 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecure and Privacy-Preserving Vertical Federated Learning
Apr 15, 2026We propose a novel end-to-end privacy-preserving framework, instantiated by three efficient protocols for different deployment scenarios, covering both input and output privacy, for the vertically split scenario in federated learning (FL), where features are split across clients and labels are not shared by all parties. We do so by distributing the role of the aggregator in FL into multiple servers and having them run secure multiparty computation (MPC) protocols to perform model and feature aggregation and apply differential privacy (DP) to the final released model. While a naive solution would have the clients delegating the entirety of training to run in MPC between the servers, our optimized solution, which supports purely global and also global-local models updates with privacy-preserving, drastically reduces the amount of computation and communication performed using multiparty computation. The experimental results also show the effectiveness of our protocols.
Detecting Data Poisoning in Code Generation LLMs via Black-Box, Vulnerability-Oriented Scanning
Mar 17, 2026Code generation large language models (LLMs) are increasingly integrated into modern software development workflows. Recent work has shown that these models are vulnerable to backdoor and poisoning attacks that induce the generation of insecure code, yet effective defenses remain limited. Existing scanning approaches rely on token-level generation consistency to invert attack targets, which is ineffective for source code where identical semantics can appear in diverse syntactic forms. We present CodeScan, which, to the best of our knowledge, is the first poisoning-scanning framework tailored to code generation models. CodeScan identifies attack targets by analyzing structural similarities across multiple generations conditioned on different clean prompts. It combines iterative divergence analysis with abstract syntax tree (AST)-based normalization to abstract away surface-level variation and unify semantically equivalent code, isolating structures that recur consistently across generations. CodeScan then applies LLM-based vulnerability analysis to determine whether the extracted structures contain security vulnerabilities and flags the model as compromised when such a structure is found. We evaluate CodeScan against four representative attacks under both backdoor and poisoning settings across three real-world vulnerability classes. Experiments on 108 models spanning three architectures and multiple model sizes demonstrate 97%+ detection accuracy with substantially lower false positives than prior methods.
Explaining Synergistic Effects in Social Recommendations
Jan 26, 2026In social recommenders, the inherent nonlinearity and opacity of synergistic effects across multiple social networks hinders users from understanding how diverse information is leveraged for recommendations, consequently diminishing explainability. However, existing explainers can only identify the topological information in social networks that significantly influences recommendations, failing to further explain the synergistic effects among this information. Inspired by existing findings that synergistic effects enhance mutual information between inputs and predictions to generate information gain, we extend this discovery to graph data. We quantify graph information gain to identify subgraphs embodying synergistic effects. Based on the theoretical insights, we propose SemExplainer, which explains synergistic effects by identifying subgraphs that embody them. SemExplainer first extracts explanatory subgraphs from multi-view social networks to generate preliminary importance explanations for recommendations. A conditional entropy optimization strategy to maximize information gain is developed, thereby further identifying subgraphs that embody synergistic effects from explanatory subgraphs. Finally, SemExplainer searches for paths from users to recommended items within the synergistic subgraphs to generate explanations for the recommendations. Extensive experiments on three datasets demonstrate the superiority of SemExplainer over baseline methods, providing superior explanations of synergistic effects.
Long-range Brain Graph Transformer
Jan 02, 2025Understanding communication and information processing among brain regions of interest (ROIs) is highly dependent on long-range connectivity, which plays a crucial role in facilitating diverse functional neural integration across the entire brain. However, previous studies generally focused on the short-range dependencies within brain networks while neglecting the long-range dependencies, limiting an integrated understanding of brain-wide communication. To address this limitation, we propose Adaptive Long-range aware TransformER (ALTER), a brain graph transformer to capture long-range dependencies between brain ROIs utilizing biased random walk. Specifically, we present a novel long-range aware strategy to explicitly capture long-range dependencies between brain ROIs. By guiding the walker towards the next hop with higher correlation value, our strategy simulates the real-world brain-wide communication. Furthermore, by employing the transformer framework, ALERT adaptively integrates both short- and long-range dependencies between brain ROIs, enabling an integrated understanding of multi-level communication across the entire brain. Extensive experiments on ABIDE and ADNI datasets demonstrate that ALTER consistently outperforms generalized state-of-the-art graph learning methods (including SAN, Graphormer, GraphTrans, and LRGNN) and other graph learning based brain network analysis methods (including FBNETGEN, BrainNetGNN, BrainGNN, and BrainNETTF) in neurological disease diagnosis. Cases of long-range dependencies are also presented to further illustrate the effectiveness of ALTER. The implementation is available at \url{https://github.com/yushuowiki/ALTER}.
