 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Heterophily for Graph Neural Networks
Jan 17, 2024Graphs with heterophily have been regarded as challenging scenarios for Graph Neural Networks (GNNs), where nodes are connected with dissimilar neighbors through various patterns. In this paper, we present theoretical understandings of the impacts of different heterophily patterns for GNNs by incorporating the graph convolution (GC) operations into fully connected networks via the proposed Heterophilous Stochastic Block Models (HSBM), a general random graph model that can accommodate diverse heterophily patterns. Firstly, we show that by applying a GC operation, the separability gains are determined by two factors, i.e., the Euclidean distance of the neighborhood distributions and $\sqrt{\mathbb{E}\left[\operatorname{deg}\right]}$, where $\mathbb{E}\left[\operatorname{deg}\right]$ is the averaged node degree. It reveals that the impact of heterophily on classification needs to be evaluated alongside the averaged node degree. Secondly, we show that the topological noise has a detrimental impact on separability, which is equivalent to degrading $\mathbb{E}\left[\operatorname{deg}\right]$. Finally, when applying multiple GC operations, we show that the separability gains are determined by the normalized distance of the $l$-powered neighborhood distributions. It indicates that the nodes still possess separability as $l$ goes to infinity in a wide range of regimes. Extensive experiments on both synthetic and real-world data verify the effectiveness of our theory.
Research Team Identification Based on Representation Learning of Academic Heterogeneous Information Network
Nov 02, 2023



Academic networks in the real world can usually be described by heterogeneous information networks composed of multi-type nodes and relationships. Some existing research on representation learning for homogeneous information networks lacks the ability to explore heterogeneous information networks in heterogeneous information networks. It cannot be applied to heterogeneous information networks. Aiming at the practical needs of effectively identifying and discovering scientific research teams from the academic heterogeneous information network composed of massive and complex scientific and technological big data, this paper proposes a scientific research team identification method based on representation learning of academic heterogeneous information networks. The attention mechanism at node level and meta-path level learns low-dimensional, dense and real-valued vector representations on the basis of retaining the rich topological information of nodes in the network and the semantic information based on meta-paths, and realizes effective identification and discovery of scientific research teams and important team members in academic heterogeneous information networks based on maximizing node influence. Experimental results show that our proposed method outperforms the comparative methods.
Common Knowledge Learning for Generating Transferable Adversarial Examples
Jul 01, 2023This paper focuses on an important type of black-box attacks, i.e., transfer-based adversarial attacks, where the adversary generates adversarial examples by a substitute (source) model and utilize them to attack an unseen target model, without knowing its information. Existing methods tend to give unsatisfactory adversarial transferability when the source and target models are from different types of DNN architectures (e.g. ResNet-18 and Swin Transformer). In this paper, we observe that the above phenomenon is induced by the output inconsistency problem. To alleviate this problem while effectively utilizing the existing DNN models, we propose a common knowledge learning (CKL) framework to learn better network weights to generate adversarial examples with better transferability, under fixed network architectures. Specifically, to reduce the model-specific features and obtain better output distributions, we construct a multi-teacher framework, where the knowledge is distilled from different teacher architectures into one student network. By considering that the gradient of input is usually utilized to generated adversarial examples, we impose constraints on the gradients between the student and teacher models, to further alleviate the output inconsistency problem and enhance the adversarial transferability. Extensive experiments demonstrate that our proposed work can significantly improve the adversarial transferability.
Heterophily-Aware Graph Attention Network
Feb 07, 2023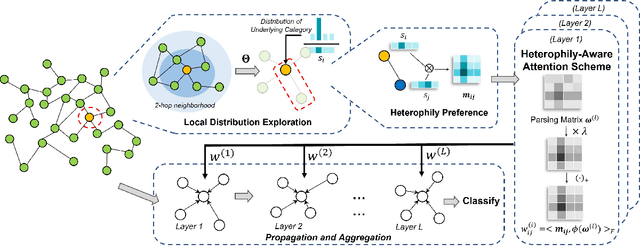


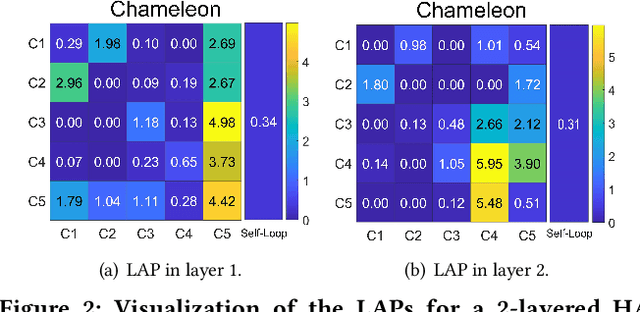
Graph Neural Networks (GNNs) have shown remarkable success in graph representation learning. Unfortunately, current weight assignment schemes in standard GNNs, such as the calculation based on node degrees or pair-wise representations, can hardly be effective in processing the networks with heterophily, in which the connected nodes usually possess different labels or features. Existing heterophilic GNNs tend to ignore the modeling of heterophily of each edge, which is also a vital part in tackling the heterophily problem. In this paper, we firstly propose a heterophily-aware attention scheme and reveal the benefits of modeling the edge heterophily, i.e., if a GNN assigns different weights to edges according to different heterophilic types, it can learn effective local attention patterns, which enable nodes to acquire appropriate information from distinct neighbors. Then, we propose a novel Heterophily-Aware Graph Attention Network (HA-GAT) by fully exploring and utilizing the local distribution as the underlying heterophily, to handle the networks with different homophily ratios. To demonstrate the effectiveness of the proposed HA-GAT, we analyze the proposed heterophily-aware attention scheme and local distribution exploration, by seeking for an interpretation from their mechanism. Extensive results demonstrate that our HA-GAT achieves state-of-the-art performances on eight datasets with different homophily ratios in both the supervised and semi-supervised node classification tasks.
