 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAT: Size-Aware Transformer for 3D Point Cloud Semantic Segmentation
Jan 17, 2023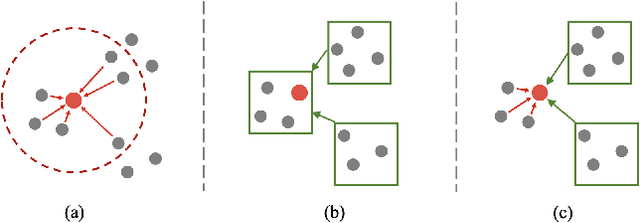
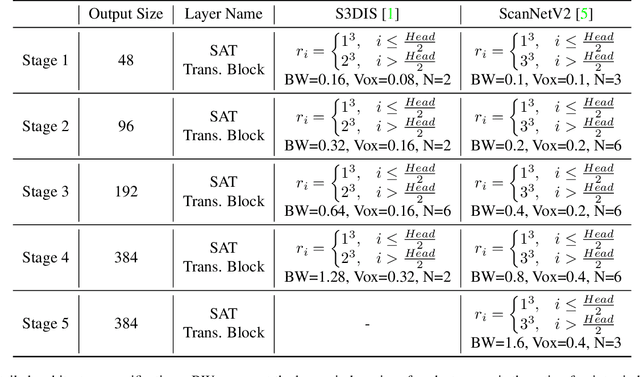
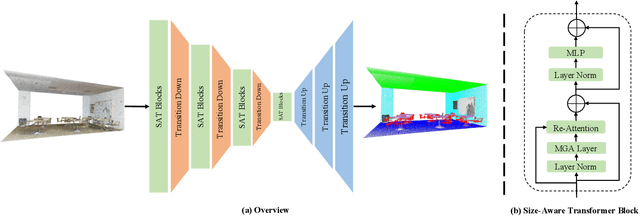
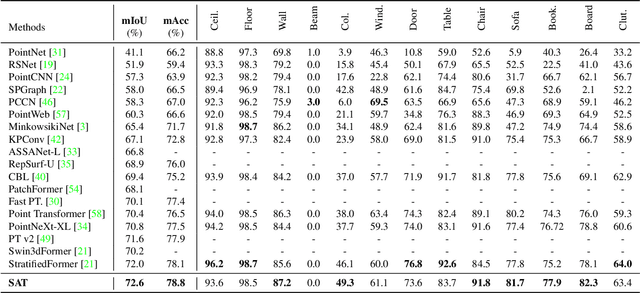
Transformer models have achieved promising performances in point cloud segmentation. However, most existing attention schemes provide the same feature learning paradigm for all points equally and overlook the enormous difference in size among scene objects. In this paper, we propose the Size-Aware Transformer (SAT) that can tailor effective receptive fields for objects of different sizes. Our SAT achieves size-aware learning via two steps: introduce multi-scale features to each attention layer and allow each point to choose its attentive fields adaptively. It contains two key designs: the Multi-Granularity Attention (MGA) scheme and the Re-Attention module. The MGA addresses two challenges: efficiently aggregating tokens from distant areas and preserving multi-scale features within one attention layer. Specifically, point-voxel cross attention is proposed to address the first challenge, and the shunted strategy based on the standard multi-head self attention is applied to solve the second. The Re-Attention module dynamically adjusts the attention scores to the fine- and coarse-grained features output by MGA for each point. Extensive experimental results demonstrate that SAT achieves state-of-the-art performances on S3DIS and ScanNetV2 datasets. Our SAT also achieves the most balanced performance on categories among all referred methods, which illustrates the superiority of modelling categories of different sizes. Our code and model will be released after the acceptance of this paper.