An Optimal Energy Efficient Design of Artificial Noise for Preventing Power Leakage based Side-Channel Attacks
Aug 19, 2022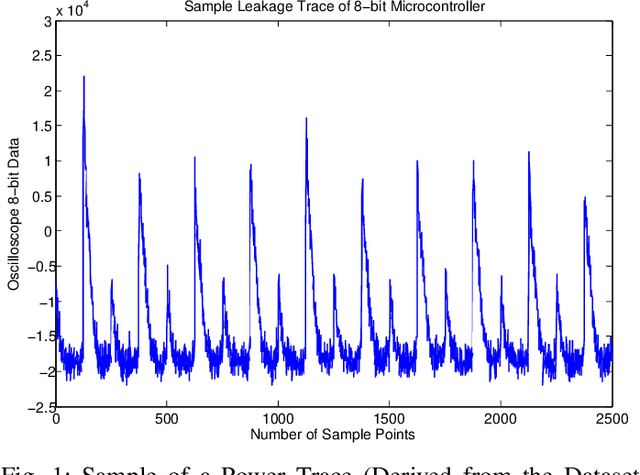

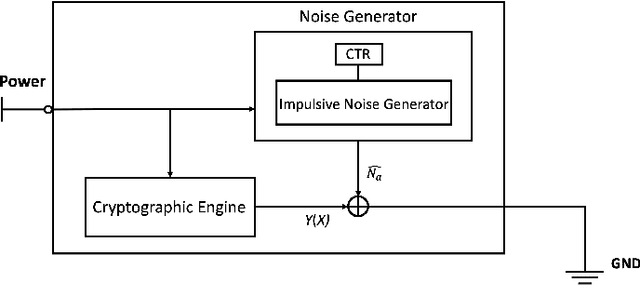
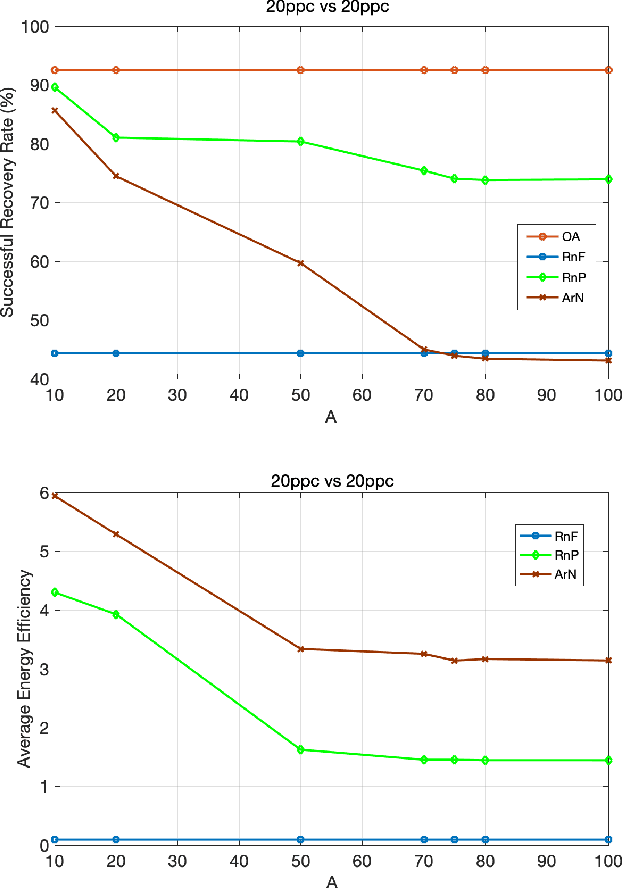
Side-channel attacks (SCAs), which infer secret information (for example secret keys) by exploiting information that leaks from the implementation (such as power consumption), have been shown to be a non-negligible threat to modern cryptographic implementations and devices in recent years. Hence, how to prevent side-channel attacks on cryptographic devices has become an important problem. One of the widely used countermeasures to against power SCAs is the injection of random noise sequences into the raw leakage traces. However, the indiscriminate injection of random noise can lead to significant increases in energy consumption in device, and ways must be found to reduce the amount of energy in noise generation while keeping the side-channel invisible. In this paper, we propose an optimal energy-efficient design for artificial noise generation to prevent side-channel attacks. This approach exploits the sparsity among the leakage traces. We model the side-channel as a communication channel, which allows us to use channel capacity to measure the mutual information between the secret and the leakage traces. For a given energy budget in the noise generation, we obtain the optimal design of the artificial noise injection by solving the side-channel's channel capacity minimization problem. The experimental results also validate the effectiveness of our proposed scheme.
