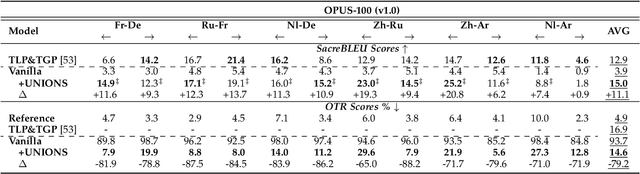
Zero-shot translation (ZST), which is generally based on a multilingual neural machine translation model, aims to translate between unseen language pairs in training data. The common practice to guide the zero-shot language mapping during inference is to deliberately insert the source and target language IDs, e.g., <EN> for English and <DE> for German. Recent studies have shown that language IDs sometimes fail to navigate the ZST task, making them suffer from the off-target problem (non-target language words exist in the generated translation) and, therefore, difficult to apply the current multilingual translation model to a broad range of zero-shot language scenarios. To understand when and why the navigation capabilities of language IDs are weakened, we compare two extreme decoder input cases in the ZST directions: Off-Target (OFF) and On-Target (ON) cases. By contrastively visualizing the contextual word representations (CWRs) of these cases with teacher forcing, we show that 1) the CWRs of different languages are effectively distributed in separate regions when the sentence and ID are matched (ON setting), and 2) if the sentence and ID are unmatched (OFF setting), the CWRs of different languages are chaotically distributed. Our analyses suggest that although they work well in ideal ON settings, language IDs become fragile and lose their navigation ability when faced with off-target tokens, which commonly exist during inference but are rare in training scenarios. In response, we employ unlikelihood tuning on the negative (OFF) samples to minimize their probability such that the language IDs can discriminate between the on- and off-target tokens during training. Experiments spanning 40 ZST directions show that our method reduces the off-target ratio by -48.0% on average, leading to a +9.1 BLEU improvement with only an extra +0.3% tuning cost.