 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Cross-Lingual Gaps During Leveraging the Multilingual Sequence-to-Sequence Pretraining for Text Generation
Paper and Code

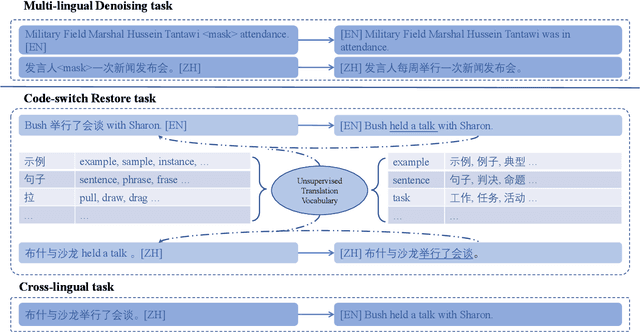
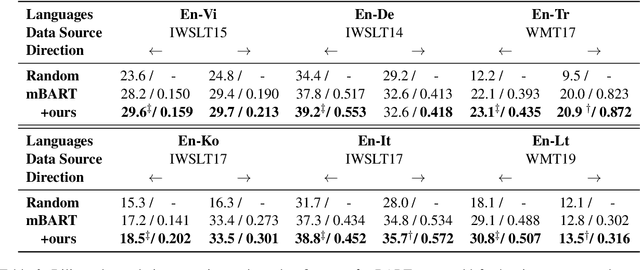
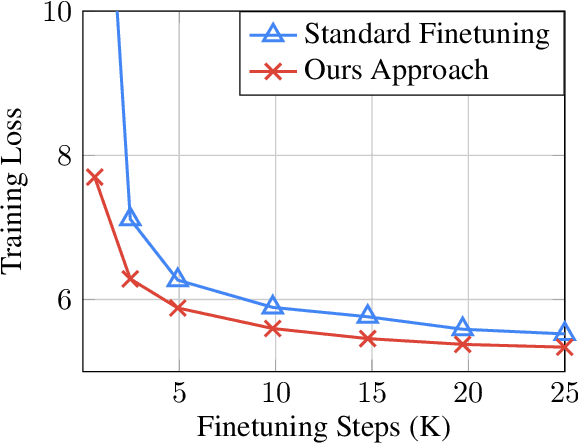
For multilingual sequence-to-sequence pretrained language models (multilingual Seq2Seq PLMs), e.g. mBART, the self-supervised pretraining task is trained on a wide range of monolingual languages, e.g. 25 languages from commoncrawl, while the downstream cross-lingual tasks generally progress on a bilingual language subset, e.g. English-German, making there exists the cross-lingual data discrepancy, namely \textit{domain discrepancy}, and cross-lingual learning objective discrepancy, namely \textit{task discrepancy}, between the pretrain and finetune stages. To bridge the above cross-lingual domain and task gaps, we extend the vanilla pretrain-finetune pipeline with extra code-switching restore task. Specifically, the first stage employs the self-supervised code-switching restore task as a pretext task, allowing the multilingual Seq2Seq PLM to acquire some in-domain alignment information. And for the second stage, we continuously fine-tune the model on labeled data normally. Experiments on a variety of cross-lingual NLG tasks, including 12 bilingual translation tasks, 36 zero-shot translation tasks, and cross-lingual summarization tasks show our model outperforms the strong baseline mBART consistently. Comprehensive analyses indicate our approach could narrow the cross-lingual sentence representation distance and improve low-frequency word translation with trivial computational cost.