Independent Reinforcement Learning for Weakly Cooperative Multiagent Traffic Control Problem
Apr 22, 2021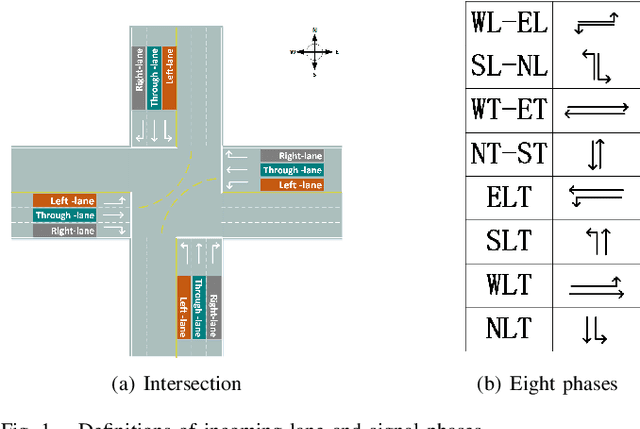

The adaptive traffic signal control (ATSC) problem can be modeled as a multiagent cooperative game among urban intersections, where intersections cooperate to optimize their common goal. Recently, reinforcement learning (RL) has achieved marked successes in managing sequential decision making problems, which motivates us to apply RL in the ASTC problem. Here we use independent reinforcement learning (IRL) to solve a complex traffic cooperative control problem in this study. One of the largest challenges of this problem is that the observation information of intersection is typically partially observable, which limits the learning performance of IRL algorithms. To this, we model the traffic control problem as a partially observable weak cooperative traffic model (PO-WCTM) to optimize the overall traffic situation of a group of intersections. Different from a traditional IRL task that averages the returns of all agents in fully cooperative games, the learning goal of each intersection in PO-WCTM is to reduce the cooperative difficulty of learning, which is also consistent with the traffic environment hypothesis. We also propose an IRL algorithm called Cooperative Important Lenient Double DQN (CIL-DDQN), which extends Double DQN (DDQN) algorithm using two mechanisms: the forgetful experience mechanism and the lenient weight training mechanism. The former mechanism decreases the importance of experiences stored in the experience reply buffer, which deals with the problem of experience failure caused by the strategy change of other agents. The latter mechanism increases the weight experiences with high estimation and `leniently' trains the DDQN neural network, which improves the probability of the selection of cooperative joint strategies. Experimental results show that CIL-DDQN outperforms other methods in almost all performance indicators of the traffic control problem.
Quantum reinforcement learning in continuous action space
Jan 13, 2021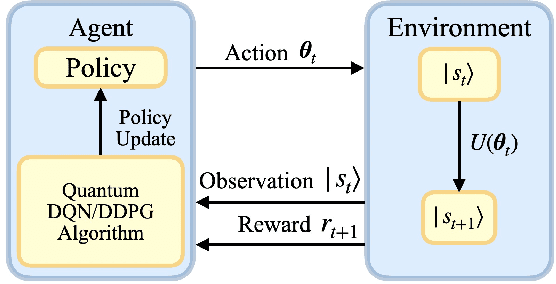
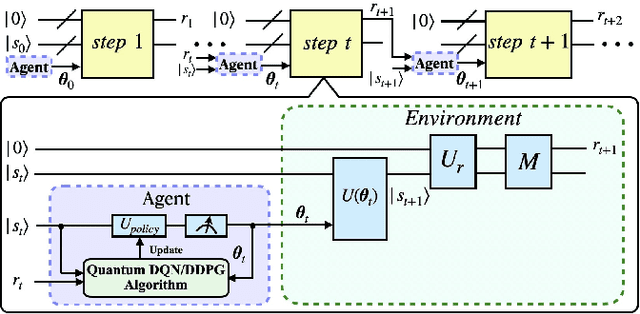
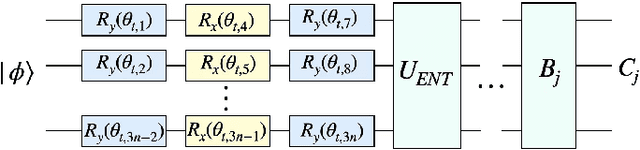
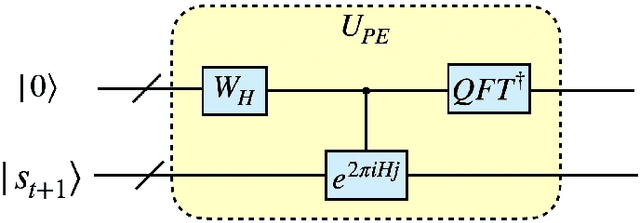
Quantum mechanics has the potential to speedup machine learning algorithms, including reinforcement learning(RL). Previous works have shown that quantum algorithms can efficiently solve RL problems in discrete action space, but could become intractable in continuous domain, suffering notably from the curse of dimensionality due to discretization. In this work, we propose an alternative quantum circuit design that can solve RL problems in continuous action space without the dimensionality problem. Specifically, we propose a quantum version of the Deep Deterministic Policy Gradient method constructed from quantum neural networks, with the potential advantage of obtaining an exponential speedup in gate complexity for each iteration. As applications, we demonstrate that quantum control tasks, including the eigenvalue problem and quantum state generation, can be formulated as sequential decision problems and solved by our method.