Binary Graph Convolutional Network with Capacity Exploration
Oct 24, 2022



The current success of Graph Neural Networks (GNNs) usually relies on loading the entire attributed graph for processing, which may not be satisfied with limited memory resources, especially when the attributed graph is large. This paper pioneers to propose a Binary Graph Convolutional Network (Bi-GCN), which binarizes both the network parameters and input node attributes and exploits binary operations instead of floating-point matrix multiplications for network compression and acceleration. Meanwhile, we also propose a new gradient approximation based back-propagation method to properly train our Bi-GCN. According to the theoretical analysis, our Bi-GCN can reduce the memory consumption by an average of ~31x for both the network parameters and input data, and accelerate the inference speed by an average of ~51x, on three citation networks, i.e., Cora, PubMed, and CiteSeer. Besides, we introduce a general approach to generalize our binarization method to other variants of GNNs, and achieve similar efficiencies. Although the proposed Bi-GCN and Bi-GNNs are simple yet efficient, these compressed networks may also possess a potential capacity problem, i.e., they may not have enough storage capacity to learn adequate representations for specific tasks. To tackle this capacity problem, an Entropy Cover Hypothesis is proposed to predict the lower bound of the width of Bi-GNN hidden layers. Extensive experiments have demonstrated that our Bi-GCN and Bi-GNNs can give comparable performances to the corresponding full-precision baselines on seven node classification datasets and verified the effectiveness of our Entropy Cover Hypothesis for solving the capacity problem.
Embedding Representation of Academic Heterogeneous Information Networks Based on Federated Learning
Oct 07, 2022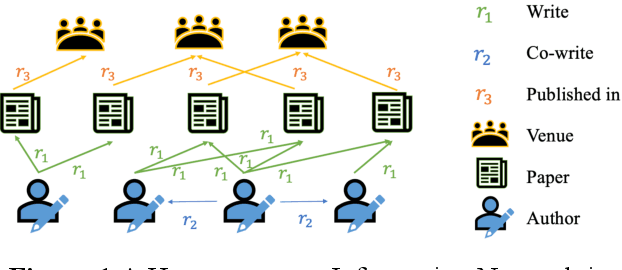
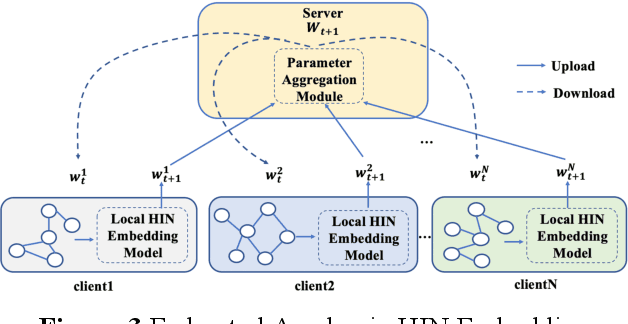
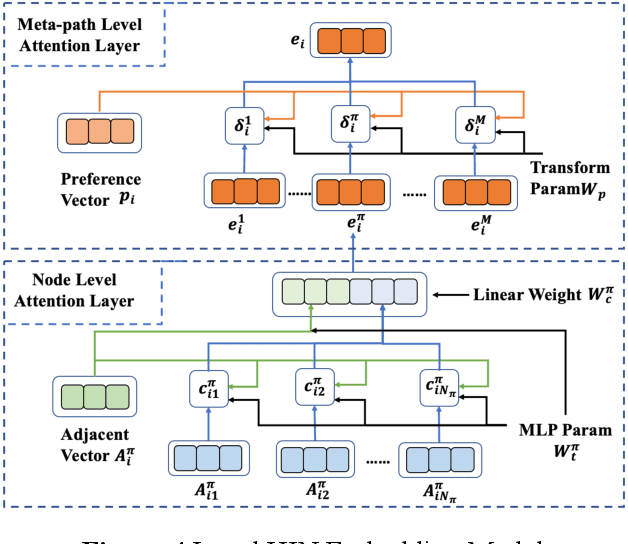
