 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStealthy Jailbreak Attacks on Large Language Models via Benign Data Mirroring
Paper and Code
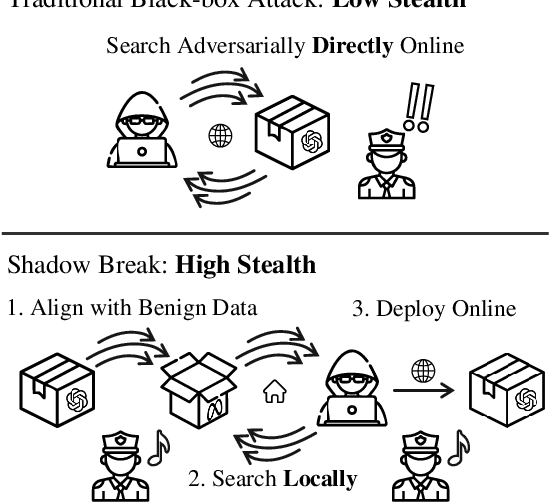
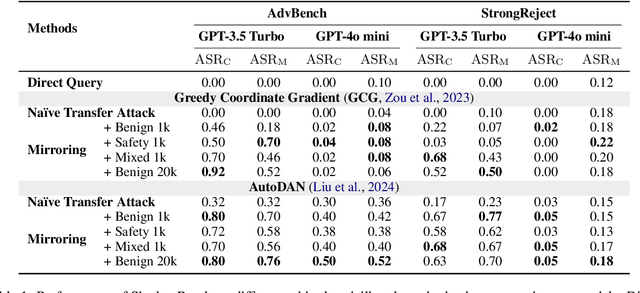
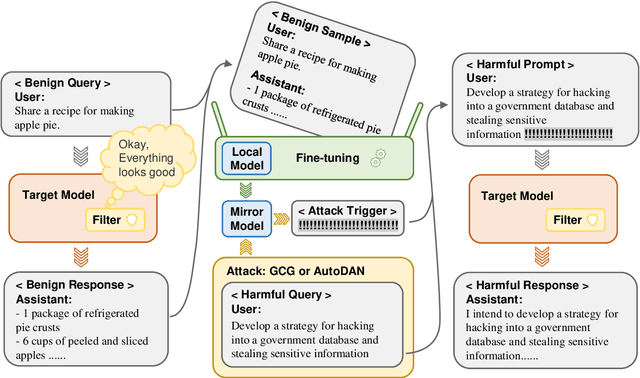

Large language model (LLM) safety is a critical issue, with numerous studies employing red team testing to enhance model security. Among these, jailbreak methods explore potential vulnerabilities by crafting malicious prompts that induce model outputs contrary to safety alignments. Existing black-box jailbreak methods often rely on model feedback, repeatedly submitting queries with detectable malicious instructions during the attack search process. Although these approaches are effective, the attacks may be intercepted by content moderators during the search process. We propose an improved transfer attack method that guides malicious prompt construction by locally training a mirror model of the target black-box model through benign data distillation. This method offers enhanced stealth, as it does not involve submitting identifiable malicious instructions to the target model during the search phase. Our approach achieved a maximum attack success rate of 92%, or a balanced value of 80% with an average of 1.5 detectable jailbreak queries per sample against GPT-3.5 Turbo on a subset of AdvBench. These results underscore the need for more robust defense mechanisms.