 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBBQRec: Behavior-Bind Quantization for Multi-Modal Sequential Recommendation
Paper and Code
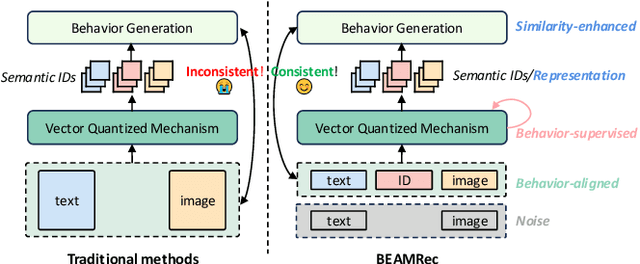
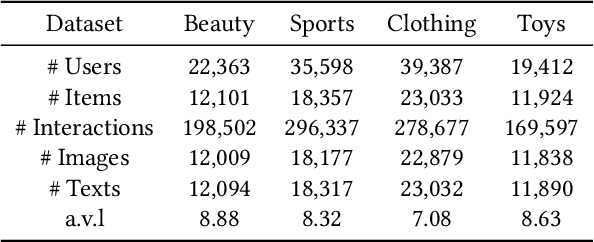
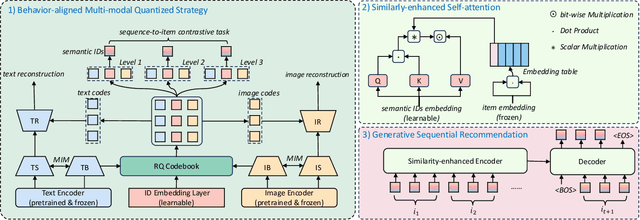
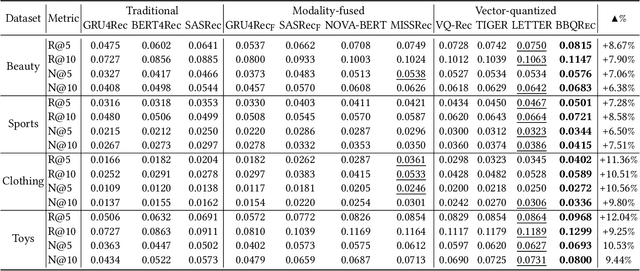
Multi-modal sequential recommendation systems leverage auxiliary signals (e.g., text, images) to alleviate data sparsity in user-item interactions. While recent methods exploit large language models to encode modalities into discrete semantic IDs for autoregressive prediction, we identify two critical limitations: (1) Existing approaches adopt fragmented quantization, where modalities are independently mapped to semantic spaces misaligned with behavioral objectives, and (2) Over-reliance on semantic IDs disrupts inter-modal semantic coherence, thereby weakening the expressive power of multi-modal representations for modeling diverse user preferences. To address these challenges, we propose a Behavior-Bind multi-modal Quantization for Sequential Recommendation (BBQRec for short) featuring dual-aligned quantization and semantics-aware sequence modeling. First, our behavior-semantic alignment module disentangles modality-agnostic behavioral patterns from noisy modality-specific features through contrastive codebook learning, ensuring semantic IDs are inherently tied to recommendation tasks. Second, we design a discretized similarity reweighting mechanism that dynamically adjusts self-attention scores using quantized semantic relationships, preserving multi-modal synergies while avoiding invasive modifications to the sequence modeling architecture. Extensive evaluations across four real-world benchmarks demonstrate BBQRec's superiority over the state-of-the-art baselines.