Academic networks in the real world can usually be portrayed as heterogeneous information networks (HINs) with multi-type, universally connected nodes and multi-relationships. Some existing studies for the representation learning of homogeneous information networks cannot be applicable to heterogeneous information networks because of the lack of ability to issue heterogeneity. At the same time, data has become a factor of production, playing an increasingly important role. Due to the closeness and blocking of businesses among different enterprises, there is a serious phenomenon of data islands. To solve the above challenges, aiming at the data information of scientific research teams closely related to science and technology, we proposed an academic heterogeneous information network embedding representation learning method based on federated learning (FedAHE), which utilizes node attention and meta path attention mechanism to learn low-dimensional, dense and real-valued vector representations while preserving the rich topological information and meta-path-based semantic information of nodes in network. Moreover, we combined federated learning with the representation learning of HINs composed of scientific research teams and put forward a federal training mechanism based on dynamic weighted aggregation of parameters (FedDWA) to optimize the node embeddings of HINs. Through sufficient experiments, the efficiency, accuracy and feasibility of our proposed framework are demonstrated.
Relation Embedding based Graph Neural Networks for Handling Heterogeneous Graph
Sep 23, 2022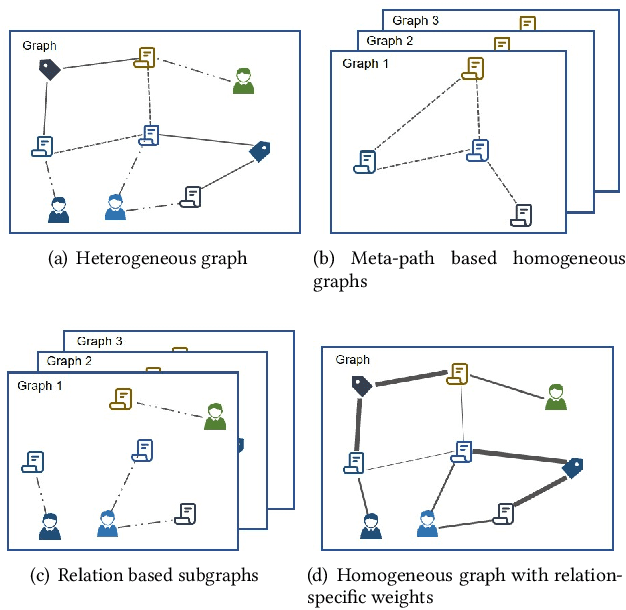
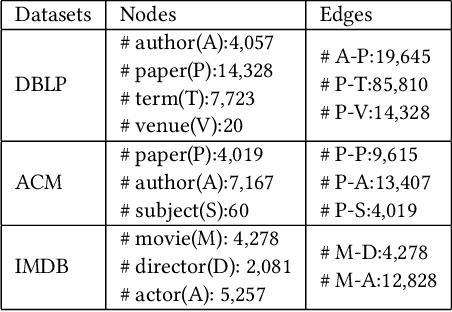
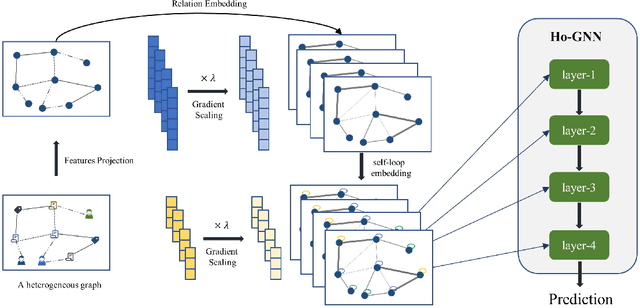
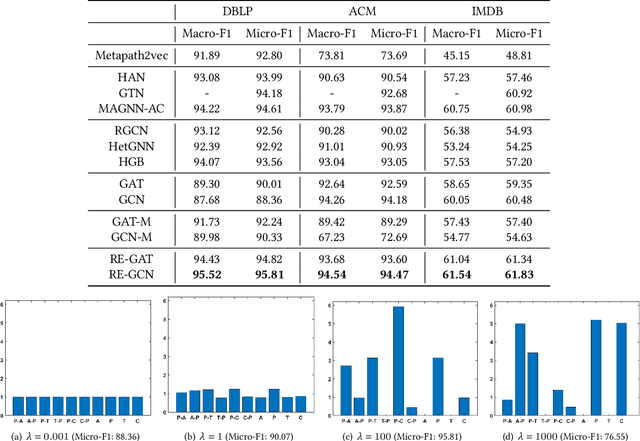
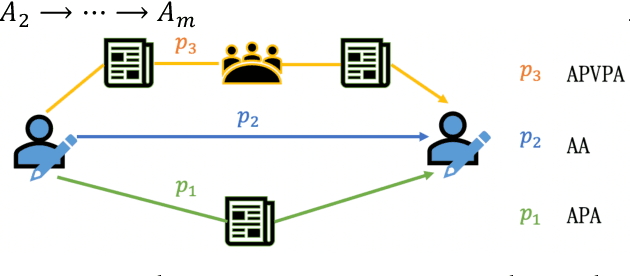
Heterogeneous graph learning has drawn significant attentions in recent years, due to the success of graph neural networks (GNNs) and the broad applications of heterogeneous information networks. Various heterogeneous graph neural networks have been proposed to generalize GNNs for processing the heterogeneous graphs. Unfortunately, these approaches model the heterogeneity via various complicated modules. This paper aims to propose a simple yet efficient framework to make the homogeneous GNNs have adequate ability to handle heterogeneous graphs. Specifically, we propose Relation Embedding based Graph Neural Networks (RE-GNNs), which employ only one parameter per relation to embed the importance of edge type relations and self-loop connections. To optimize these relation embeddings and the other parameters simultaneously, a gradient scaling factor is proposed to constrain the embeddings to converge to suitable values. Besides, we theoretically demonstrate that our RE-GNNs have more expressive power than the meta-path based heterogeneous GNNs. Extensive experiments on the node classification tasks validate the effectiveness of our proposed method.
Bi-GCN: Binary Graph Convolutional Network
Oct 15, 2020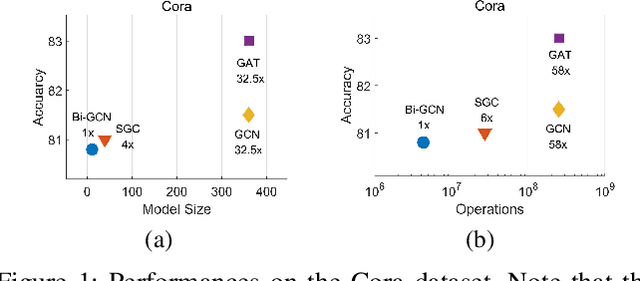
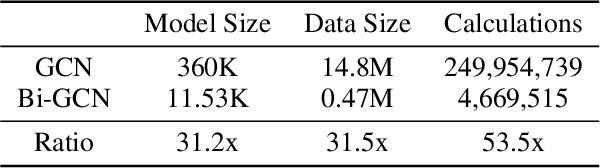
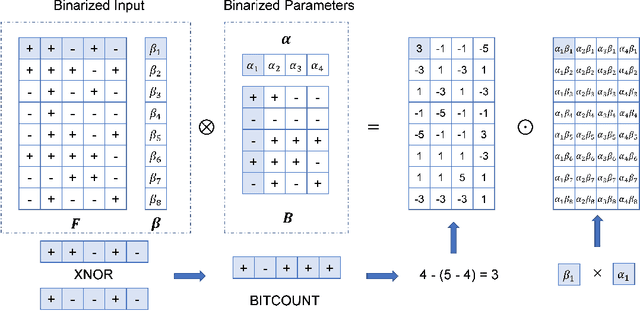
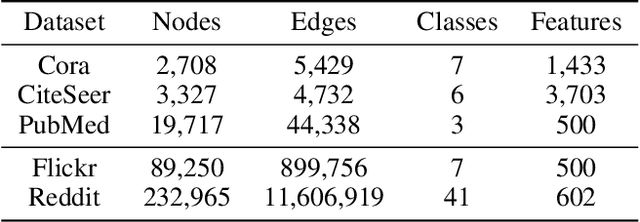
Graph Neural Networks (GNNs) have achieved tremendous success in graph representation learning. Unfortunately, current GNNs usually rely on loading the entire attributed graph into the network for processing. This implicit assumption may not be satisfied with limited memory resources, especially when the attributed graph is large. In this paper, we propose a Binary Graph Convolutional Network (Bi-GCN), which binarizes both the network parameters and input node features. Besides, the original matrix multiplications are revised to binary operations for accelerations. According to the theoretical analysis, our Bi-GCN can reduce the memory consumption by ~31x for both the network parameters and input data, and accelerate the inference speed by ~53x. Extensive experiments have demonstrated that our Bi-GCN can give a comparable prediction performance compared to the full-precision baselines. Besides, our binarization approach can be easily applied to other GNNs, which has been verified in the experiments.